Avances en la comprensión de documentos
Avances en documentos
Publicado por Sandeep Tata, Ingeniero de Software, Google Research, Equipo Athena
En los últimos años se ha visto un rápido progreso en sistemas que pueden procesar automáticamente documentos empresariales complejos y convertirlos en objetos estructurados. Un sistema que pueda extraer automáticamente datos de documentos, como recibos, cotizaciones de seguros y estados financieros, tiene el potencial de mejorar drásticamente la eficiencia de los flujos de trabajo empresariales al evitar el trabajo manual propenso a errores. Modelos recientes, basados en la arquitectura Transformer, han mostrado impresionantes mejoras en precisión. También se están utilizando modelos más grandes, como PaLM 2, para agilizar aún más estos flujos de trabajo empresariales. Sin embargo, los conjuntos de datos utilizados en la literatura académica no capturan los desafíos vistos en casos de uso del mundo real. En consecuencia, los puntos de referencia académicos informan una alta precisión del modelo, pero estos mismos modelos no funcionan bien cuando se utilizan en aplicaciones complejas del mundo real.
En “VRDU: Un punto de referencia para la comprensión de documentos ricos en visualización”, presentado en KDD 2023, anunciamos el lanzamiento del nuevo conjunto de datos de Comprensión de Documentos Ricos en Visualización (VRDU) que tiene como objetivo cerrar esta brecha y ayudar a los investigadores a realizar un mejor seguimiento del progreso en las tareas de comprensión de documentos. Enumeramos cinco requisitos para un buen punto de referencia de comprensión de documentos, basados en los tipos de documentos del mundo real para los que los modelos de comprensión de documentos se utilizan con frecuencia. Luego, describimos cómo la mayoría de los conjuntos de datos utilizados actualmente por la comunidad de investigación no cumplen uno o más de estos requisitos, mientras que VRDU cumple todos ellos. Estamos emocionados de anunciar el lanzamiento público del conjunto de datos VRDU y el código de evaluación bajo una licencia Creative Commons.
Requisitos del punto de referencia
En primer lugar, comparamos la precisión del modelo de última generación (por ejemplo, con FormNet y LayoutLMv2) en casos de uso del mundo real con los puntos de referencia académicos (por ejemplo, FUNSD, CORD, SROIE). Observamos que los modelos de última generación no coincidían con los resultados de los puntos de referencia académicos y ofrecían una precisión mucho menor en el mundo real. A continuación, comparamos los conjuntos de datos típicos para los cuales los modelos de comprensión de documentos se utilizan con frecuencia con los puntos de referencia académicos e identificamos cinco requisitos del conjunto de datos que permiten capturar mejor la complejidad de las aplicaciones del mundo real:
- Gran Tecnología y IA Generativa ¿Controlará la Gran Tecnología la IA Generativa?
- La IA generativa puede cambiar el mundo, pero solo si la infraestructura de datos se mantiene al día
- ¿Qué es la calidad de los datos?
- Esquema Rico: En la práctica, vemos una amplia variedad de esquemas ricos para la extracción estructurada. Las entidades tienen diferentes tipos de datos (numéricos, cadenas, fechas, etc.) que pueden ser obligatorios, opcionales o repetidos en un solo documento, e incluso pueden estar anidados. Las tareas de extracción sobre esquemas planos simples como (encabezado, pregunta, respuesta) no reflejan los problemas típicos encontrados en la práctica.
- Documentos con Diseño Rico: Los documentos deben tener elementos de diseño complejos. Los desafíos en entornos prácticos provienen del hecho de que los documentos pueden contener tablas, pares clave-valor, cambiar entre diseños de una y dos columnas, tener tamaños de fuente variables para diferentes secciones, incluir imágenes con leyendas e incluso notas al pie. Contrasta esto con los conjuntos de datos donde la mayoría de los documentos están organizados en oraciones, párrafos y capítulos con encabezados de sección, los tipos de documentos que suelen ser el enfoque de la literatura clásica de procesamiento de lenguaje natural en entradas largas.
- Plantillas Diversas: Un punto de referencia debe incluir diferentes diseños o plantillas estructurales. Es trivial para un modelo de alta capacidad extraer de una plantilla particular memorizando la estructura. Sin embargo, en la práctica, se necesita poder generalizar a nuevas plantillas/diseños, una habilidad que el conjunto de datos de entrenamiento-prueba en un punto de referencia debe medir.
- OCR de Alta Calidad: Los documentos deben tener resultados de Reconocimiento Óptico de Caracteres (OCR) de alta calidad. Nuestro objetivo con este punto de referencia es centrarnos en la tarea de VRDU en sí y excluir la variabilidad que se produce por la elección del motor OCR.
- Anotación a Nivel de Token: Los documentos deben contener anotaciones de verdad de referencia que se pueden relacionar con el texto de entrada correspondiente, de modo que cada token se pueda anotar como parte de la entidad correspondiente. Esto contrasta con simplemente proporcionar el texto del valor a extraer para la entidad. Esto es fundamental para generar datos de entrenamiento limpios donde no tengamos que preocuparnos por coincidencias incidentales con el valor dado. Por ejemplo, en algunos recibos, el campo ‘total antes de impuestos’ puede tener el mismo valor que el campo ‘total’ si el monto de impuestos es cero. Tener anotaciones a nivel de token evita que generemos datos de entrenamiento donde ambas instancias del valor coincidente se marquen como verdaderas para el campo ‘total’, lo que produce ejemplos ruidosos.
 |
Conjuntos de datos y tareas de VRDU
El conjunto de datos VRDU es una combinación de dos conjuntos de datos disponibles públicamente, Formularios de Registro y Formularios de Compra de Anuncios. Estos conjuntos de datos proporcionan ejemplos representativos de casos de uso del mundo real y cumplen con los cinco requisitos de referencia descritos anteriormente.
El conjunto de datos de Formularios de Compra de Anuncios consta de 641 documentos con detalles de anuncios políticos. Cada documento es una factura o recibo firmado por una estación de televisión y un grupo de campaña. Los documentos utilizan tablas, columnas múltiples y pares clave-valor para registrar la información del anuncio, como el nombre del producto, las fechas de emisión, el precio total y la fecha y hora de lanzamiento.
El conjunto de datos de Formularios de Registro consta de 1,915 documentos con información sobre agentes extranjeros que se registran ante el gobierno de Estados Unidos. Cada documento registra información esencial sobre agentes extranjeros involucrados en actividades que requieren divulgación pública. Los contenidos incluyen el nombre del registrante, la dirección de las oficinas relacionadas, el propósito de las actividades y otros detalles.
Reunimos una muestra aleatoria de documentos de los sitios públicos de la Comisión Federal de Comunicaciones (FCC) y la Ley de Registro de Agentes Extranjeros (FARA) y convertimos las imágenes a texto utilizando OCR de Google Cloud. Descartamos un pequeño número de documentos que tenían varias páginas y el procesamiento no se completó en menos de dos minutos. Esto también nos permitió evitar enviar documentos muy largos para su anotación manual, una tarea que puede llevar más de una hora para un solo documento. Luego, definimos el esquema y las instrucciones de etiquetado correspondientes para un equipo de anotadores con experiencia en tareas de etiquetado de documentos.
También se proporcionó a los anotadores algunos documentos de muestra etiquetados que etiquetamos nosotros mismos. La tarea requería que los anotadores examinaran cada documento, dibujaran un cuadro delimitador alrededor de cada aparición de una entidad del esquema para cada documento y asociaran ese cuadro delimitador con la entidad objetivo. Después de la primera ronda de etiquetado, se asignó a un grupo de expertos para revisar los resultados. Los resultados corregidos se incluyen en el conjunto de datos VRDU publicado. Consulte el artículo para obtener más detalles sobre el protocolo de etiquetado y el esquema para cada conjunto de datos.
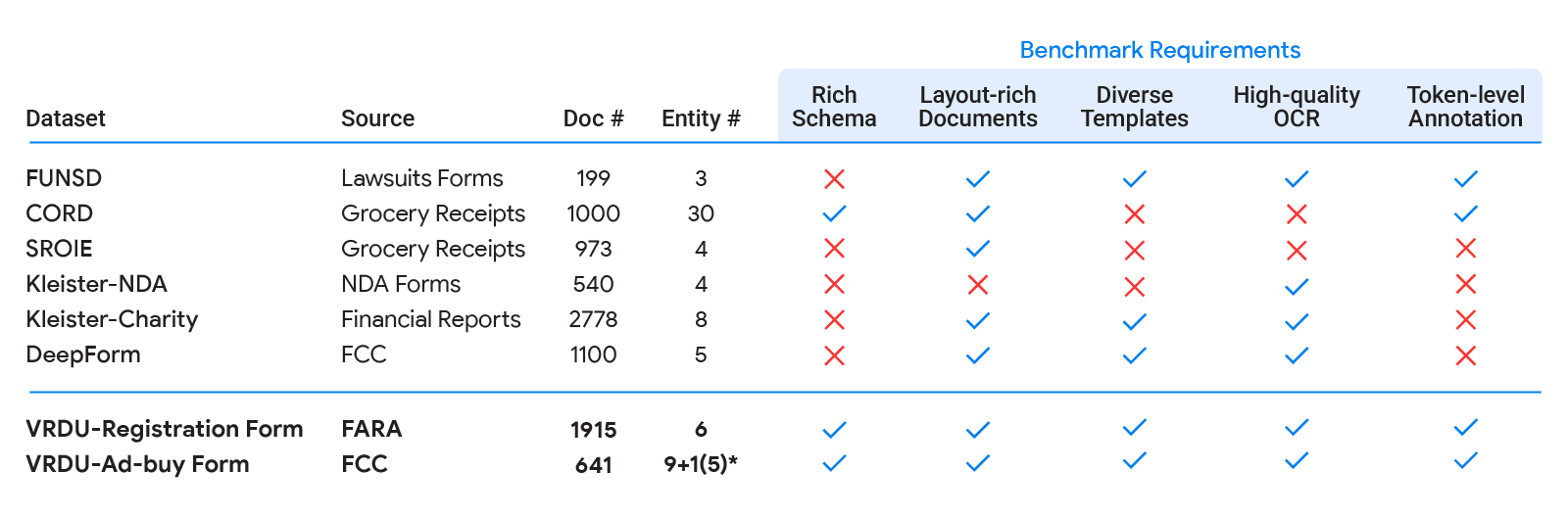 |
| Los conjuntos de datos académicos existentes (FUNSD, CORD, SROIE, Kleister-NDA, Kleister-Charity, DeepForm) no cumplen uno o más de los cinco requisitos que identificamos para un buen conjunto de datos de comprensión de documentos. VRDU cumple todos ellos. Consulte nuestro artículo para obtener antecedentes sobre cada uno de estos conjuntos de datos y una discusión sobre cómo no cumplen uno o más de los requisitos. |
Construimos cuatro conjuntos de entrenamiento de modelos diferentes con 10, 50, 100 y 200 ejemplos respectivamente. Luego, evaluamos los conjuntos de datos VRDU utilizando tres tareas (descritas a continuación): (1) Aprendizaje de una sola plantilla, (2) Aprendizaje de plantillas mixtas y (3) Aprendizaje de plantillas no vistas. Para cada una de estas tareas, incluimos 300 documentos en el conjunto de pruebas. Evaluamos los modelos utilizando la puntuación F1 en el conjunto de pruebas.
- Aprendizaje de una sola plantilla (STL): Este es el escenario más simple donde los conjuntos de entrenamiento, prueba y validación solo contienen una plantilla única. Esta tarea simple está diseñada para evaluar la capacidad de un modelo para manejar una plantilla fija. Naturalmente, esperamos puntuaciones F1 muy altas (0.90+) para esta tarea.
- Aprendizaje de plantillas mixtas (MTL): Esta tarea es similar a la tarea que la mayoría de los documentos relacionados utilizan: los conjuntos de entrenamiento, prueba y validación contienen todos documentos pertenecientes al mismo conjunto de plantillas. Muestreamos documentos al azar de los conjuntos de datos y construimos las divisiones para asegurarnos de que la distribución de cada plantilla no se modifique durante el muestreo.
- Aprendizaje de plantillas no vistas (UTL): Esta es la configuración más desafiante, donde evaluamos si el modelo puede generalizar a plantillas no vistas. Por ejemplo, en el conjunto de datos de Formularios de Registro, entrenamos el modelo con dos de las tres plantillas y probamos el modelo con la restante. Los documentos en los conjuntos de entrenamiento, prueba y validación se extraen de conjuntos de plantillas disjuntas. Hasta donde sabemos, los conjuntos de datos y benchmarks anteriores no proporcionan explícitamente una tarea diseñada para evaluar la capacidad del modelo para generalizar a plantillas no vistas durante el entrenamiento.
El objetivo es poder evaluar los modelos en cuanto a su eficiencia de datos. En nuestro artículo, comparamos dos modelos recientes utilizando las tareas de STL, MTL y UTL y realizamos tres observaciones. Primero, a diferencia de otros benchmarks, VRDU es desafiante y muestra que los modelos tienen mucho margen de mejora. Segundo, mostramos que el rendimiento en pocos datos para incluso modelos de última generación es sorprendentemente bajo, incluso los mejores modelos resultan en una puntuación F1 de menos de 0.60. Tercero, mostramos que los modelos tienen dificultades para lidiar con campos repetidos estructurados y tienen un rendimiento particularmente pobre en ellos.
Conclusión
Lanzamos el nuevo conjunto de datos de comprensión de documentos visualmente ricos (VRDU) que ayuda a los investigadores a realizar un seguimiento más preciso del progreso en las tareas de comprensión de documentos. Describimos por qué VRDU refleja mejor los desafíos prácticos en este ámbito. También presentamos experimentos que demuestran que las tareas de VRDU son desafiantes y que los modelos recientes tienen un margen significativo de mejora en comparación con los conjuntos de datos típicamente utilizados en la literatura, donde las puntuaciones F1 de 0.90+ son típicas. Esperamos que el lanzamiento del conjunto de datos VRDU y el código de evaluación ayuden a los equipos de investigación a avanzar en el estado del arte en la comprensión de documentos.
Agradecimientos
Muchas gracias a Zilong Wang, Yichao Zhou, Wei Wei y Chen-Yu Lee, quienes coescribieron el artículo junto con Sandeep Tata. Gracias a Marc Najork, Riham Mansour y numerosos colaboradores de Google Research y el equipo de Cloud AI por brindar ideas valiosas. Gracias a John Guilyard por crear las animaciones en esta publicación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Por qué más es más (en Inteligencia Artificial)
- Un Análisis Profundo del Código del Modelo Visual Transformer (ViT)
- Gorilla – Mejorando la capacidad de los modelos de lenguaje grandes para utilizar llamadas a la API
- Las 6 mejores herramientas para mejorar tu productividad en Snowflake
- La Evolución de los Datos Tabulares Desde el Análisis hasta la IA
- Este artículo de IA sugiere que los modelos de aprendizaje automático cuántico pueden estar mejor defendidos contra ataques adversarios generados por computadoras clásicas.
- Taplio La Mejor Herramienta de IA para el Crecimiento en LinkedIn






