AudioLDM 2, pero más rápido ⚡️
AudioLDM 2, más rápido ⚡️
![]()
AudioLDM 2 fue propuesto en AudioLDM 2: Aprendizaje de Generación de Audio Holístico con Preentrenamiento Auto-supervisado por Haohe Liu et al. AudioLDM 2 toma una indicación de texto como entrada y predice el audio correspondiente. Puede generar efectos de sonido realistas, habla humana y música.
Aunque los audios generados tienen una alta calidad, la ejecución de inferencia con la implementación original es muy lenta: se tarda más de 30 segundos en generar una muestra de audio de 10 segundos. Esto se debe a una combinación de factores, incluyendo un enfoque de modelado en múltiples etapas, tamaños grandes de checkpoint y código no optimizado.
En esta publicación de blog, mostramos cómo usar AudioLDM 2 en la biblioteca de Hugging Face 🧨 Diffusers, explorando una serie de optimizaciones de código como precisión media, atención flash y compilación, y optimizaciones de modelo como elección de programador y indicación negativa, para reducir el tiempo de inferencia en más de 10 veces, con una degradación mínima en la calidad del audio de salida. La publicación de blog también viene acompañada de un cuaderno de Colab más simplificado, que contiene todo el código pero menos explicaciones.
- Colaboración humano-IA y ML en la evaluación de riesgos para la infraestructura inteligente
- Una guía completa para la optimización de hiperparámetros Explorando métodos avanzados
- Jais Un gran avance en los modelos de lenguaje de gran tamaño árabe-inglés
¡Lee hasta el final para descubrir cómo generar una muestra de audio de 10 segundos en solo 1 segundo!
Resumen del modelo
Inspirado en la Difusión Estable, AudioLDM 2 es un modelo de difusión latente (LDM) de texto a audio que aprende representaciones de audio continuas a partir de embeddings de texto.
El proceso general de generación se resume de la siguiente manera:
- Dado un texto de entrada x\boldsymbol{x}x, se utilizan dos modelos de codificador de texto para calcular los embeddings de texto: la rama de texto de CLAP y el codificador de texto de Flan-T5
E1=CLAP(x);E2=T5(x) \boldsymbol{E}_{1} = \text{CLAP}\left(\boldsymbol{x} \right); \quad \boldsymbol{E}_{2} = \text{T5}\left(\boldsymbol{x}\right) E1=CLAP(x);E2=T5(x)
Los embeddings de texto CLAP se entrenan para estar alineados con los embeddings de la muestra de audio correspondiente, mientras que los embeddings Flan-T5 dan una mejor representación de la semántica del texto.
- Estos embeddings de texto se proyectan a un espacio de embedding compartido mediante proyecciones lineales individuales:
P1=WCLAPE1;P2=WT5E2 \boldsymbol{P}_{1} = \boldsymbol{W}_{\text{CLAP}} \boldsymbol{E}_{1}; \quad \boldsymbol{P}_{2} = \boldsymbol{W}_{\text{T5}}\boldsymbol{E}_{2} P1=WCLAPE1;P2=WT5E2
En la implementación de diffusers, estas proyecciones están definidas por el AudioLDM2ProjectionModel.
- Se utiliza un modelo de lenguaje GPT2 (LM) para generar de manera auto-regresiva una secuencia de NNN nuevos vectores de embedding, condicionados a los embeddings proyectados de CLAP y Flan-T5:
Ei=GPT2(P1,P2,E1:i−1)para i=1,…,N \boldsymbol{E}_{i} = \text{GPT2}\left(\boldsymbol{P}_{1}, \boldsymbol{P}_{2}, \boldsymbol{E}_{1:i-1}\right) \qquad \text{para } i=1,\dots,N Ei=GPT2(P1,P2,E1:i−1)para i=1,…,N
- Los vectores de embedding generados E1:N\boldsymbol{E}_{1:N}E1:N y los embeddings de texto Flan-T5 E2\boldsymbol{E}_{2}E2 se utilizan como condicionantes de atención cruzada en el LDM, que desruido un latente aleatorio a través de un proceso de difusión inversa. El LDM se ejecuta en el proceso de difusión inversa durante un total de TTT pasos de inferencia:
zt=LDM(zt−1∣E1:N,E2)para t=1,…,T \boldsymbol{z}_{t} = \text{LDM}\left(\boldsymbol{z}_{t-1} | \boldsymbol{E}_{1:N}, \boldsymbol{E}_{2}\right) \qquad \text{para } t = 1, \dots, T zt=LDM(zt−1∣E1:N,E2)para t=1,…,T
donde la variable latente inicial z0\boldsymbol{z}_{0}z0 se extrae de una distribución normal N(0,I)\mathcal{N} \left(\boldsymbol{0}, \boldsymbol{I} \right)N(0,I). El UNet del LDM es único en el sentido de que toma dos conjuntos de incrustaciones de atención cruzada, E1:N\boldsymbol{E}_{1:N}E1:N del modelo de lenguaje GPT2, y E2\boldsymbol{E}_{2}E2 de Flan-T5, en lugar de una condición de atención cruzada como en la mayoría de los otros LDMs.
- Las latentes de-noised finales zT\boldsymbol{z}_{T}zT se pasan al decodificador VAE para recuperar el espectrograma Mel s\boldsymbol{s}s:
s=VAEdec(zT) \boldsymbol{s} = \text{VAE}_{\text{dec}} \left(\boldsymbol{z}_{T}\right) s=VAEdec(zT)
- El espectrograma Mel se pasa al vocoder para obtener la forma de onda de audio de salida y\mathbf{y}y:
y=Vocoder(s) \boldsymbol{y} = \text{Vocoder}\left(\boldsymbol{s}\right) y=Vocoder(s)
El siguiente diagrama muestra cómo se pasa una entrada de texto a través de los modelos de condicionamiento de texto, con las dos incrustaciones de indicación utilizadas como condicionamiento cruzado en el LDM:
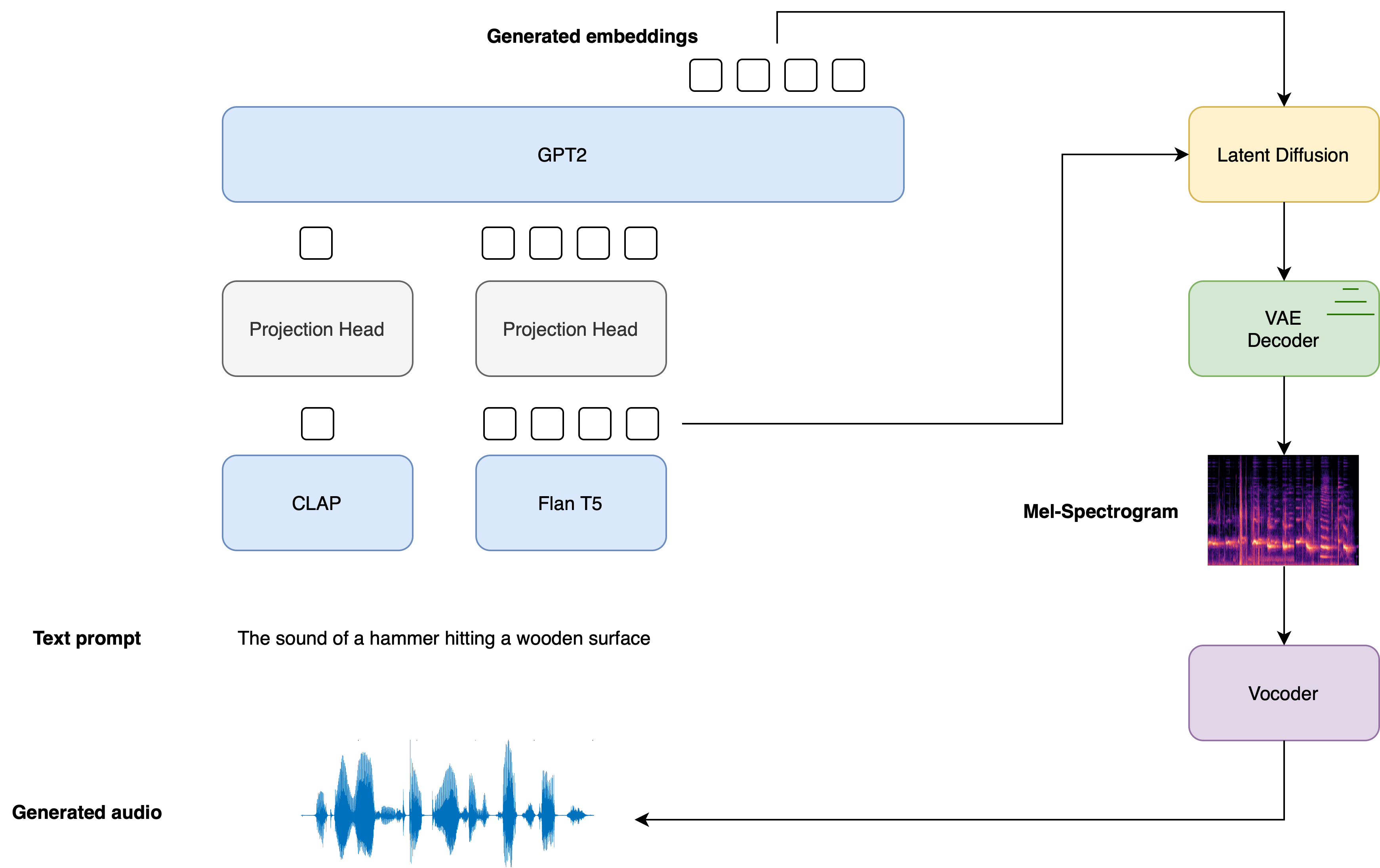
Para obtener todos los detalles sobre cómo se entrena el modelo AudioLDM 2, remítase al artículo AudioLDM 2.
Hugging Face 🧨 Diffusers proporciona una clase de tubería de inferencia de extremo a extremo AudioLDM2Pipeline que envuelve este proceso de generación de varias etapas en un solo objeto callable, lo que le permite generar muestras de audio a partir de texto en solo unas pocas líneas de código.
AudioLDM 2 viene en tres variantes. Dos de estos puntos de control son aplicables a la tarea general de generación de texto a audio. El tercer punto de control se entrena exclusivamente en la generación de texto a música. Consulte la tabla a continuación para obtener detalles sobre los tres puntos de control oficiales, que se pueden encontrar en Hugging Face Hub:
Ahora que hemos cubierto una descripción general de alto nivel de cómo funciona el proceso de generación de AudioLDM 2, ¡pongamos esta teoría en práctica!
Cargar la tubería
Para este tutorial, inicializaremos la tubería con los pesos pre-entrenados del punto de control base, cvssp/audioldm2. Podemos cargar la totalidad de la tubería utilizando el método .from_pretrained, que instanciará la tubería y cargará los pesos pre-entrenados:
from diffusers import AudioLDM2Pipeline
model_id = "cvssp/audioldm2"
pipe = AudioLDM2Pipeline.from_pretrained(model_id)Resultado:
Cargando componentes de tubería...: 100%|███████████████████████████████████████████| 11/11 [00:01<00:00, 7.62it/s]La tubería se puede mover a la GPU de la misma manera que un módulo nn estándar de PyTorch:
pipe.to("cuda");¡Genial! Definiremos un generador y estableceremos una semilla para reproducibilidad. Esto nos permitirá ajustar nuestras indicaciones y observar el efecto que tienen en las generaciones al fijar las latentes iniciales en el modelo LDM:
import torch
generator = torch.Generator("cuda").manual_seed(0)¡Ahora estamos listos para realizar nuestra primera generación! Utilizaremos el mismo ejemplo a lo largo de este cuaderno, donde condicionaremos las generaciones de audio en una indicación de texto fija y usaremos la misma semilla en todo. El argumento audio_length_in_s controla la duración del audio generado. Por defecto, es la duración de audio en la que se entrenó el LDM (10.24 segundos):
prompt = "El sonido de los tambores de samba brasileños con olas que rompen suavemente en el fondo"
audio = pipe(prompt, audio_length_in_s=10.24, generator=generator).audios[0]Salida:
100%|███████████████████████████████████████████| 200/200 [00:13<00:00, 15.27it/s]¡Genial! Esa ejecución tomó alrededor de 13 segundos para generar. Escuchemos el audio resultante:
from IPython.display import Audio
Audio(audio, rate=16000)Tu navegador no admite el elemento de audio.
¡Suena muy similar a nuestra indicación de texto! La calidad es buena, pero aún tiene artefactos de ruido de fondo. Podemos proporcionarle al pipeline una indicación negativa para desalentar la generación de ciertas características. En este caso, pasaremos una indicación negativa que desaliente al modelo a generar audio de baja calidad en las salidas. Omitiremos el argumento audio_length_in_s y dejaremos que tome su valor predeterminado:
negative_prompt = "Baja calidad, calidad promedio."
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]Salida:
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.50it/s]El tiempo de inferencia no cambia al usar una indicación negativa\({}^1\); simplemente reemplazamos la entrada incondicional al LDM con la entrada negativa. Esto significa que cualquier mejora que obtengamos en la calidad del audio la obtenemos de forma gratuita.
Escuchemos el audio resultante:
Audio(audio, rate=16000)Tu navegador no admite el elemento de audio.
Definitivamente hay una mejora en la calidad general del audio, hay menos artefactos de ruido y el audio suena en general más nítido. 1{}^11 Ten en cuenta que, en la práctica, normalmente vemos una reducción en el tiempo de inferencia al pasar de nuestra primera generación a nuestra segunda. Esto se debe a un “precalentamiento” de CUDA que ocurre la primera vez que ejecutamos el cálculo. La segunda generación es una mejor referencia para nuestro tiempo de inferencia real.
Optimización 1: Atención Flash
PyTorch 2.0 y versiones posteriores incluyen una implementación optimizada y eficiente en memoria de la operación de atención a través de la función torch.nn.functional.scaled_dot_product_attention (SDPA). Esta función aplica automáticamente varias optimizaciones integradas dependiendo de las entradas y se ejecuta de manera más rápida y eficiente en memoria que la implementación de atención convencional. En general, la función SDPA proporciona un comportamiento similar a la atención flash, como se propuso en el artículo “Fast and Memory-Efficient Exact Attention with IO-Awareness” de Dao et. al.
Estas optimizaciones estarán habilitadas de forma predeterminada en Diffusers si se instala PyTorch 2.0 y si está disponible torch.nn.functional.scaled_dot_product_attention. Para usarlo, simplemente instala torch 2.0 o superior según las instrucciones oficiales, y luego utiliza el pipeline tal como está 🚀
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]Salida:
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.60it/s]Para obtener más detalles sobre el uso de SDPA en diffusers, consulta la documentación correspondiente.
Optimización 2: Media Precisión
De forma predeterminada, el AudioLDM2Pipeline carga los pesos del modelo en precisión float32 (completa). Todos los cálculos del modelo también se realizan en precisión float32. Para la inferencia, podemos convertir de forma segura los pesos del modelo y los cálculos a precisión float16 (media), lo que nos dará una mejora en el tiempo de inferencia y en la memoria de la GPU, con un cambio imperceptible en la calidad de generación.
Podemos cargar los pesos en precisión float16 pasando el argumento torch_dtype a .from_pretrained:
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda");Ejecutemos la generación en precisión float16 y escuchemos las salidas de audio:
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
Audio(audio, rate=16000)Salida:
100%|███████████████████████████████████████████| 200/200 [00:09<00:00, 20.94it/s]Tu navegador no soporta el elemento de audio.
La calidad de audio se mantiene en gran medida sin cambios en comparación con la generación de precisión completa, y se obtiene una aceleración de inferencia de aproximadamente 2 segundos. En nuestra experiencia, no hemos observado degradación significativa del audio al utilizar tuberías diffusers con precisión float16, pero consistentemente obtenemos una sustancial aceleración de la inferencia. Por lo tanto, recomendamos utilizar la precisión float16 de forma predeterminada.
Optimización 3: Compilación de Torch
Para obtener una aceleración adicional, podemos utilizar la nueva función torch.compile. Dado que la UNet de la tubería suele ser la parte más computacionalmente costosa, envolvemos la UNet con torch.compile, dejando el resto de los submodelos (codificadores de texto y VAE) como están:
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)Después de envolver la UNet con torch.compile, el primer paso de inferencia que ejecutamos suele ser lento debido a la sobrecarga de compilar el pase hacia adelante de la UNet. Ejecutemos la tubería hacia adelante con el paso de compilación para realizar esta ejecución más larga. Ten en cuenta que el primer paso de inferencia puede tardar hasta 2 minutos en compilar, ¡así que ten paciencia!
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]Salida:
100%|███████████████████████████████████████████| 200/200 [01:23<00:00, 2.39it/s]¡Genial! Ahora que la UNet está compilada, podemos ejecutar el proceso de difusión completo y aprovechar los beneficios de una inferencia más rápida:
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]Salida:
100%|███████████████████████████████████████████| 200/200 [00:04<00:00, 48.98it/s]¡Solo 4 segundos para generar! En la práctica, solo tendrás que compilar la UNet una vez y luego obtendrás una inferencia más rápida para todas las generaciones sucesivas. Esto significa que el tiempo que se tarda en compilar el modelo se amortiza con las ganancias en el tiempo de inferencia posterior. Para obtener más información y opciones sobre torch.compile, consulta la documentación de compilación de Torch.
Optimización 4: Programador
Otra opción es reducir el número de pasos de inferencia. Elegir un programador más eficiente puede ayudar a disminuir el número de pasos sin sacrificar la calidad del audio de salida. Puedes encontrar qué programadores son compatibles con AudioLDM2Pipeline llamando al atributo schedulers.compatibles:
pipe.scheduler.compatiblesSalida:
[diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler,
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler]¡Bien! Tenemos una larga lista de planificadores para elegir 📝. Por defecto, AudioLDM 2 utiliza el DDIMScheduler y requiere 200 pasos de inferencia para obtener generaciones de audio de buena calidad. Sin embargo, los planificadores más eficientes, como DPMSolverMultistepScheduler, solo requieren 20-25 pasos de inferencia para lograr resultados similares.
Vamos a ver cómo podemos cambiar el planificador de AudioLDM 2 de DDIM a DPM Multistep. Utilizaremos el método ConfigMixin.from_config() para cargar un DPMSolverMultistepScheduler desde la configuración de nuestro DDIMScheduler original:
from diffusers import DPMSolverMultistepScheduler
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)Vamos a configurar el número de pasos de inferencia en 20 y volver a ejecutar la generación con el nuevo planificador. Como la forma de los latentes LDM no ha cambiado, no tenemos que repetir el paso de compilación:
audio = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]Salida:
100%|███████████████████████████████████████████| 20/20 [00:00<00:00, 49.14it/s]¡Eso tomó menos de 1 segundo para generar el audio! Vamos a escuchar la generación resultante:
Audio(audio, rate=16000)Tu navegador no soporta el elemento de audio.
Más o menos lo mismo que nuestra muestra de audio original, ¡pero solo una fracción del tiempo de generación! 🧨 Las tuberías de los difusores están diseñadas para ser componibles, lo que te permite cambiar fácilmente los planificadores y otros componentes por otros más eficientes.
¿Y qué pasa con la memoria?
La longitud de la muestra de audio que queremos generar dicta el ancho de las variables latentes que desenruidamos en el LDM. Dado que la memoria de las capas de interconexión cruzada en el UNet escala con la longitud de la secuencia (ancho) al cuadrado, generar muestras de audio muy largas puede provocar errores de falta de memoria. Nuestro tamaño de lote también gobierna el uso de memoria, controlando la cantidad de muestras que generamos.
Ya hemos mencionado que cargar el modelo en media precisión float16 ahorra memoria de forma significativa. El uso de PyTorch 2.0 SDPA también mejora la memoria, pero esto puede no ser suficiente para longitudes de secuencia extremadamente grandes.
Vamos a intentar generar una muestra de audio de 2.5 minutos (150 segundos) de duración. También generaremos 4 audios candidatos estableciendo num_waveforms_per_prompt``=4. Una vez que num_waveforms_per_prompt``>1, se realiza una puntuación automática entre los audios generados y la frase de texto: los audios y las frases de texto se incrustan en el espacio de incrustación de audio-texto CLAP, y luego se clasifican según sus puntuaciones de similitud coseno. Podemos acceder a la forma de onda ‘mejor’ como la que está en la posición 0.
Dado que hemos cambiado el ancho de las variables latentes en el UNet, tendremos que realizar otro paso de compilación de torch con las nuevas formas de las variables latentes. Por cuestiones de tiempo, volveremos a cargar la tubería sin compilación de torch, de manera que no tengamos que pasar por un largo paso de compilación al principio:
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda")
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]Salida:
---------------------------------------------------------------------------
OutOfMemoryError Traceback (most recent call last)
<ipython-input-33-c4cae6410ff5> in <cell line: 5>()
3 pipe.to("cuda")
4
----> 5 audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
23 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) -> str:
OutOfMemoryError: CUDA se quedó sin memoria. Se intentó asignar 1.95 GiB. La GPU 0 tiene una capacidad total de 14.75 GiB, de los cuales 1.66 GiB están libres. El proceso 414660 está utilizando 13.09 GiB de memoria. De la memoria asignada, 10.09 GiB está asignada por PyTorch, y 1.92 GiB está reservada por PyTorch pero no está asignada. Si la memoria reservada pero no asignada es grande, intente establecer max_split_size_mb para evitar la fragmentación. Consulte la documentación sobre la administración de memoria y PYTORCH_CUDA_ALLOC_CONF.A menos que tenga una GPU con una alta RAM, es probable que el código anterior haya devuelto un error OOM. Si bien el pipeline de AudioLDM 2 involucra varios componentes, solo el modelo que se está utilizando debe estar en la GPU en cualquier momento. El resto de los módulos se pueden transferir a la CPU. Esta técnica, llamada transferencia a la CPU, puede reducir el uso de memoria con una penalización muy baja en el tiempo de inferencia.
Podemos habilitar la transferencia a la CPU en nuestro pipeline con la función enable_model_cpu_offload():
pipe.enable_model_cpu_offload()La ejecución de la generación con transferencia a la CPU es entonces igual que antes:
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]Salida:
100%|███████████████████████████████████████████| 20/20 [00:36<00:00, 1.82s/it]¡Y con eso, podemos generar cuatro muestras, cada una de 150 segundos de duración, todo en una sola llamada al pipeline! El uso del punto de control grande de AudioLDM 2 dará como resultado un mayor uso de memoria en general que el punto de control base, ya que UNet tiene más del doble de tamaño (750M de parámetros en comparación con 350M), por lo que este truco de ahorro de memoria es especialmente beneficioso aquí.
Conclusión
En esta publicación de blog, mostramos cuatro métodos de optimización que están disponibles de forma predeterminada con 🧨 Diffusers, reduciendo el tiempo de generación de AudioLDM 2 de 14 segundos a menos de 1 segundo. También destacamos cómo emplear trucos para ahorrar memoria, como la semiprecisión y la transferencia a la CPU, para reducir el uso máximo de memoria para muestras de audio largas o tamaños de punto de control grandes.
Publicación de blog de Sanchit Gandhi. Muchas gracias a Vaibhav Srivastav y Sayak Paul por sus comentarios constructivos. Fuente de la imagen del espectrograma: Conociendo el espectrograma de Mel. Fuente de la imagen de la forma de onda: Aalto Speech Processing.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 25 sugerencias de ChatGPT para hacer crecer tu negocio
- Investigadores de la Universidad de Wisconsin-Madison proponen Eventful Transformers un enfoque rentable para el reconocimiento de video con una pérdida mínima de precisión.
- ¿Reemplazarán los LLMs a los Grafos de Conocimiento? Los investigadores de Meta proponen ‘Head-to-Tail’ un nuevo punto de referencia para medir el conocimiento factual de los Modelos de Lenguaje Grandes
- Entrena a tu primer agente de RL basado en Deep Q Learning Una guía paso a paso
- Introducción a la Estadística utilizando el lenguaje de programación R
- Investigadores de Alibaba presentan la serie Qwen-VL un conjunto de modelos de visión-lenguaje a gran escala diseñados para percibir y comprender tanto texto como imágenes
- Escalando la Agrupación Aglomerativa para Grandes Volúmenes de Datos





