Difusión de audio en miniatura Difusión de formas de onda que no requiere computación en la nube
Audio Miniature Broadcasting Cloudless Waveform Broadcasting.

Explorando cómo entrenar modelos y generar sonidos con difusión de formas de onda de audio en una computadora portátil y GPU de consumo con menos de 2GB de VRAM
Antecedentes
Los modelos de difusión están muy de moda en la actualidad, especialmente desde que Stable Diffusion causó sensación este verano pasado. Desde entonces, se han publicado innumerables variaciones y nuevos modelos de difusión en una amplia variedad de contextos. Y si bien las impresionantes imágenes han acaparado la atención, también ha habido un desarrollo significativo en la difusión relacionada con la generación de audio.
Impulsada por la difusión y otros métodos, la música generativa ha tenido muchos triunfos recientes, ya que constantemente se publican nuevos modelos. OpenAI sorprendió al mundo con las capacidades de Jukebox cuando se lanzó en 2020. Pero Google dijo “Espera mi modelo” cuando produjo el notable MusicLM a principios de este año. Meta no se quedó atrás cuando lanzó y liberó MusicGen el mes pasado. Pero no solo las grandes instituciones se están sumando, también ha habido contribuciones muy interesantes de investigadores independientes como Riffusion (Forsgren y Martiros) y Moûsai (Schneider, et al.). Además de estos, se han lanzado numerosos otros modelos en los últimos años, cada uno con sus ventajas y desventajas.
Los modelos de difusión han cautivado a tantos debido a su notable capacidad creativa; algo que muchos otros géneros de aprendizaje automático (ML) carecen. La mayoría de los modelos de ML se entrenan para realizar una tarea y su éxito se puede medir en términos de correcto vs incorrecto. Pero cuando entramos al ámbito del arte y la música, ¿cómo se puede optimizar un modelo para lo que se podría considerar lo mejor? Por supuesto, podría aprender a reproducir arte o música famosa, pero sin novedad, no tiene sentido. Entonces, ¿cómo se puede resolver este problema, inyectando creatividad en una máquina que solo conoce 1 y 0? La difusión es un método que ofrece una solución elegante a este dilema.
Difusión — Desde 10,000 pies
En su esencia, la difusión en ML es simplemente el proceso de agregar o remover ruido de una señal (piensa en el estático de un televisor antiguo). La difusión hacia adelante agrega ruido a una señal y la difusión inversa elimina el ruido. El proceso con el que estamos más familiarizados es el proceso de difusión inversa, donde el modelo toma ruido y luego lo “desruidiza” en algo que los humanos reconocen (arte, música, discurso, etc.). Este proceso se puede manipular de muchas formas para diferentes propósitos.
- Algoritmo encuentra esperma en hombres infértiles más rápido y con mayor precisión que los médicos.
- Más personas están quedando ciegas. La IA puede ayudar a combatirlo.
- Sitios web basura llenos de texto generado por inteligencia artificial están generando dinero a través de anuncios programáticos.
La “creatividad” en la difusión proviene del ruido aleatorio que inicia el proceso de desruidización. Si le proporcionas al modelo un punto de partida diferente cada vez para desruidizar en alguna forma de arte o música, esto simula la creatividad ya que las salidas siempre serán únicas.




El método de enseñar a un modelo a realizar este proceso de desruidización puede ser un poco contraintuitivo desde un pensamiento inicial. En realidad, el modelo aprende a desruidizar una señal haciendo exactamente lo contrario: agregar ruido a una señal limpia una y otra vez hasta que solo queda ruido. La idea es que si el modelo puede aprender a predecir el ruido agregado a una señal en cada paso, también puede predecir el ruido eliminado en cada paso para el proceso inverso. El elemento crítico para hacer esto posible es que el ruido que se agrega/elimina debe tener una distribución probabilística definida (normalmente gaussiana) para que los pasos de noisificación/desnoisificación sean predecibles y repetibles.
Hay mucho más detalle que entra en este proceso, pero esto debería proporcionar una comprensión conceptual sólida de lo que está sucediendo bajo el capó. Si estás interesado en aprender más sobre los modelos de difusión (formulaciones matemáticas, programación, espacio latente, etc.), recomiendo leer esta publicación de blog de AssemblyAI y estos documentos ( DDPM , Mejora de DDPM , DDIM , Difusión estable ).
Difusión de Audio Pequeño
Entendiendo el Audio para el Aprendizaje Automático
Mi interés en la difusión proviene del potencial que ha demostrado con el audio generativo. Tradicionalmente, para entrenar algoritmos de aprendizaje automático, el audio se convertía en un espectrograma, que es básicamente un mapa de calor de la energía del sonido a lo largo del tiempo. Esto se debía a que una representación de espectrograma era similar a una imagen, con la que las computadoras son excepcionales para trabajar, y era una reducción significativa en el tamaño de los datos en comparación con una forma de onda cruda.
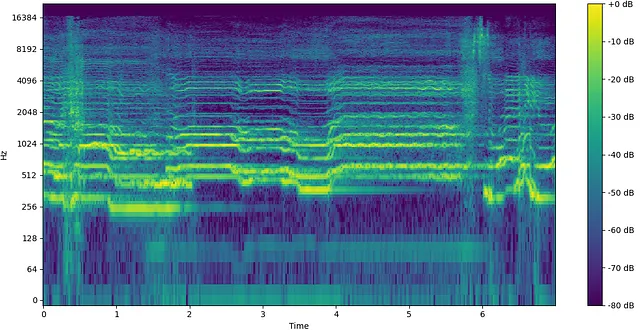
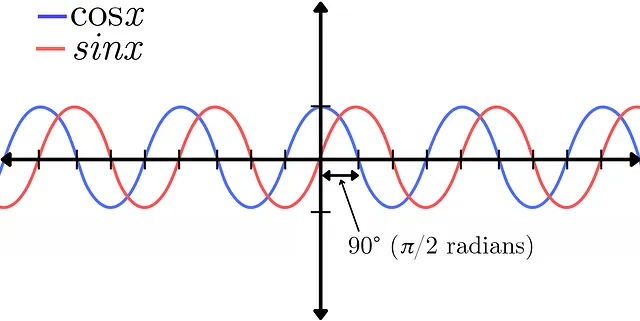
Sin embargo, con esta transformación vienen algunos compromisos, incluyendo una reducción de la resolución y una pérdida de información de fase. La fase de una señal de audio representa la posición de múltiples formas de onda en relación entre sí. Esto se puede demostrar en la diferencia entre una función seno y una función coseno. Representan la misma señal exacta en cuanto a amplitud, la única diferencia es un desplazamiento de fase de 90° (π/2 radianes) entre las dos. Para una explicación más detallada de la fase, echa un vistazo a este video de Akash Murthy.
La fase es un concepto perpetuamente desafiante de comprender, incluso para aquellos que trabajan en audio, pero desempeña un papel crítico en la creación de las cualidades timbrales del sonido. Basta decir que no se debe descartar tan fácilmente. La información de fase también puede representarse técnicamente en forma de espectrograma (la parte compleja de la transformada), al igual que la magnitud. Sin embargo, el resultado es ruidoso y visualmente parece aleatorio, lo que dificulta que un modelo aprenda alguna información útil de él. Debido a esta desventaja, ha habido un interés reciente en evitar transformar el audio en espectrogramas y, en su lugar, dejarlo como una forma de onda cruda para entrenar modelos. Si bien esto conlleva sus propios desafíos, tanto la información de amplitud como de fase se encuentran dentro de la señal única de una forma de onda, brindando al modelo una imagen más holística del sonido para aprender.
Esta es una pieza clave de mi interés en la difusión de formas de onda, y ha mostrado promesas en la obtención de resultados de alta calidad para el audio generativo. Sin embargo, las formas de onda son señales muy densas que requieren una cantidad significativa de datos para representar el rango de frecuencias que los humanos pueden escuchar. Por ejemplo, la tasa de muestreo estándar de la industria musical es de 44.1kHz, lo que significa que se requieren 44,100 muestras para representar solo 1 segundo de audio mono. Ahora duplica eso para la reproducción estéreo. Debido a esto, la mayoría de los modelos de difusión de formas de onda (que no aprovechan la difusión latente u otros métodos de compresión) requieren una alta capacidad de GPU (normalmente al menos 16GB+ VRAM) para almacenar toda la información mientras se entrena.
Motivación
Muchas personas no tienen acceso a GPUs de alta potencia y alta capacidad, o no desean pagar la tarifa para alquilar GPUs en la nube para proyectos personales. Encontrándome en esta posición, pero aún queriendo explorar modelos de difusión de formas de onda, decidí desarrollar un sistema de difusión de formas de onda que pudiera ejecutarse en mi modesto hardware local.
Configuración de Hardware
Estaba equipado con una laptop HP Spectre del 2017 con un procesador Intel Core i7 de 8ª generación y una tarjeta gráfica GeForce MX150 con 2GB de VRAM, no precisamente lo que se podría llamar un sistema de gran potencia para entrenar modelos de aprendizaje automático. Mi objetivo era poder crear un modelo que pudiera entrenar y producir salidas estéreo de alta calidad (44.1kHz) en este sistema.
Arquitectura del modelo
Utilicé la biblioteca de audio-diffusion-pytorch de Archinet para construir este modelo — gracias a Flavio Schneider por su ayuda en el trabajo con esta biblioteca que él construyó en gran medida.
Attention U-Net
La arquitectura base del modelo consiste en una U-Net con bloques de atención, que es estándar para los modelos de difusión modernos. Una U-Net es una red neuronal que fue originalmente desarrollada para la segmentación de imágenes (2D), pero se ha adaptado al audio (1D) para nuestros propósitos con la difusión de formas de onda. La arquitectura U-Net recibe su nombre por su diseño en forma de U.
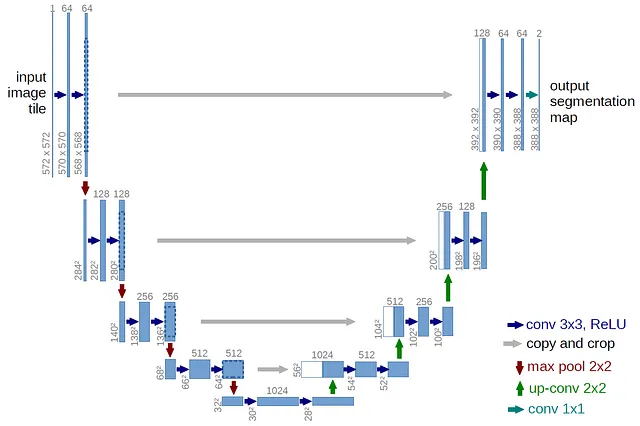
Muy similar a un autoencoder, que consta de un codificador y un decodificador, una U-Net también contiene conexiones de salto en cada nivel de la red. Estas conexiones de salto son conexiones directas entre capas correspondientes del codificador y el decodificador, facilitando la transferencia de detalles de granularidad fina del codificador al decodificador. El codificador se encarga de capturar las características importantes de la señal de entrada, mientras que el decodificador se encarga de generar la nueva muestra de audio. El codificador reduce gradualmente la resolución del audio de entrada, extrayendo características en diferentes niveles de abstracción. El decodificador toma estas características y las aumenta de tamaño, aumentando gradualmente la resolución para generar la muestra de audio final.

Esta U-Net también contiene bloques de autoatención en los niveles inferiores, lo que ayuda a mantener la consistencia temporal de la salida. Es fundamental que el audio se reduzca de manera suficiente para mantener la eficiencia del muestreo durante el proceso de difusión y evitar sobrecargar los bloques de atención. El modelo utiliza V-Diffusion, que es una técnica de difusión inspirada en el muestreo DDIM.
Para evitar quedarse sin VRAM de la GPU, la longitud de los datos en los que se entrenaría el modelo base debía ser corta. Debido a esto, decidí entrenar muestras de batería de una sola vez debido a sus longitudes de contexto inherentemente cortas. Después de muchas iteraciones, se determinó que la longitud del modelo base sería de 32,768 muestras a 44.1kHz en estéreo, lo que resulta en aproximadamente 0.75 segundos. Esto puede parecer particularmente corto, pero es suficiente tiempo para la mayoría de las muestras de batería.
Transformaciones
Para reducir la frecuencia de muestreo del audio lo suficiente para los bloques de atención, se intentaron varias transformaciones previas al procesamiento. La esperanza era que si los datos de audio podían reducirse sin perder información significativa antes de entrenar el modelo, entonces se podría maximizar el número de nodos (neuronas) y capas sin aumentar la carga de memoria de la GPU.
La primera transformación intentada fue una versión de “emparchado”. Originalmente propuesto para imágenes, este proceso se adaptó al audio para nuestros propósitos. La muestra de audio de entrada se agrupa por pasos de tiempo secuenciales en fragmentos que luego se transponen en canales. Este proceso luego se puede revertir en la salida de la U-Net para desagrupar el audio y devolverlo a su longitud completa. Sin embargo, el proceso de desagrupación creaba problemas de aliasing, lo que resultaba en artefactos indeseables de alta frecuencia en el audio generado.
La segunda transformación intentada, propuesta por Schneider, se llama “Transformación Aprendida” y consta de bloques de convolución simples con tamaños de kernel grandes y pasos al principio y al final de la U-Net. Se intentaron varios tamaños de kernel y pasos (16, 32, 64) junto con variaciones del modelo correspondientes para reducir adecuadamente la frecuencia de muestreo del audio. Sin embargo, esto también resultó en problemas de aliasing en el audio generado, aunque no tan prevalentes como con la transformación de emparchado.
Debido a esto, decidí que la arquitectura del modelo tendría que ajustarse para acomodar el audio sin transformaciones previas al procesamiento y producir salidas de calidad suficiente.
Esto requirió aumentar el número de capas dentro de la U-Net para evitar una reducción demasiado rápida de la frecuencia de muestreo y evitar la pérdida de características importantes en el camino. Después de múltiples iteraciones, la mejor arquitectura resultó en una reducción de la frecuencia de muestreo solo por 2 en cada capa. Si bien esto requería una reducción en el número de nodos por capa, finalmente produjo los mejores resultados. Se puede encontrar información detallada sobre el número exacto de niveles de U-Net, capas, nodos, características de atención, etc. en el archivo de configuración en el repositorio de tiny-audio-diffusion en GitHub.
Conclusión
Modelos Pre-entrenados
Entrené 4 modelos incondicionales separados para producir golpes, tambores de caja, hi-hats y percusión (todos sonidos de batería). Los conjuntos de datos utilizados para el entrenamiento fueron pequeñas muestras gratuitas que había recopilado para mis flujos de trabajo de producción musical (todos de código abierto). Conjuntos de datos más grandes y variados mejorarían la calidad y diversidad de las salidas generadas por cada modelo. Los modelos se entrenaron durante diferentes cantidades de pasos y épocas dependiendo del tamaño de cada conjunto de datos.
Los modelos pre-entrenados están disponibles para su descarga en Hugging Face . Consulte el progreso del entrenamiento y las muestras de salida registradas en Weights & Biases .
Resultados
En general, la calidad de la salida es bastante alta a pesar del reducido tamaño de los modelos. Sin embargo, todavía queda un ligero “siseo” de alta frecuencia, lo cual probablemente se debe al tamaño limitado del modelo. Esto se puede observar en la pequeña cantidad de ruido que queda en las formas de onda a continuación. La mayoría de las muestras generadas son nítidas, manteniendo los transitorios y las características tímbricas de banda ancha. A veces, los modelos agregan ruido adicional hacia el final de la muestra, lo cual es probablemente un costo de la limitación de capas y nodos del modelo.
Escucha algunas muestras de salida de los modelos aquí . A continuación se muestran ejemplos de salidas de cada modelo.
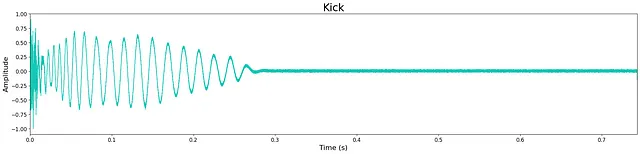
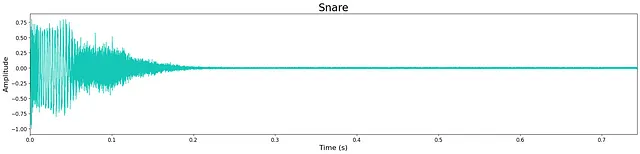
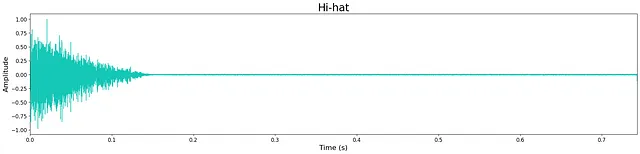
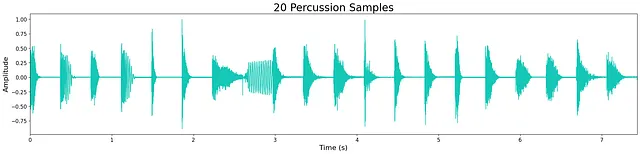
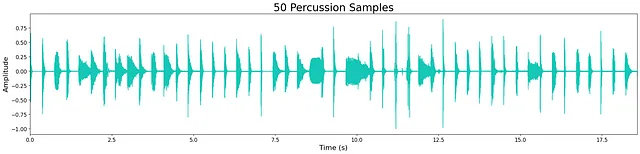
Discusión
Además de explorar modelos de difusión de formas de onda en mi hardware local, un objetivo importante de este proyecto era poder compartir esa misma oportunidad con otros. Quería ofrecer un punto de entrada fácil para aquellos con recursos limitados que estuvieran buscando experimentar con la difusión de formas de onda de audio. Por esta razón, estructuré el repositorio del proyecto para ofrecer instrucciones paso a paso sobre cómo entrenar o ajustar tus propios modelos, así como generar nuevas muestras desde el cuaderno Inference.ipynb.
Además, grabé un video tutorial que muestra cómo configurar un entorno de Anaconda y demuestra formas de generar muestras únicas con los modelos pre-entrenados.
Es un momento emocionante para el audio generativo, especialmente con la difusión. He aprendido una cantidad inmensa a través de la construcción de este proyecto y he ampliado aún más mi optimismo sobre lo que está por venir en el campo de la inteligencia artificial aplicada al audio. Espero que este proyecto pueda ser útil para otros que estén interesados en explorar el mundo del audio AI.
Todas las imágenes, a menos que se indique lo contrario, son del autor.
Código de tiny-audio-diffusion disponible aquí: https://github.com/crlandsc/tiny- audio-diffusion
Video tutorial sobre cómo configurar tu entorno para generar muestras con tiny-audio-diffusion: https://youtu.be/m6Eh2srtTro
Soy un científico del audio con enfoque en IA/ML y audio espacial, así como un músico de toda la vida. Si estás interesado en más aplicaciones de audio AI, consulta mi artículo reciente sobre Music Demixing .
Encuéntrame en LinkedIn & GitHub y mantente al día con mi trabajo e investigación actual aquí: www.chrislandschoot.com
Encuentra mi música en Spotify , Apple Music , YouTube , SoundCloud y otras plataformas de streaming como After August .
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- El nuevo profesor de Ciencias de la Computación de Harvard es un chatbot.
- Wimbledon utilizará inteligencia artificial para comentarios en video de aspectos destacados.
- La primera trenzado de anyones no abelianos del mundo.
- Cómo la I.A. está ayudando a los arquitectos a cambiar el diseño de los lugares de trabajo.
- Prodigio de preadolescencia se gradúa de la Universidad de Santa Clara.
- Mercedes incorpora ChatGPT en sus coches.
- Oportunidad de Asia para la Inteligencia Artificial Generativa.






