Asistente de Voz Personal impulsado por IA para el Aprendizaje de Idiomas
Asistente de Voz IA para Aprendizaje de Idiomas

¿Cuál es la forma más efectiva de dominar un nuevo idioma? ¡Hablarlo! Pero todos sabemos lo intimidante que puede ser probar nuevas palabras y frases frente a los demás. ¿Y si tuvieras un amigo paciente y comprensivo con quien practicar, libre de juicio, libre de vergüenza?
Ese amigo paciente y comprensivo que buscas podría ser un tutor virtual de idiomas impulsado por LLMs. Esto podría ser una forma revolucionaria de dominar un idioma, todo desde la comodidad de tu propio espacio.
Recientemente, los grandes modelos de lenguaje han llegado a escena y están cambiando la forma en que hacemos las cosas. Estas poderosas herramientas han creado chatbots que pueden responder como los humanos, y se han integrado rápidamente en varios aspectos de nuestras vidas, utilizándose de muchas formas diferentes. Un uso particularmente interesante es en el aprendizaje de idiomas, especialmente cuando se trata de práctica oral.
Cuando me mudé a Alemania hace algún tiempo, me di cuenta de lo desafiante que puede ser aprender un nuevo idioma y encontrar oportunidades para practicarlo hablado. Las clases y los grupos de idiomas pueden ser costosos o difíciles de encajar en una agenda ocupada. Como persona enfrentada a estos desafíos, se me ocurrió una idea: ¿por qué no utilizar chatbots para la práctica oral? Sin embargo, solo enviar mensajes de texto no sería suficiente, ya que el aprendizaje de idiomas implica más que solo escribir. Por lo tanto, al combinar un chatbot impulsado por IA con tecnologías de reconocimiento de voz y síntesis de voz a texto, logré crear una experiencia de aprendizaje que se siente como hablar con una persona real.
- Dentro de GPT – I Comprendiendo la generación de texto.
- Aprendizaje automático a gran escala Paralelismo de modelos frente a paralelismo de datos
- Visión del PM Modi sobre la regulación de la IA en India Cumbre B20 2023
En este artículo, compartiré las herramientas que he elegido, explicaré el proceso e introduciré el concepto de práctica oral con un chatbot de IA a través de comandos de voz y respuestas de voz. El proyecto consta de tres secciones principales: transcripción de voz a texto, uso de un modelo de lenguaje y conversión de texto a voz. Estos se explicarán en los siguientes tres apartados.
1. Transcripción de voz a texto
El reconocimiento de voz para mi tutor de idiomas actúa como el puente entre la entrada hablada del usuario y la comprensión basada en texto de la IA para generar una respuesta. Es un componente crítico que permite la interacción guiada por voz, contribuyendo a una experiencia de aprendizaje de idiomas más inmersiva y efectiva.
Una transcripción precisa es crucial para una interacción fluida con el chatbot, especialmente en un contexto de aprendizaje de idiomas donde la pronunciación, el acento y la gramática son factores clave. Hay varias herramientas de reconocimiento de voz que se pueden utilizar para transcribir la entrada hablada en Python, como Whisper de OpenAI y Speech-to-Text de Google Cloud.
Cuando se selecciona una herramienta de reconocimiento de voz para el proyecto del tutor de idiomas, se deben tener en cuenta consideraciones como la precisión, el soporte de idiomas, el costo y si se requiere una solución sin conexión.
Google tiene una API de Python que requiere conexión a internet y ofrece 60 minutos de transcripción gratuitos al mes. A diferencia de Google, OpenAI publicó su modelo Whisper y puedes ejecutarlo localmente sin depender de la velocidad de internet siempre que tengas suficiente potencia de cálculo. Por eso he elegido Whisper para reducir al máximo la latencia de la transcripción.
2. Modelo de lenguaje
El modelo de lenguaje es el corazón de este proyecto. Como ya estoy muy familiarizado con ChatGPT y su API, he decidido utilizarlo también para este proyecto. Sin embargo, en caso de que tengas suficiente potencia de cálculo, también puedes implementar Llama localmente, lo cual sería gratuito. ChatGPT tiene un costo, pero es mucho más conveniente, ya que solo necesitas unas pocas líneas de código para ejecutarlo.
Para aumentar la consistencia de las respuestas y tenerlas en una plantilla específica, también puedes ajustar los modelos de lenguaje (por ejemplo, cómo ajustar chatgpt a tu caso de uso). Necesitas generar oraciones ejemplares y las respuestas óptimas correspondientes, y alimentarlas en un entrenamiento de ajuste fino. Sin embargo, el tutor básico que quiero construir no necesita un ajuste fino y utilizaré el GPT3.5-turbo generalizado en mi proyecto.
A continuación, proporcionaré un ejemplo de una llamada a la API para facilitar una conversación entre el usuario y ChatGPT a través de su API en Python. Primero, si aún no tienes uno, deberás abrir una cuenta en OpenAI y establecer una clave de API para interactuar con ChatGPT. Las instrucciones se encuentran aquí.
Una vez que hayas configurado tu clave de API, puedes comenzar a generar texto utilizando el método openai.ChatCompletion.create. Este método requiere dos parámetros: el parámetro model, que especifica el modelo GPT particular al que se accederá a través de la API, y el parámetro messages, que incluye la estructura de una conversación con ChatGPT. El parámetro messages consta de dos componentes clave: role y content.
Aquí hay un fragmento de código para ilustrar el proceso:
# Inicializar los mensajes con el comportamiento(s) establecido(s).
messages = [{"role": "system", "content": "Ingrese aquí el(los) comportamiento(s)."}]
# Iniciar un bucle infinito para continuar la conversación con el usuario.
while True:
contenido = input("Usuario: ") # Obtener la entrada del usuario para responder.
messages.append({"role": "usuario", "content": contenido}) # Agregar la entrada del usuario a los mensajes.
# Utilizar el modelo OpenAI GPT-3.5 para generar una respuesta a la entrada del usuario.
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
respuesta_chat = completion.choices[0].message.content # Extraer la respuesta del chat de la respuesta de la API.
print(f'ChatGPT: {respuesta_chat}') # Imprimir la respuesta.
# Agregar la respuesta a los mensajes con el rol "asistente" para almacenar el historial del chat.
messages.append({"role": "asistente", "content": respuesta_chat})- El rol
systemse define para determinar el comportamiento de ChatGPT agregando una instrucción dentro del contenido al principio de la lista de mensajes. - Durante el chat, se recibe el mensaje del
usuariodel usuario a través del modelo de reconocimiento de voz mencionado para obtener una respuesta de ChatGPT. - Finalmente, las respuestas de ChatGPT se agregan a la lista de mensajes con el rol de
asistentepara registrar el historial de la conversación.
3. Conversión de texto a voz
En la sección de transcripción de voz a texto, expliqué cómo el usuario utiliza comandos de voz para simular una experiencia conversacional, como si estuviera hablando con una persona real. Para mejorar aún más esta sensación y crear una experiencia de aprendizaje más dinámica e interactiva, el siguiente paso consiste en convertir la salida de texto de GPT en voz audible utilizando una herramienta de texto a voz como gTTS. Esto no solo ayuda a crear una experiencia más atractiva y fácil de seguir, sino que también aborda un aspecto crítico del aprendizaje de idiomas: el desafío de la comprensión a través de la escucha en lugar de la lectura. Al integrar este componente auditivo, estamos facilitando una práctica más integral que se asemeja estrechamente al uso del lenguaje en el mundo real.
Existen varias herramientas de TTS disponibles, como el Text-to-Speech (TTS) de Google y el Text to Speech de IBM Watson. En este proyecto, preferí gTTS ya que es muy fácil de usar, presenta una calidad de voz natural y no cuesta nada. Para usar la biblioteca gTTS, necesitarás tener una conexión a Internet ya que la biblioteca requiere acceso al servidor de Google para convertir el texto en voz.
Explicación detallada del pipeline
Antes de sumergirnos en el pipeline, es posible que desees echar un vistazo al código completo en mi página de Github, ya que haré referencia a algunas secciones de él.
La siguiente figura explica el flujo de trabajo del tutor virtual de idiomas impulsado por IA que está diseñado para establecer una experiencia de aprendizaje conversacional en tiempo real basada en voz:
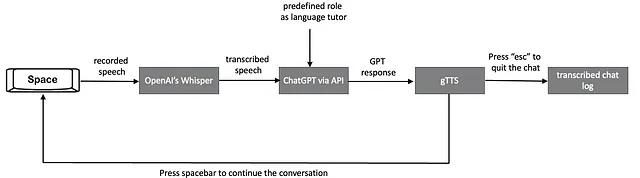
- El usuario comienza la conversación iniciando la grabación de su voz, guardándola temporalmente como un archivo .wav. Esto se logra presionando y manteniendo presionada la barra espaciadora, y la grabación se detiene cuando se suelta la barra espaciadora. Las secciones del código Python que permiten esta funcionalidad de presionar y hablar se explican a continuación.
Las siguientes variables globales se utilizan para controlar el estado del proceso de grabación:
grabando = False # Indica si el sistema está grabando actualmentegrabacion_completa = False # Indica que el usuario ha completado la grabación de un comando de vozdetener_grabacion = False # Indica que el usuario desea salir de la conversaciónLa función escuchar_teclas se utiliza para verificar las pulsaciones y liberaciones de teclas. Establece las variables globales en función del estado de la barra espaciadora y el botón “esc”.
def escuchar_teclas(): # Función para escuchar las pulsaciones de teclas para controlar la grabación global grabando, grabacion_completa, detener_grabacion while True: if keyboard.is_pressed('space'): # Iniciar la grabación al presionar la barra espaciadora detener_grabacion = False grabando = True grabacion_completa = False elif keyboard.is_pressed('esc'): # Detener la grabación al presionar 'esc' detener_grabacion = True break elif grabando: # Detener la grabación al soltar la barra espaciadora grabando = False grabacion_completa = True break time.sleep(0.01)La función callback se utiliza para manejar los datos de audio durante la grabación. Verifica la bandera recording para determinar si se deben grabar los datos de audio entrantes.
def callback(indata, frames, time, status): # Función llamada para cada bloque de audio durante la grabación. if recording: if status: print(status, file=sys.stderr) q.put(indata.copy())La función press2record es la función principal encargada de manejar la grabación de voz cuando el usuario presiona y mantiene presionada la barra espaciadora.
Inicializa variables globales para gestionar el estado de grabación y determina la frecuencia de muestreo. Crea un archivo temporal para almacenar el audio grabado.
Luego, la función abre un objeto SoundFile para escribir los datos de audio y un objeto InputStream para capturar el audio del micrófono, utilizando la función callback mencionada anteriormente. Se inicia un hilo para escuchar las pulsaciones de teclas, específicamente la barra espaciadora para grabar y la tecla ‘esc’ para detener. Dentro de un bucle, la función verifica la bandera de grabación y escribe los datos de audio en el archivo si la grabación está activa. Si la grabación se detiene, la función devuelve -1; de lo contrario, devuelve el nombre de archivo del audio grabado.
def press2record(filename, subtype, channels, samplerate): # Función para manejar la grabación cuando se presiona una tecla global recording, done_recording, stop_recording stop_recording = False recording = False done_recording = False try: # Determinar la frecuencia de muestreo si no se proporciona if samplerate is None: device_info = sd.query_devices(None, 'input') samplerate = int(device_info['default_samplerate']) print(int(device_info['default_samplerate'])) # Crear un nombre de archivo temporal si no se proporciona if filename is None: filename = tempfile.mktemp(prefix='captured_audio', suffix='.wav', dir='') # Abrir el archivo de sonido para escribir with sf.SoundFile(filename, mode='x', samplerate=samplerate, channels=channels, subtype=subtype) as file: with sd.InputStream(samplerate=samplerate, device=None, channels=channels, callback=callback, blocksize=4096) as stream: print('presiona la barra espaciadora para comenzar a grabar, suelta para detener o presiona Esc para salir') listener_thread = threading.Thread(target=listen_for_keys) # Iniciar el oyente en un hilo separado listener_thread.start() # Escribir el audio grabado en el archivo while not done_recording and not stop_recording: while recording and not q.empty(): file.write(q.get()) # Devolver -1 si la grabación se detiene if stop_recording: return -1 except KeyboardInterrupt: print('Interrumpido por el usuario') return filenameFinalmente, la función get_voice_command llama a press2record para grabar el comando de voz del usuario.
def get_voice_command(): # ... saved_file = press2record(filename="input_to_gpt.wav", subtype = args.subtype, channels = args.channels, samplerate = args.samplerate) # ...- Habiendo capturado y guardado el comando de voz en un archivo .wav temporal, ahora pasamos a la fase de transcripción. En esta etapa, el audio grabado se convierte en texto utilizando Whisper. El siguiente fragmento de código corresponde a simplemente ejecutar la tarea de transcripción para un archivo .wav:
def get_voice_command(): # ... result = audio_model.transcribe(saved_file, fp16=torch.cuda.is_available()) # ...Este método toma dos parámetros: la ruta al archivo de audio grabado, saved_file, y una bandera opcional para usar precisión FP16 si CUDA está disponible para mejorar el rendimiento en hardware compatible. Simplemente devuelve el texto transcrito.
- A continuación, el texto transcrito se envía a ChatGPT para generar una respuesta adecuada en la función
interact_with_tutor(). El segmento de código correspondiente es el siguiente:
def interact_with_tutor(): # Define el rol del sistema para establecer el comportamiento del asistente de chat messages = [ {"role": "system", "content" : "Du bist Anna, meine deutsche Lernpartnerin. Du wirst mit mir chatten. Ihre Antworten werden kurz sein. Mein Niveau ist B1, stell deine Satzkomplexität auf mein Niveau ein. Versuche immer, mich zum Reden zu bringen, indem du Fragen stellst, und vertiefe den Chat immer."} ] while True: # Obtener el comando de voz del usuario command = get_voice_command() if command == -1: # Guardar los registros del chat y salir si se detiene la grabación save_response_to_pkl(messages) return "La conversación ha sido detenida." # Agregar el comando del usuario al historial de mensajes messages.append({"role": "user", "content": command}) # Generar una respuesta del asistente de chat completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages ) # Extraer la respuesta de la finalización chat_response = completion.choices[0].message.content # Extraer la respuesta de la finalización print(f'ChatGPT: {chat_response} \n') # Imprimir la respuesta del asistente messages.append({"role": "assistant", "content": chat_response}) # Agregar la respuesta del asistente al historial de mensajes # ...La función interact_with_tutor comienza definiendo el rol del sistema de ChatGPT para dar forma a su comportamiento a lo largo de la conversación. Como mi objetivo es practicar alemán, establezco el rol del sistema en consecuencia. Llamé a mi tutor virtual “Anna” y establecí mi nivel de competencia lingüística para que ajuste sus respuestas. Además, le indiqué que mantenga la conversación interesante haciendo preguntas.
A continuación, el comando de voz transcrito del usuario se agrega a la lista de mensajes con el rol de “usuario”. Este mensaje se envía a ChatGPT. A medida que la conversación continúa dentro de un bucle while, todo el historial de comandos del usuario y respuestas de GPT se registra en la lista de mensajes.
- Después de cada respuesta de ChatGPT, convertimos el mensaje de texto en voz utilizando gTTS.
def interact_with_tutor(): # ... # Convertir la respuesta de texto a voz speech_object = gTTS(text=messages[-1]['content'],tld="de", lang=language, slow=False) speech_object.save("GPT_response.wav") current_dir = os.getcwd() audio_file = "GPT_response.wav" # Reproducir la respuesta de audio play_wav_once(audio_file, args.samplerate, 1.0) os.remove(audio_file) # Eliminar el archivo de audio temporalLa función gTTS() recibe 4 parámetros: text, tld, lang y slow. El parámetro text se le asigna el contenido del último mensaje en la lista de messages (indicado por [-1]) que se desea convertir en voz. El parámetro tld especifica el dominio de nivel superior para el servicio de Google Translate. Establecerlo en "de" significa que se utiliza el dominio alemán, lo cual puede ser importante para asegurar que la pronunciación y entonación sean adecuadas para el alemán. El parámetro lang especifica el idioma en el que se debe hablar el texto. En este código, la variable language se establece en 'de', lo que significa que el texto se hablará en alemán. slow=False: el parámetro slow controla la velocidad del habla. Establecerlo en False significa que el habla se realizará a velocidad normal. Si se estableciera en True, el habla se realizaría más lentamente.
- La respuesta de ChatGPT convertida en voz se guarda como un archivo .wav temporal, se reproduce al usuario y luego se elimina.
- La función
interact_with_tutorse ejecuta repetidamente cuando el usuario continúa la conversación al presionar la tecla de espacio nuevamente. - Si el usuario presiona “esc”, la conversación termina y toda la conversación se guarda en un archivo pickle,
chat_log.pkl. Puedes usarlo más tarde para realizar algún análisis.
Uso en la línea de comandos
Para ejecutar el script, simplemente ejecuta el código de Python en la terminal de la siguiente manera:
sudo python chat.pySe necesita sudo ya que el script requiere acceder al micrófono y utilizar la biblioteca de teclado. Si usas Anaconda, también puedes iniciar la terminal de Anaconda como “ejecutar como administrador” para otorgar acceso completo.
Aquí tienes un video de demostración que muestra cómo se ejecuta el código en mi portátil. Puedes tener una idea del rendimiento:
Video de demostración creado por el autor
Observaciones finales
Establecí el idioma del tutor en alemán simplemente configurando el rol del sistema de ChatGPT y ajustando los parámetros dentro de la función gTTs para que se alineen con el idioma alemán. Sin embargo, podrías cambiarlo fácilmente a otro idioma. Solo tomaría unos segundos configurarlo para tu idioma objetivo.
Si deseas chatear sobre un tema específico, también puedes agregarlo en el rol del sistema de ChatGPT. Por ejemplo, practicar para entrevistas podría ser un buen caso de uso. También puedes especificar tu nivel de idioma para ajustar sus respuestas.
Una observación importante es que la velocidad general del chat depende de tu conexión a Internet (debido a la API de ChatGPT y gTTS) y también de tu hardware (debido a la implementación local de Whisper). En mi caso, el tiempo de respuesta general después de mis entradas varía entre 4 y 10 segundos.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- IA y el futuro del fútbol universitario
- Solucionando cuellos de botella en la tubería de entrada de datos con PyTorch Profiler y TensorBoard
- Versión de ChatGPT para Grandes Empresas a ser lanzada por OpenAI
- Tutorial Avanzado Cómo Dominar Matplotlib como un Verdadero Jefe
- Revolucionando la productividad del correo electrónico Cómo la IA de SaneBox transforma tu experiencia en la bandeja de entrada
- Conoce a Nous-Hermes-Llama2-70b Un modelo de lenguaje de última generación ajustado finamente en más de 300,000 instrucciones.
- Cadenas de Markov de Tiempo Discreto – Identificando Trayectorias Ganadoras de Clientes en una Campaña de Devolución de Dinero






