Este artículo de IA de NTU Singapur presenta MeVIS un banco de pruebas a gran escala para la segmentación de video con expresiones de movimiento
Artículo de IA de NTU Singapur sobre MeVIS, un banco de pruebas para segmentación de video con expresiones de movimiento.


La segmentación de video guiada por lenguaje es un campo en desarrollo que se centra en segmentar y rastrear objetos específicos en videos utilizando descripciones en lenguaje natural. Los conjuntos de datos actuales para referirse a objetos en video generalmente enfatizan objetos prominentes y se basan en expresiones de lenguaje con muchos atributos estáticos. Estos atributos permiten identificar el objeto objetivo en solo un fotograma. Sin embargo, estos conjuntos de datos pasan por alto la importancia del movimiento en la segmentación de objetos de video guiada por lenguaje.

Los investigadores han presentado MeVIS, un nuevo conjunto de datos a gran escala llamado Segmentación de Video de Expresión de Movimiento (MeViS), para ayudar en nuestra investigación. El conjunto de datos MeViS consta de 2,006 videos con 8,171 objetos, y se proporcionan 28,570 expresiones de movimiento para referirse a estos objetos. Las imágenes anteriores muestran las expresiones en MeViS que se centran principalmente en atributos de movimiento, y el objeto objetivo mencionado no se puede identificar examinando un solo fotograma. Por ejemplo, el primer ejemplo muestra tres loros con apariencias similares, y el objeto objetivo se identifica como “El pájaro volando lejos”. Este objeto solo se puede reconocer capturando su movimiento a lo largo del video.
Se toman algunos pasos para asegurar que el conjunto de datos MeVIS enfatice los movimientos temporales de los videos.
- Cómo codificar características de tiempo periódicas
- Introducción e Implementación de Redes Siamesas
- Anunciando la vista previa de Amazon SageMaker Profiler Haga un seguimiento y visualice datos detallados de rendimiento de hardware para sus cargas de trabajo de entrenamiento de modelos.
Primero, se selecciona cuidadosamente el contenido de video que contiene múltiples objetos que coexisten con movimiento y se excluyen los videos con objetos aislados que se pueden describir fácilmente con atributos estáticos.
En segundo lugar, se priorizan las expresiones de lenguaje que no contienen pistas estáticas, como nombres de categorías o colores de objetos, en los casos en que los objetos objetivo se pueden describir de manera unívoca solo con palabras de movimiento.
Además de proponer el conjunto de datos MeViS, los investigadores también presentan un enfoque básico llamado Percepción y Coincidencia de Movimiento Guiada por Lenguaje (LMPM) para abordar los desafíos planteados por este conjunto de datos. Su enfoque implica la generación de consultas condicionadas por lenguaje para identificar objetos objetivo potenciales dentro del video. Estos objetos se representan utilizando incrustaciones de objetos, que son más robustas y eficientes computacionalmente en comparación con los mapas de características de objetos. Los investigadores aplican la Percepción de Movimiento a estas incrustaciones de objetos para capturar el contexto temporal y establecer una comprensión holística de la dinámica de movimiento del video. Esto permite que su modelo comprenda tanto los movimientos momentáneos como los prolongados presentes en el video.
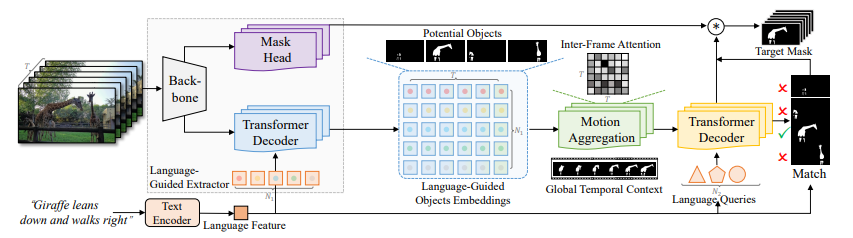
La imagen anterior muestra la arquitectura de LMLP. Utilizan un decodificador Transformer para interpretar el lenguaje a partir de incrustaciones de objetos combinadas afectadas por el movimiento. Esto ayuda a predecir los movimientos de los objetos. Luego, comparan las características del lenguaje con los movimientos proyectados de los objetos para encontrar el/los objeto(s) objetivo mencionado(s) en las expresiones. Este método innovador fusiona la comprensión del lenguaje y la evaluación del movimiento para manejar eficazmente la tarea del conjunto de datos complejo.
Esta investigación ha sentado las bases para desarrollar algoritmos más avanzados de segmentación de video guiada por lenguaje. Ha abierto caminos en direcciones más desafiantes, como:
- Explorar nuevas técnicas para una mejor comprensión y modelado del movimiento en las modalidades visual y lingüística.
- Crear modelos más eficientes que reduzcan el número de objetos detectados redundantes.
- Diseñar métodos efectivos de fusión cruzada modal para aprovechar la información complementaria entre el lenguaje y las señales visuales.
- Desarrollar modelos avanzados que puedan manejar escenas complejas con diversos objetos y expresiones.
Abordar estos desafíos requiere investigación para impulsar el estado actual de la técnica en el campo de la segmentación de video guiada por el lenguaje hacia adelante.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- El algoritmo de Google hace que la encriptación FIDO sea segura contra ordenadores cuánticos
- El mito de la IA de ‘código abierto
- Un derrame le robó la capacidad de hablar a los 30 años. La IA está ayudando a restaurarla años después.
- RAG vs Finetuning ¿Cuál es la mejor herramienta para impulsar tu solicitud de LLM?
- ¿Podemos evitar que los LLMs alucinen?
- Explorando el paisaje de la inteligencia artificial generativa
- Agentes de IA Tendencia del Mes en IA Generativa






