Aproveche el poder de las bases de datos vectoriales influenciando los modelos de lenguaje con información personalizada.
Aproveche las bases de datos vectoriales para personalizar los modelos de lenguaje.
Potencia tus modelos de lenguaje con bases de datos vectoriales. Personaliza las consultas usando tus propios datos para dar contexto a estos poderosos modelos, mejorando su comportamiento. Integra información personal para una experiencia de generación de lenguaje a medida.
En este artículo, aprenderemos cómo dos nuevas tecnologías: bases de datos vectoriales y modelos de lenguaje grandes, pueden trabajar juntas. Esta combinación está causando actualmente una interrupción significativa en la industria tecnológica.
A menudo se utiliza para incorporar tu propia documentación o bases de conocimiento empresarial, en las que el modelo de lenguaje no ha sido entrenado. La idea es asegurarse de que dicha información se tenga en cuenta al generar las respuestas del modelo. Se trata de darle a tu modelo de lenguaje acceso a tu información útil que puede mejorar y hacer más relevantes sus salidas.
Ese es el caso de uso que exploraremos. Estos son los pasos que seguiremos:
- Crear la base de datos vectorial utilizando ChromaDB.
- Almacenar información en la base de datos.
- Recuperar información a través de una consulta.
- Generar una consulta extendida utilizando esta información.
- Cargar un modelo de Hugging Face.
- Pasar la consulta al modelo.
- El modelo proporcionará una respuesta, teniendo en cuenta la información proporcionada.
Siguiendo estos pasos, podemos utilizar ChromaDB para agregar fácilmente información personal al proceso de toma de decisiones del modelo de lenguaje.
- De ChatGPT a Pi, ¡y te voy a contar por qué!
- Una nueva investigación de inteligencia artificial propone un razonamiento multimodal de cadena de pensamiento en modelos de lenguaje que supera a GPT-3.5 en un 16% (75,17% → 91,68%) en ScienceQA.
- Investigadores de la Universidad de UT Austin presentan PSLD Un método de IA que utiliza difusión estable para resolver todos los problemas lineales sin necesidad de entrenamiento adicional.
De esta manera, podemos obtener respuestas altamente personalizadas y contextualmente relevantes.
¡Sumergámonos en cada paso y desbloqueemos todo el potencial de este enfoque!
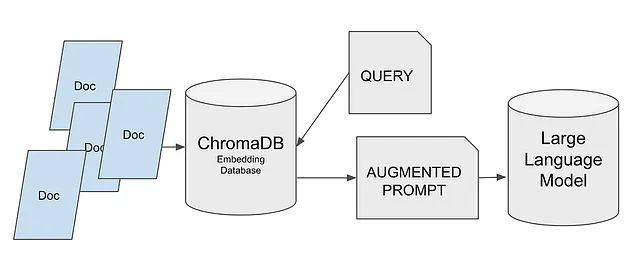
Pero antes de adentrarnos, hagamos una breve introducción sobre cómo funcionan las bases de datos vectoriales.
¿Cómo funcionan las bases de datos vectoriales?
En primer lugar, estas bases de datos almacenan vectores, como su nombre sugiere. Necesitamos transformar el texto que tenemos en información que pueda ser almacenada en estas herramientas. En otras palabras, necesitamos convertir nuestro texto en vectores.
Existen varios enfoques disponibles, pero en resumen, todos ellos convierten una secuencia de texto, que puede ser palabras, sílabas o frases, en vectores.
Los vectores que obtenemos son multidimensionales y, naturalmente, podemos calcular la diferencia entre un vector y otro o buscar vectores que estén más cerca de uno específico.
Con esta información, podemos entender cómo funciona de manera general.
- Convertimos el texto en vectores y los almacenamos.
- Convertimos el texto a buscar en vectores y los comparamos.
- Seleccionamos los vectores más cercanos.
- Estos vectores se convierten nuevamente en texto y se devuelven.
¡Olvidémonos de las búsquedas de texto! Todo se trata de comparaciones de vectores.
Como probablemente ya habrás adivinado, el proceso de convertir texto en vectores debe ser el mismo tanto para el texto almacenado como para el texto a buscar. De lo contrario, la comparación sería sin sentido.
Las bases de datos vectoriales están ganando cada vez más importancia, no solo para casos como el nuestro donde buscamos noticias relacionadas, sino también para cualquier sistema de recomendación.
De hecho, los vectores son representaciones numéricas esenciales y no necesariamente tienen que provenir de texto. Podemos almacenar películas transformadas en vectores, junto con sus metadatos, y buscar las más similares. Incluso podríamos identificar patrones que nos permitan recomendar películas basadas en los hábitos de visualización del usuario. Espera un momento… ¿podría ser que Netflix también los esté utilizando para su sistema de recomendación? ¿Queremos hacer una apuesta?
¿Qué tecnología utilizaremos?
En cuanto a la base de datos, he elegido ChromaDB. Es una de las últimas bases de datos que ha surgido y ha ganado popularidad rápidamente. Verás que su uso es extremadamente sencillo. No tendremos que preocuparnos por mucho porque ChromaDB se encarga de la mayoría del trabajo por nosotros. Es una solución de código abierto que se puede integrar perfectamente con LangChain, lo cual es importante porque en futuros artículos utilizaremos LangChain para construir soluciones cada vez más complejas.
Vamos a obtener el modelo de Hugging Face. Específicamente, he utilizado dolly-v2-3b. Esta es la versión más pequeña de la familia de modelos Dolly. Sugiero utilizar versiones más pequeñas de modelos siempre que sea posible.
Personalmente, disfruto experimentar con diferentes modelos siempre que tengo la oportunidad, y Hugging Face ofrece una amplia selección de modelos para elegir.
Si quieres probar un modelo diferente, puedes buscarlo en Hugging Face y asegurarte de que esté entrenado para la generación de texto.

¡Vamos a empezar con el proyecto!
Puedes encontrar el código en un Notebook en Kaggle, donde puedes hacer un fork, ejecutar y experimentar con él. También está disponible en GitHub en un repositorio donde guardo todos los notebooks del curso Large Language Models, así como sus artículos correspondientes.
Utilizar una base de datos vectorial para optimizar los patrones para LLMs
Explorar y ejecutar código de aprendizaje automático con Kaggle Notebooks | Usar datos de múltiples fuentes de datos
www.kaggle.com
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribuir al desarrollo de peremartra/Large-Language-Model-Notebooks-Course creando una cuenta en GitHub.
github.com
Si estás interesado en seguir el curso completo, es mejor suscribirte al repositorio de GitHub. De esta manera, recibirás notificaciones de nuevas lecciones o modificaciones a las existentes.
Importemos las bibliotecas necesarias.
Para empezar, necesitaremos instalar algunos paquetes de Python:
- sentence-transformers: Esta biblioteca es necesaria para transformar frases en vectores de longitud fija, es decir, para incrustar.
- transformers: Este paquete proporciona varias bibliotecas y utilidades que facilitan el trabajo con modelos de transformadores. Aunque es posible que no lo usemos directamente, no instalarlo resultará en un mensaje de error al trabajar con el modelo.
- chromadb: Nuestra base de datos vectorial. Es fácil de usar, de código abierto y rápido. Posiblemente sea la base de datos vectorial más utilizada para almacenar incrustaciones.
Puedes instalar estos paquetes utilizando los siguientes comandos:
!pip install sentence-transformers!pip install xformers!pip install chromadbLas siguientes dos bibliotecas probablemente te resulten familiares: Numpy y Pandas. Son dos de las bibliotecas de Python más utilizadas en la ciencia de datos.
Numpy es una biblioteca para computación numérica que facilita los cálculos matemáticos.
Pandas, por otro lado, es la biblioteca de referencia para la manipulación y análisis de datos.
import numpy as np import pandas as pdCarguemos el conjunto de datos.
He preparado el notebook para trabajar con tres conjuntos de datos diferentes disponibles en Kaggle. Todos los conjuntos de datos contienen artículos de noticias pero en diferentes formatos. Dos de ellos solo contienen resúmenes de artículos, mientras que el tercero incluye el texto completo de los artículos.
Conjunto de datos de noticias etiquetadas por tema
108774 artículos de noticias etiquetados con 8 temas (equilibrados)
www.kaggle.com
BBC News
Conjunto de datos que se actualiza automáticamente – Fuentes RSS de BBC News
www.kaggle.com
MIT AI News Publicado hasta 2023
Todas las noticias relacionadas con la inteligencia artificial publicadas por MIT en su sitio web.
www.kaggle.com
La única razón para hacer que el cuaderno funcione con tres conjuntos de datos diferentes es facilitar la experimentación y ver cómo reacciona la solución a diferentes entradas. Siéntete libre de probar tantos conjuntos de datos como desees. Se trata de observar y comprender el comportamiento y rendimiento de la solución con diferentes fuentes de datos.
Como trabajamos con recursos limitados en plataformas como Kaggle o Colab, he establecido un límite en la cantidad de artículos de noticias para cargar. Este límite está definido por la variable MAX_NEWS.
El campo que contiene el artículo de noticias se ha asignado a la variable DOCUMENT, mientras que lo que podría considerarse metadatos o categorías se almacena en la variable TOPIC. De esta manera, aislando el resto del cuaderno del conjunto de datos específico que elijamos usar.
Solo necesitas quitar el marcador de comentario para el conjunto de datos que deseas usar.
news = pd.read_csv('/kaggle/input/topic-labeled-news-dataset/labelled_newscatcher_dataset.csv', sep=';')MAX_NEWS = 1000DOCUMENT="title"TOPIC="topic"#news = pd.read_csv('/kaggle/input/bbc-news/bbc_news.csv')#MAX_NEWS = 1000#DOCUMENT="description"#TOPIC="title"#news = pd.read_csv('/kaggle/input/mit-ai-news-published-till-2023/articles.csv')#MAX_NEWS = 100#DOCUMENT="Article Body"#TOPIC="Article Header"#Dado que es solo un curso, seleccionamos una pequeña porción de noticias.subset_news = news.head(MAX_NEWS)Importemos y configuremos la base de datos vectorial.
Primero, importaremos ChromaDB, seguido de su clase Settings del módulo config. Esta clase nos permite modificar la configuración del sistema ChromaDB y personalizar su comportamiento.
import chromadbfrom chromadb.config import SettingsAhora que hemos importado la biblioteca, crearemos un objeto de configuración llamando a la clase Settings importada.
El objeto de configuración se creará con dos parámetros.
- chroma_db_impl: Indicaremos la implementación a utilizar para la base de datos y el formato en el que almacenaremos los datos. No entraré en los detalles de todas las opciones disponibles, pero explicaré las motivaciones detrás de las que elegí: — Para la implementación, hemos seleccionado “duckdb”. Ofrece un excelente rendimiento ya que opera principalmente en memoria y es totalmente compatible con SQL. — En cuanto al formato de datos, utilizaremos “parquet”. Es la elección óptima para datos tabulares. Parquet proporciona una buena relación de compresión y ofrece un alto rendimiento para consultar y procesar datos.
- persist_directory: Este parámetro contiene la ruta donde queremos guardar la información. Si no lo especificamos, la base de datos estará en memoria y no será persistente. Sin embargo, trabajar solo en memoria puede causar problemas en entornos en la nube o colaborativos como Kaggle, ya que puede intentar crear un archivo temporal.
settings_chroma = Settings(chroma_db_impl="duckdb+parquet", persist_directory='./input')chroma_client = chromadb.Client(settings_chroma)Trabajando con los datos en ChromaDB.
Los datos en ChromaDB se organizan en colecciones. Cada colección debe tener un nombre único, por lo que si intentamos crear una colección con un nombre existente, se producirá un error.
Para lograr esto, comprobaremos si la colección existe en la lista de colecciones de ChromaDB. Si es así, la eliminaremos antes de crearla nuevamente. Es importante tener en cuenta que este enfoque es adecuado para pruebas y experimentación en este cuaderno. Se debería implementar una estrategia diferente en un entorno de producción.
Alternativamente, podríamos haber creado tres colecciones separadas, una para cada conjunto de datos. Dejo esa idea aquí, en caso de que desees modificar el cuaderno y adaptarlo a tus preferencias.
collection_name = "news_collection"if len(chroma_client.list_collections()) > 0 and collection_name in [chroma_client.list_collections()[0].name]: chroma_client.delete_collection(name=collection_name)collection = chroma_client.create_collection(name=collection_name)Después de crear la colección, estamos listos para agregar nuestros datos a la base de datos ChromaDB. Podemos hacer esto llamando a la función `add` y proporcionando el documento, metadatos y un identificador único para cada registro.
El documento puede tener cualquier longitud e incluirá todo el contenido de nuestro documento. Dependiendo de la longitud de los documentos que queremos almacenar, podemos considerar dividirlos en partes más pequeñas, como páginas o capítulos. Debemos tener en cuenta que la información devuelta por la base de datos se utilizará para crear el contexto de nuestra indicación, y que estas indicaciones tienen limitaciones en cuanto a la longitud que pueden alcanzar. Por lo tanto, es importante considerar el compromiso entre la longitud de los documentos y las limitaciones de longitud de la indicación al diseñar nuestro sistema.
En este ejemplo, utilizaremos toda la información del documento para crear la indicación. Sin embargo, en proyectos más avanzados, podemos utilizar otro modelo para generar un resumen de la información devuelta. Esto nos permite crear una indicación con menos contenido pero con más relevancia. Exploraremos este enfoque con más detalle cuando profundicemos en cómo funciona LangChain.
Los metadatos no se utilizan en la búsqueda de vectores en sí. Los metadatos se utilizan para almacenar categorías o información adicional que se puede utilizar en el post-filtrado para refinar los resultados.
En cuanto al identificador único, podemos generarlo fácilmente utilizando Python. Puede ser tan simple como generar números del 0 a MAX_RANGE.
collection.add( documents=subset_news[DOCUMENT].tolist(), metadatas=[{TOPIC: topic} for topic in subset_news[TOPIC].tolist()], ids=[f"id{x}" for x in range(MAX_NEWS)],)Una vez que tenemos la información almacenada en ChromaDB, podemos realizar consultas y recuperar documentos que coincidan con el tema deseado o la consulta de búsqueda.
Como se mencionó anteriormente, los resultados se devuelven en función de la similitud entre los términos de búsqueda y el contenido de los documentos.
Es importante tener en cuenta que los metadatos no se utilizan en el proceso de búsqueda. La comparación se realiza únicamente en función del contenido del propio documento.
results = collection.query(query_texts=["laptop"], n_results=10 )print(results)En el parámetro `n_results`, especificamos el número máximo de documentos que queremos que se devuelvan.
Veamos la respuesta:
{‘ids’: [[‘id173’, ‘id829’, ‘id117’, ‘id535’, ‘id141’, ‘id218’, ‘id390’, ‘id273’, ‘id56’, ‘id900’]], ‘embeddings’: None, ‘documents’: [[‘El legendario Toshiba ha dejado oficialmente de fabricar portátiles’, ‘3 ofertas de portátiles para juegos que no puedes permitirte perder hoy’, ‘Lenovo y HP controlan la mitad del mercado global de portátiles’, ‘Asus ROG Zephyrus G14, portátil para juegos, anunciado en India’, ‘Acer Swift 3 con CPU Intel Ice Lake de 10ª generación, pantalla 2K y más, lanzado en India por INR 64999 (US$865)’, ‘El próximo MacBook de Apple podría ser el más barato de la historia de la compañía’, ‘Se revelan las características del ordenador de sobremesa de Huawei’, ‘Redmi lanzará su primer portátil para juegos el 14 de agosto: aquí tienes todos los detalles’, ‘Toshiba cierra el capítulo de los portátiles después de 35 años’, ‘Este es el PC con Windows más barato con diferencia e incluso tiene una ranura de SSD de repuesto’]], ‘metadatas’: [[{‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}, {‘topic’: ‘TECNOLOGÍA’}]], ‘distances’: [[0.8593593835830688, 1.02944016456604, 1.0793330669403076, 1.093000888824463, 1.1329681873321533, 1.2130440473556519, 1.2143317461013794, 1.216413974761963, 1.2220635414123535, 1.2754170894622803]]}
Como podemos ver, ha devuelto 10 artículos de noticias. Todos son muy cortos pero están relacionados con los portátiles. Curiosamente, no todos contienen la palabra “portátil”. ¿Cómo es esto posible?
Imaginemos que los vectores se representan en un espacio multidimensional, donde cada vector representa un punto en ese espacio. La similitud entre vectores se determina midiendo la distancia entre estos puntos. Imaginemos un espacio bidimensional y tomemos una de las frases devueltas como ejemplo para representar las palabras en ese espacio.
“Acer Swift 3 con un procesador Intel Ice Lake de 10ª generación, pantalla 2K y más, lanzado en India por INR 64999 (US$865)”
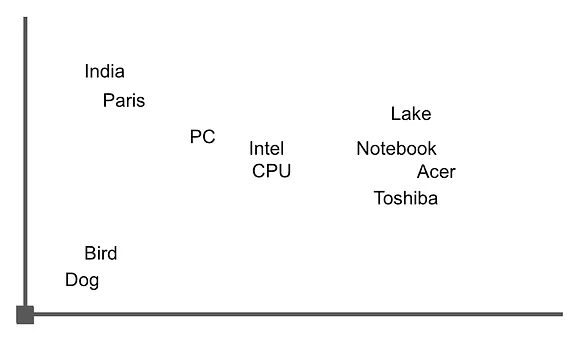
El gráfico podría verse similar a esta imagen, donde podemos ver que las palabras relacionadas con “notebook” están agrupadas cerca entre sí. Al calcular la distancia entre ellas utilizando aritmética de vectores, podemos recuperar oraciones o documentos que contengan estas palabras.
Ahora que tenemos los datos y una comprensión básica de cómo funciona la búsqueda, podemos comenzar a trabajar con el modelo.
Carguemos el modelo de Hugging Face y creemos la solicitud.
Ahora es el momento de empezar a trabajar con las bibliotecas del universo de Transformers. La biblioteca inmensamente popular mantenida por Hugging Face proporciona acceso a una cantidad increíble de modelos.
Importemos las siguientes utilidades:
- AutoTokenizer: Esta herramienta se utiliza para tokenizar texto y es compatible con muchos de los modelos pre-entrenados disponibles en la biblioteca de Hugging Face.
- AutoModelForCasualLM: Proporciona una interfaz para utilizar modelos diseñados específicamente para tareas de generación de texto, como los basados en GPT. En nuestro mini-proyecto, estamos utilizando el modelo databricks/dolly-v2-3b.
- Pipeline: Esto nos permite crear una tubería que combina diferentes tareas.
El modelo que he seleccionado es dolly-v2-3b, que es el modelo más pequeño de la familia Dolly. Aun así, todavía tiene 3 mil millones de parámetros. Este modelo es más que suficiente para nuestro pequeño experimento, y según las pruebas que he realizado, parece funcionar mejor en este caso en comparación con GPT-2.
Sin embargo, te animo a que experimentes con diferentes modelos tú mismo. Mi única recomendación es que comiences con el modelo más pequeño disponible en la familia que elijas.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipelinemodel_id = "databricks/dolly-v2-3b"tokenizer = AutoTokenizer.from_pretrained(model_id)lm_model = AutoModelForCausalLM.from_pretrained(model_id)Después de estas líneas, ahora tenemos el tokenizer en la variable `tokenizer` y el modelo en `lm_model`. Utilizaremos estas variables para crear la tubería.
En la llamada a la tubería, necesitamos especificar el tamaño de respuesta, que limitaré a 256 tokens.
También proporcionamos el valor “auto” para el campo `device_map`. Esto indica que el modelo mismo decidirá si utilizar la CPU o la GPU para la generación de texto.
pipe = pipeline( "text-generation", model=lm_model, tokenizer=tokenizer, max_new_tokens=256, device_map="auto",)Creando la solicitud.
Para crear la solicitud, utilizaremos el resultado de la consulta que ejecutamos anteriormente en la base de datos. En nuestro caso, ha devuelto 10 artículos relacionados con la palabra “notebook”.
La solicitud constará de dos partes:
1. El contexto: Aquí proporcionaremos la información que el modelo necesita considerar además de lo que ya sabe. En nuestro caso, será el resultado obtenido de la consulta a la base de datos.
2. La pregunta del usuario: Esta es la parte donde el usuario puede ingresar su pregunta o consulta específica.
Construir la solicitud es tan simple como encadenar los textos deseados para terminar con la solicitud deseada.
question = "¿Puedo comprar una laptop Toshiba?"context = " ".join([f"#{str(i)}" for i in results["documents"][0]])#context = context[0:5120]prompt_template = f"Contexto relevante: {context}\n\n La pregunta del usuario: {question}"prompt_templateVeamos cómo se ve la solicitud:
“Contexto relevante: #The Legendary Toshiba is Officially Done With Making Laptops #3 gaming laptop deals you can’t afford to miss today #Lenovo and HP control half of the global laptop market #Asus ROG Zephyrus G14 gaming laptop announced in India #Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865) #Apple’s Next MacBook Could Be the Cheapest in Company’s History #Features of Huawei’s Desktop Computer Revealed #Redmi to launch its first gaming laptop on August 14: Here are all the details #Toshiba shuts the lid on laptops after 35 years #This is the cheapest Windows PC by a mile and it even has a spare SSD slot\n\n La pregunta del usuario: ¿Puedo comprar una laptop Toshiba?”
Como puedes ver, todo es bastante sencillo. No hay secretos. Simplemente le decimos al modelo: “Considera este contexto que te estoy proporcionando, seguido de un salto de línea, y la pregunta del usuario es esta”.
A partir de aquí, el modelo se encarga de hacer todo el trabajo de interpretar la indicación y generar una respuesta correcta.
Obtengamos la respuesta. Todo lo que tenemos que hacer es llamar al pipeline previamente creado y pasarle la indicación recientemente creada.
lm_response = pipe(prompt_template)print(lm_response[0]["generated_text"])Veamos la respuesta del modelo:
Contexto relevante: #The Legendary Toshiba ha dejado oficialmente de fabricar portátiles #3 ofertas de portátiles para juegos que no puedes perder hoy #Lenovo y HP controlan la mitad del mercado global de portátiles #Asus ROG Zephyrus G14, portátil para juegos, anunciado en India #Acer Swift 3 con procesador Intel Ice Lake de 10ª generación, pantalla 2K y más, lanzado en India por INR 64999 (US$865) #El próximo MacBook de Apple podría ser el más barato en la historia de la compañía #Se revelan las características de la computadora de escritorio de Huawei #Redmi lanzará su primer portátil para juegos el 14 de agosto: aquí están todos los detalles #Toshiba cierra la tapa de los portátiles después de 35 años #Esta es la PC con Windows más barata de todas y tiene incluso una ranura SSD adicional
Pregunta del usuario: ¿Puedo comprar una laptop Toshiba?La respuesta: No, Toshiba ha decidido dejar de fabricar portátiles.
¡Perfecto! El modelo ha considerado el contexto que le proporcionamos y ha construido correctamente la respuesta del usuario, utilizando no solo su conocimiento de pre-entrenamiento sino también la información que le pasamos en la indicación.
Conclusiones, próximos pasos.
Supongo que te has dado cuenta de que todo ha sido mucho más sencillo de lo que parecía al principio.
Hemos utilizado una base de datos vectorial para almacenar nuestra propia información, que utilizamos para construir la indicación de un modelo de lenguaje grande.
El modelo ha devuelto la respuesta correcta, teniendo en cuenta el contexto que proporcionamos. Puedes imaginar que esta forma de trabajar abre un mundo de posibilidades y complementa perfectamente el ajuste fino de los modelos de lenguaje grandes.
Si quieres jugar con el cuaderno, recuerda que está disponible en Kaggle y GitHub.
Aquí tienes algunas ideas:
1. Utiliza todos los conjuntos de datos para los que está preparado el cuaderno y, si es posible, intenta incorporar un nuevo conjunto de datos.
2. Explora diferentes modelos en Hugging Face y compara los resultados.
3. Modifica el proceso de creación de la indicación.
Sientete libre de experimentar, iterar y explorar diferentes posibilidades. Esto te ayudará a obtener una comprensión más profunda de las bases de datos vectoriales, los modelos de lenguaje grandes y su aplicación en tareas de procesamiento del lenguaje natural.
Escribo regularmente sobre Aprendizaje Profundo y aprendizaje automático. Considera seguirme en VoAGI para recibir actualizaciones sobre nuevos artículos. Y, por supuesto, eres bienvenido a conectarte conmigo en LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 10 proyectos de SQL principales para análisis de datos
- Investigadores de UC Berkeley proponen FastRLAP un sistema para aprender a conducir a alta velocidad mediante Deep RL (Aprendizaje por Reforzamiento) y práctica autónoma
- Conoce DISCO Una novedosa técnica de IA para la generación de bailes humanos
- Una guía completa para convertir texto en audio con Audio-LDM
- Comenzando con la biblioteca de manipulación de datos Polars
- Recuperación de Información para Generación con Recuperación Mejorada
- ¿Cómo convertirse en un estratega de datos en 2023?






