Aprovechando los LLM con Recuperación de Información Una Demostración Simple
Aprovechando LLM con Recuperación de Información - Demostración Simple
Una demostración de integración de un LLM de pregunta-respuesta con componentes de recuperación

Los modelos de lenguaje grandes (LLM) pueden almacenar una cantidad impresionante de datos factuales, pero sus capacidades están limitadas por el número de parámetros. Además, actualizar frecuentemente un LLM es costoso, mientras que los datos de entrenamiento antiguos pueden hacer que el LLM produzca respuestas desactualizadas.
Para abordar el problema anterior, podemos mejorar un LLM con herramientas externas. En este artículo, compartiré cómo integrar un LLM con componentes de recuperación para mejorar el rendimiento.
Recuperación mejorada (RA)
Un componente de recuperación puede proporcionar al LLM conocimientos más actualizados y precisos. Dado el input x, queremos predecir la salida p(y|x). A partir de una fuente de datos externa R, recuperamos una lista de contextos z=(z_1, z_2,..,z_n) relevantes para x. Podemos unir x y z y aprovechar toda la información valiosa de z para predecir p(y|x,z). Además, mantener actualizada la fuente de datos R también es mucho más económico.
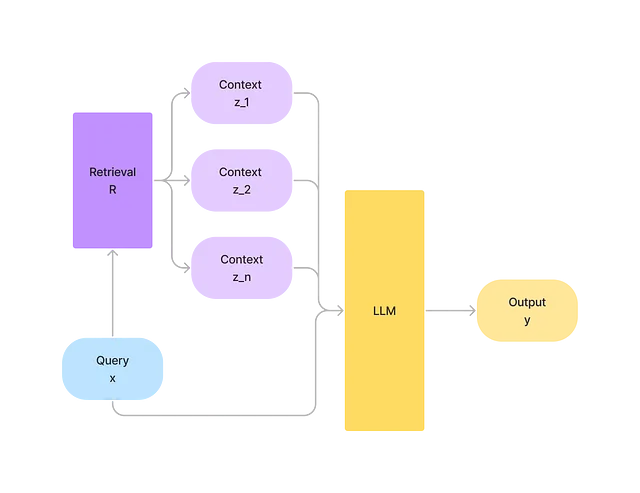
Demostración de Pregunta-Respuesta usando datos de Wikipedia + ChatGPT
En esta demostración, para una pregunta dada, realizamos los siguientes pasos:
- Cómo acelerar la inferencia hasta 9 veces en una CPU x86 con Pytorch
- Dentro de XGen-Imagen-1 Cómo Salesforce Research construyó, entrenó y evaluó un modelo masivo de texto a imagen.
- Anthropic recibe un impulso de $100 millones de SK Telecom para avanzar en la IA específica de las telecomunicaciones
- Recuperar documentos de Wikipedia relacionados con la pregunta.
- Proporcionar tanto la pregunta como la Wikipedia a ChatGPT.
Queremos comparar y ver cómo el contexto adicional afecta las respuestas de ChatGPT.
Conjunto de datos
Para el conjunto de datos de Wikipedia, podemos extraerlo de aquí. Utilizo el subconjunto “20220301.simple” con más de 200 mil documentos. Debido al límite de longitud del contexto, solo utilizo el título y la parte del resumen. Para cada documento, también agrego un ID de documento para el propósito de recuperación posterior. Por lo tanto, los ejemplos de datos se ven así.
{"title": "April", "doc": "April es el cuarto mes del año en los calendarios juliano y gregoriano, y se encuentra entre marzo y mayo. Es uno de los cuatro meses que tienen 30 días.", "id": 0}{"title": "August", "doc": "Augusto (Aug.) es el octavo mes del año en el calendario gregoriano, que viene entre julio y...We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Bases de datos de vectores y índices de vectores en Python Arquitectura de aplicaciones LLM
- 4 Recursos Esenciales para Ayudar a Mejorar tus Visualizaciones de Datos
- Traducción de imagen a imagen con CycleGAN
- Gira y Enfrenta lo Extraño
- Análisis y optimización del rendimiento del modelo PyTorch – Parte 3
- Clasificación de texto con codificadores de Transformer
- Transformada de Fourier para series de tiempo descomposición de tendencia





