Aprendizaje profundo para objetos profundos ZoeDepth es un modelo de IA para la estimación de profundidad en múltiples dominios
Aprendizaje profundo para objetos profundos ZoeDepth es un modelo de IA para estimar profundidad en múltiples dominios.


¿Alguna vez te has encontrado con ilusiones en las que un niño en la imagen parece más alto y más grande que un adulto? La ilusión de la habitación de Ames es una famosa que involucra una habitación con forma de trapezoide, con una esquina de la habitación más cercana al espectador que la otra esquina. Cuando lo miras desde cierto punto, los objetos en la habitación se ven normales, pero al moverte a una posición diferente, todo cambia de tamaño y forma, y puede ser difícil entender qué está cerca de ti y qué no.
Aunque esto es un problema para nosotros los humanos. Normalmente, cuando miramos una escena, estimamos la profundidad de los objetos con bastante precisión si no hay trucos de ilusión. Sin embargo, las computadoras, por otro lado, no tienen tanto éxito en la estimación de la profundidad, ya que todavía es un problema fundamental en la visión por computadora.
La Estimación de la Profundidad es el proceso de determinar la distancia entre la cámara y los objetos en la escena. Los algoritmos de estimación de profundidad toman una imagen o una secuencia de imágenes como entrada y generan un mapa de profundidad correspondiente o una representación 3D de la escena. Esta es una tarea importante, ya que necesitamos entender la profundidad de la escena en numerosas aplicaciones como robótica, vehículos autónomos, realidad virtual, realidad aumentada, etc. Por ejemplo, si quieres tener un automóvil autónomo seguro, entender la distancia al automóvil que tienes delante es crucial para ajustar la velocidad de conducción.
- FedML y Theta presentan un superclúster de IA descentralizada impulsando la IA generativa y la recomendación de contenido
- De SQL a Julia Otros lenguajes de programación en Ciencia de Datos
- Amazon lanza HealthScribe, una nueva herramienta de IA generativa para resumir las visitas de los médicos y gestionar archivos
Existen dos ramas de algoritmos de estimación de profundidad, estimación métrica de profundidad (MDE), donde el objetivo es estimar la distancia absoluta, y estimación de profundidad relativa (RDE), donde el objetivo es estimar la distancia relativa entre los objetos en la escena.

Los modelos de MDE son útiles para mapeo, planificación, navegación, reconocimiento de objetos, reconstrucción 3D y edición de imágenes. Sin embargo, el rendimiento de los modelos de MDE puede deteriorarse al entrenar un solo modelo en múltiples conjuntos de datos, especialmente si las imágenes tienen grandes diferencias en la escala de profundidad (por ejemplo, imágenes de interiores y exteriores). Como resultado, los modelos de MDE actuales a menudo se ajustan demasiado a conjuntos de datos específicos y no se generalizan bien a otros conjuntos de datos.
Los modelos de RDE, por otro lado, utilizan la disparidad como medio de supervisión. Las predicciones de profundidad en RDE solo son consistentes entre sí en los cuadros de imagen, y el factor de escala es desconocido. Esto permite que los métodos de RDE se entrenen en un conjunto diverso de escenas y conjuntos de datos, incluso incluyendo películas en 3D, lo que puede ayudar a mejorar la capacidad de generalización del modelo en diferentes dominios. Sin embargo, el inconveniente es que la profundidad predicha en RDE no tiene un significado métrico, lo que limita sus aplicaciones.
¿Qué sucedería si combinamos estos dos enfoques? Podríamos tener un modelo de estimación de profundidad que se generalice bien a diferentes dominios mientras mantiene una escala métrica precisa. Esto es exactamente lo que ha logrado ZoeDepth.
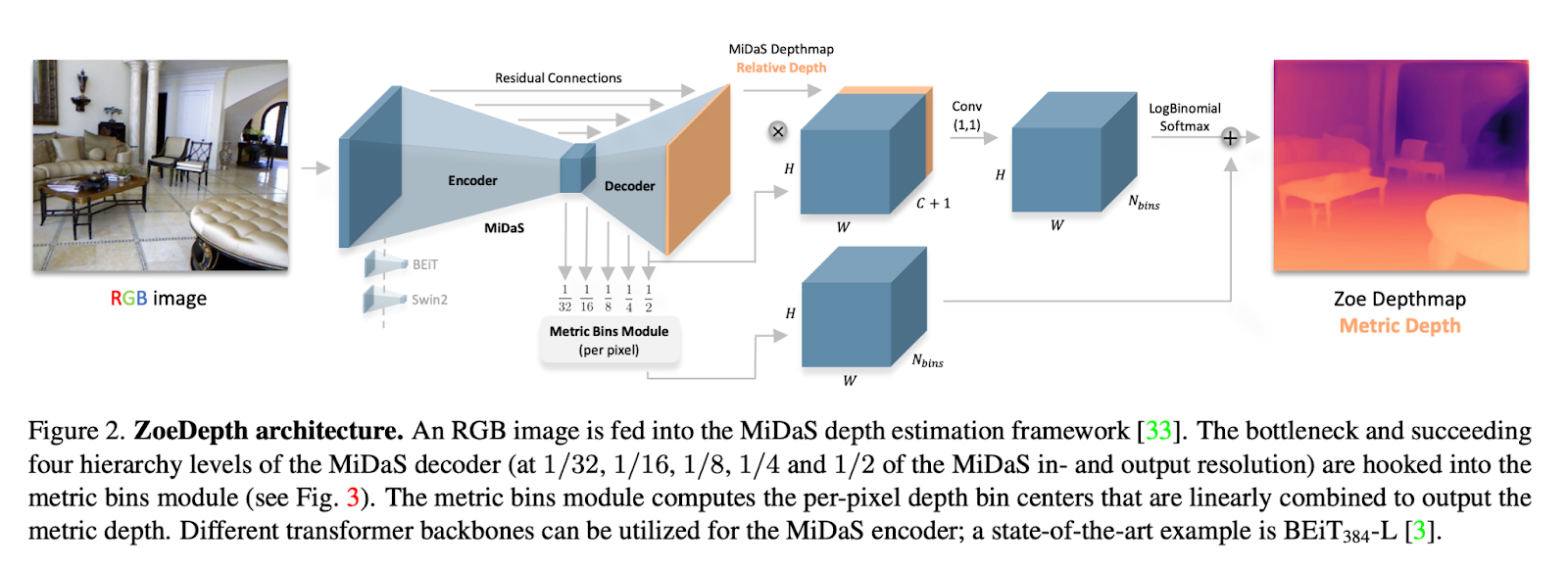
ZoeDepth es un marco de dos etapas que combina los enfoques de MDE y RDE. La primera etapa consta de una estructura codificador-decodificador que se entrena para estimar profundidades relativas. Este modelo se entrena en una gran variedad de conjuntos de datos, lo que mejora la generalización. La segunda etapa agrega componentes responsables de estimar la profundidad métrica como una cabeza adicional.
El diseño de la cabeza métrica utilizado en este enfoque se basa en un método llamado módulo de bins métricos, que estima un conjunto de valores de profundidad para cada píxel en lugar de un solo valor de profundidad. Esto permite que el modelo capture un rango de posibles valores de profundidad para cada píxel, lo que puede ayudar a mejorar su precisión y robustez. Esto permite una medición precisa de la profundidad que considera la distancia física entre objetos en la escena. Estas cabezas se entrenan en conjuntos de datos de profundidad métrica y son más livianas en comparación con la primera etapa.
En cuanto a la inferencia, un modelo clasificador selecciona la cabeza adecuada para cada imagen utilizando características del codificador. Esto permite que el modelo se especialice en estimar la profundidad para dominios o tipos de escenas específicas, al tiempo que se beneficia del preentrenamiento de profundidad relativa. Al final, obtenemos un modelo flexible que se puede usar en múltiples configuraciones.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Análisis geoespacial para la resiliencia ante inundaciones
- Prepárate y juega ‘Remnant II’ de Gearbox en streaming en GeForce NOW
- Dra. Eva-Marie Muller-Stuler sobre la importancia de adoptar prácticas éticas en IA y Ciencia de Datos
- El Futuro del Desarrollo Web Predicciones y Posibilidades
- Amazon Vs Google Vs Microsoft La carrera para revolucionar la atención médica con IA
- Spotify adopta la IA desde listas de reproducción personalizadas hasta anuncios de audio
- Construyendo aplicaciones de IA generativa con LangChain y OpenAI API





