Ilustrando el Aprendizaje por Reforzamiento a través de la Retroalimentación Humana (RLHF)
Aprendizaje por Reforzamiento a través de Retroalimentación Humana (RLHF)
Este artículo ha sido traducido al chino simplificado 简体中文 y al vietnamita đọc tiếng việt. ¿Estás interesado en traducir a otro idioma? Contacta a Nathan en huggingface.co.
En los últimos años, los modelos de lenguaje han demostrado impresionantes capacidades al generar texto diverso y convincente a partir de indicaciones de entrada humanas. Sin embargo, lo que hace que un texto sea “bueno” es inherentemente difícil de definir, ya que es subjetivo y depende del contexto. Hay muchas aplicaciones, como escribir historias donde se busca la creatividad, fragmentos de texto informativo que deben ser verídicos o fragmentos de código que queremos que sean ejecutables.
Crear una función de pérdida para capturar estas características parece inabordable y la mayoría de los modelos de lenguaje aún se entrenan con una simple pérdida de predicción del siguiente token (por ejemplo, entropía cruzada). Para compensar las limitaciones de la propia pérdida, las personas definen métricas que están diseñadas para capturar mejor las preferencias humanas, como BLEU o ROUGE. Aunque son más adecuadas que la función de pérdida misma para medir el rendimiento, estas métricas simplemente comparan el texto generado con referencias utilizando reglas simples y, por lo tanto, también son limitadas. ¿No sería genial si usamos la retroalimentación humana para el texto generado como una medida de rendimiento o incluso vamos un paso más allá y usamos esa retroalimentación como una pérdida para optimizar el modelo? Esa es la idea del Aprendizaje por Reforzamiento a partir de la Retroalimentación Humana (RLHF por sus siglas en inglés); utilizar métodos de aprendizaje por refuerzo para optimizar directamente un modelo de lenguaje con retroalimentación humana. RLHF ha permitido que los modelos de lenguaje comiencen a alinearse con los valores humanos complejos en un corpus general de datos de texto.
El éxito más reciente de RLHF fue su uso en ChatGPT. Dado las impresionantes habilidades de ChatGPT, le pedimos que nos explique RLHF:
- Una Guía Completa de Conjuntos de Datos de Audio
- ¡Hablemos de sesgos en el aprendizaje automático! Boletín de Ética y Sociedad #2
- Segmentación de imágenes sin entrenamiento previo con CLIPSeg
Lo hace sorprendentemente bien, pero no cubre todo. ¡Vamos a llenar esos vacíos!
El aprendizaje por refuerzo a partir de la retroalimentación humana (también conocido como RL a partir de las preferencias humanas) es un concepto desafiante porque implica un proceso de entrenamiento de múltiples modelos y diferentes etapas de implementación. En esta publicación de blog, desglosaremos el proceso de entrenamiento en tres pasos fundamentales:
- Preentrenar un modelo de lenguaje (LM por sus siglas en inglés),
- recopilar datos y entrenar un modelo de recompensa, y
- ajustar finamente el LM con aprendizaje por refuerzo.
Para comenzar, veremos cómo se preentrenan los modelos de lenguaje.
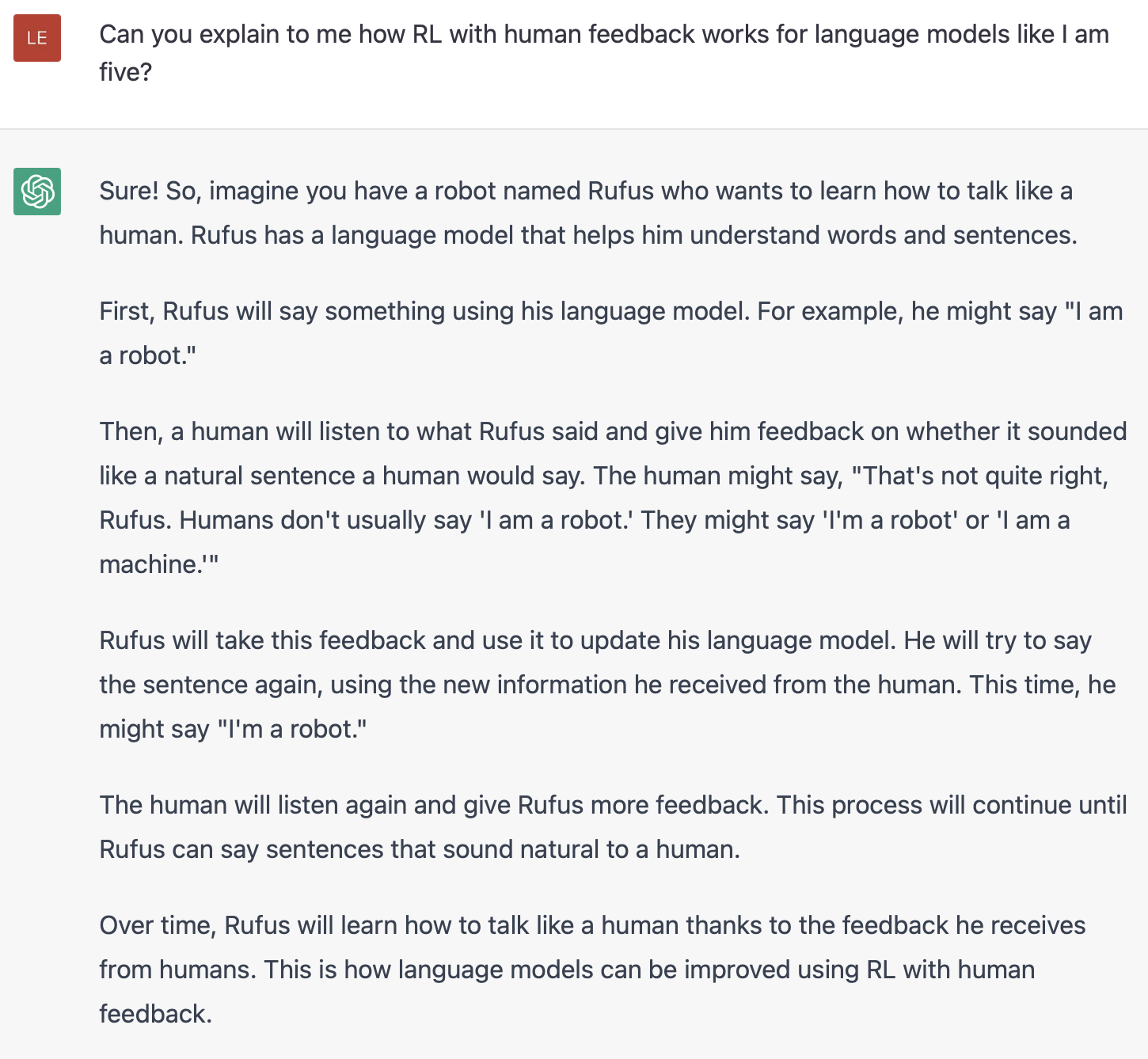
Preentrenamiento de modelos de lenguaje
Como punto de partida, RLHF utiliza un modelo de lenguaje que ya ha sido preentrenado con objetivos de preentrenamiento clásicos (consulta esta publicación de blog para obtener más detalles). OpenAI utilizó una versión más pequeña de GPT-3 para su primer modelo RLHF popular, InstructGPT. Anthropic utilizó modelos transformer desde 10 millones hasta 52 mil millones de parámetros entrenados para esta tarea. DeepMind utilizó su modelo Gopher de 280 mil millones de parámetros.
Este modelo inicial también se puede ajustar finamente en texto o condiciones adicionales, pero no necesariamente es necesario hacerlo. Por ejemplo, OpenAI ajustó finamente en texto generado por humanos que era “preferible” y Anthropic generó su LM inicial para RLHF destilando un LM original en pistas de contexto para sus criterios de “útil, honesto e inofensivo”. Ambas son fuentes de lo que yo llamo datos costosos y aumentados, pero no es una técnica requerida para comprender RLHF.
En general, no hay una respuesta clara sobre “qué modelo” es el mejor como punto de partida para RLHF. Este será un tema común en este blog: el espacio de diseño de opciones en el entrenamiento de RLHF no está completamente explorado.
A continuación, con un modelo de lenguaje, es necesario generar datos para entrenar un modelo de recompensa, que es cómo se integran las preferencias humanas en el sistema.
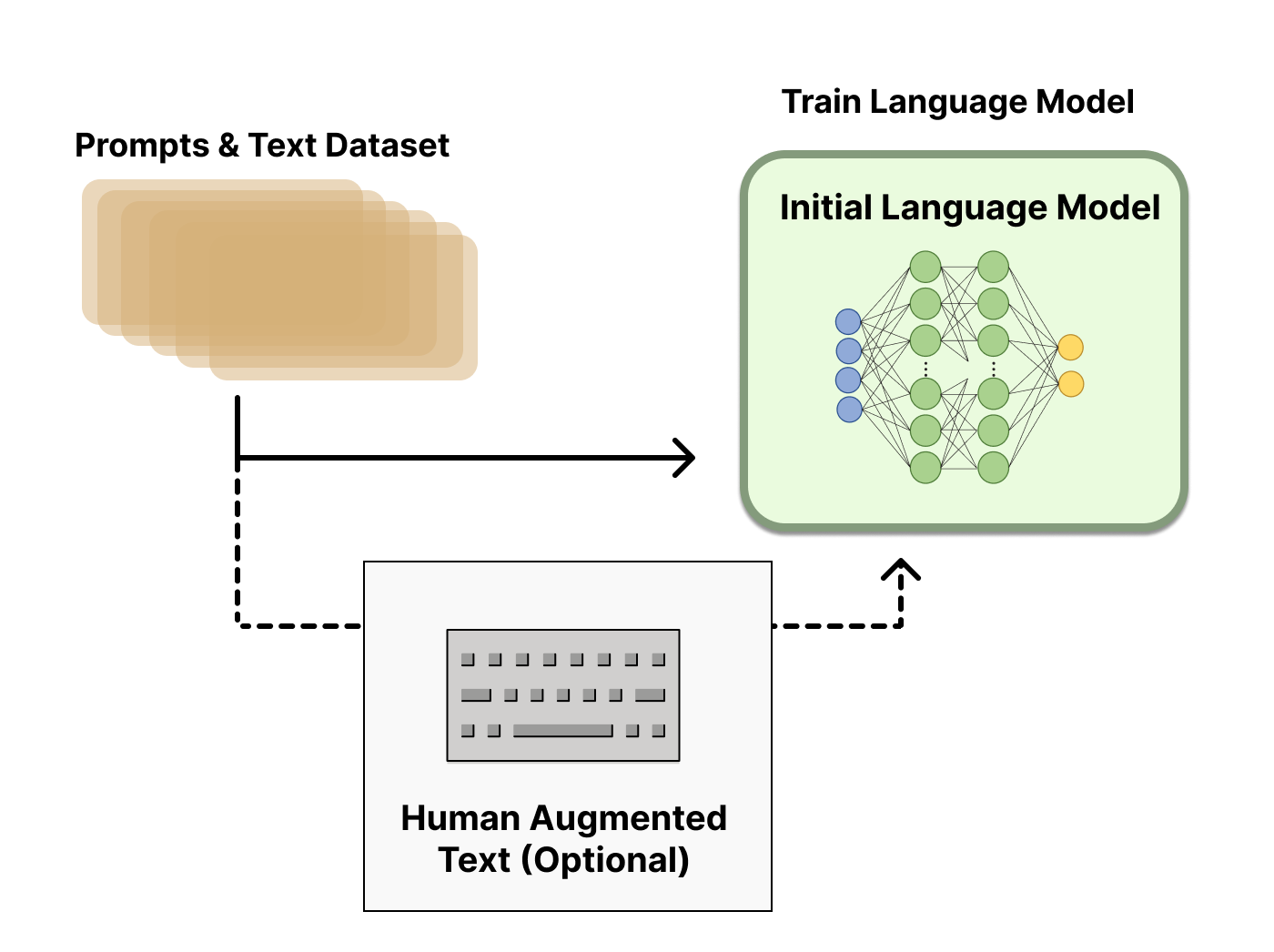
Entrenamiento del modelo de recompensa
Generar un modelo de recompensa (RM, también conocido como modelo de preferencia) calibrado con las preferencias humanas es donde comienza la investigación relativamente nueva en RLHF. El objetivo subyacente es obtener un modelo o sistema que tome una secuencia de texto y devuelva una recompensa escalar que represente numéricamente la preferencia humana. El sistema puede ser un LM de extremo a extremo o un sistema modular que produce una recompensa (por ejemplo, un modelo clasifica las salidas y la clasificación se convierte en recompensa). Que la salida sea una recompensa escalar es crucial para que los algoritmos de RL existentes se integren sin problemas en la etapa posterior del proceso de RLHF.
Estos LMs para la modelización de recompensas pueden ser otro LM afinado o un LM entrenado desde cero en los datos de preferencia. Por ejemplo, Anthropic utiliza un método especializado de afinamiento fino para inicializar estos modelos después del preentrenamiento (preentrenamiento del modelo de preferencia, PMP) porque encontraron que es más eficiente en términos de muestras que el afinamiento fino, pero ninguna variación de la modelización de recompensas se considera la mejor opción clara hoy en día.
El conjunto de datos de entrenamiento de pares de generación de indicaciones para el RM se genera muestreando un conjunto de indicaciones de un conjunto de datos predefinido (los datos de Anthropic generados principalmente con una herramienta de chat en Amazon Mechanical Turk están disponibles en el Hub, y OpenAI utilizó indicaciones enviadas por los usuarios a la API de GPT). Las indicaciones se pasan a través del modelo de lenguaje inicial para generar nuevo texto.
Se utilizan anotadores humanos para clasificar las salidas de texto generadas por el LM. Uno podría pensar inicialmente que los humanos deberían aplicar una puntuación escalar directamente a cada fragmento de texto para generar un modelo de recompensa, pero esto es difícil de hacer en la práctica. Los valores diferentes de los humanos hacen que estas puntuaciones no estén calibradas y sean ruidosas. En su lugar, se utilizan clasificaciones para comparar las salidas de múltiples modelos y crear un conjunto de datos mucho mejor regularizado.
Existen múltiples métodos para clasificar el texto. Un método que ha tenido éxito es que los usuarios comparen el texto generado por dos modelos de lenguaje condicionados a la misma indicación. Al comparar las salidas de los modelos en enfrentamientos directos, se puede utilizar un sistema Elo para generar una clasificación de los modelos y las salidas en relación entre sí. Estos diferentes métodos de clasificación se normalizan en una señal de recompensa escalar para el entrenamiento.
Un aspecto interesante de este proceso es que los sistemas exitosos de RLHF hasta la fecha han utilizado modelos de lenguaje de recompensa con tamaños variables en relación con la generación de texto (por ejemplo, OpenAI 175B LM, modelo de recompensa de 6B, Anthropic utilizó LM y modelos de recompensa de 10B a 52B, DeepMind utiliza modelos Chinchilla de 70B tanto para LM como para recompensa). La intuición sería que estos modelos de preferencia deben tener una capacidad similar para comprender el texto que se les da como la que necesitaría un modelo para generar dicho texto.
En este punto del sistema RLHF, tenemos un modelo de lenguaje inicial que se puede utilizar para generar texto y un modelo de preferencia que recibe cualquier texto y le asigna una puntuación en función de la percepción humana. A continuación, utilizamos aprendizaje por refuerzo (RL) para optimizar el modelo de lenguaje original en función del modelo de recompensa.
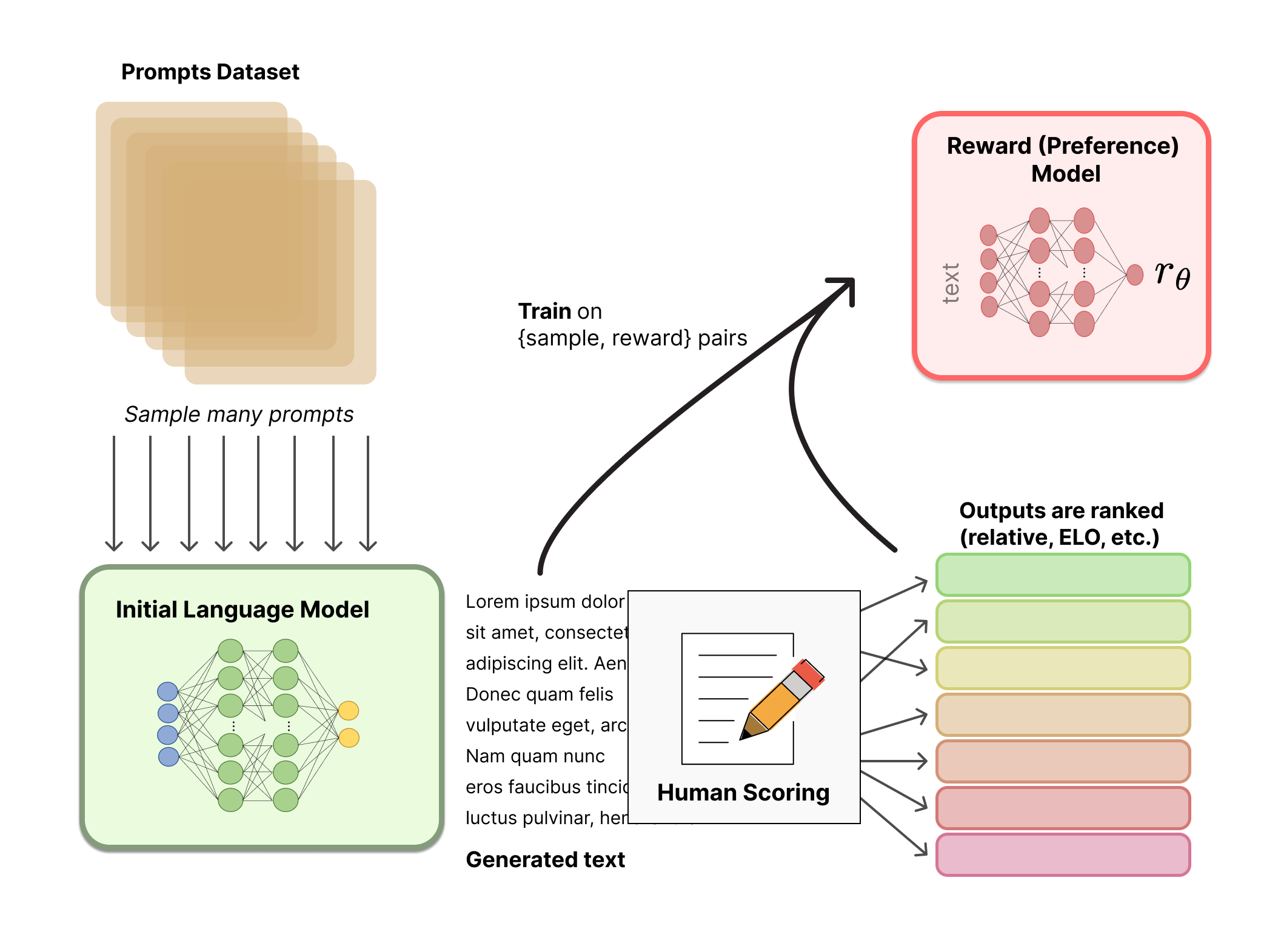
Afinamiento fino con RL
Entrenar un modelo de lenguaje con aprendizaje por refuerzo era, durante mucho tiempo, algo que las personas habrían considerado imposible tanto por razones de ingeniería como algorítmicas. Lo que varias organizaciones parecen haber logrado es afinar algunos o todos los parámetros de una copia del LM inicial con un algoritmo de RL de gradiente de política proximal, Proximal Policy Optimization (PPO). Los parámetros del LM se congelan porque afinar un modelo completo de 10B o 100B+ parámetros es prohibitivamente caro (para obtener más información, consulte Adaptación de rango bajo (LoRA) para LMs o el modelo Sparrow LM de DeepMind). PPO ha existido durante un tiempo relativamente largo: hay toneladas de guías sobre cómo funciona. La madurez relativa de este método lo convirtió en una opción favorable para escalar la nueva aplicación de entrenamiento distribuido para RLHF. Resulta que muchos de los avances fundamentales de RL para RLHF han consistido en descubrir cómo actualizar un modelo tan grande con un algoritmo familiar (más sobre eso más adelante).
Primero, formularemos esta tarea de afinamiento fino como un problema de RL. Primero, la política es un modelo de lenguaje que recibe una indicación y devuelve una secuencia de texto (o solo distribuciones de probabilidad sobre texto). El espacio de acciones de esta política son todos los tokens correspondientes al vocabulario del modelo de lenguaje (generalmente del orden de 50k tokens) y el espacio de observación es la distribución de posibles secuencias de tokens de entrada, que también es bastante grande dadas las aplicaciones anteriores de RL (la dimensión es aproximadamente el tamaño del vocabulario ^ longitud de la secuencia de tokens de entrada). La función de recompensa es una combinación del modelo de preferencia y una restricción en el cambio de política.
La función de recompensa es donde el sistema combina todos los modelos que hemos discutido en un proceso de RLHF. Dada una indicación, x , del conjunto de datos, el texto y se genera mediante la iteración actual de la política afinada. Concatenado con la indicación original, ese texto se pasa al modelo de preferencia, que devuelve una noción escalar de “preferibilidad”, r θ r_\theta r θ . Además, se comparan las distribuciones de probabilidad por token de la política de RL con las del modelo inicial para calcular una penalización por la diferencia entre ellas. En varios artículos de OpenAI, Anthropic y DeepMind, esta penalización se ha diseñado como una versión escalada de la divergencia de Kullback-Leibler (KL) entre estas secuencias de distribuciones de tokens, r KL r_\text{KL} r KL . El término de divergencia KL penaliza a la política de RL por alejarse sustancialmente del modelo preentrenado inicial con cada lote de entrenamiento, lo que puede ser útil para asegurarse de que el modelo genere fragmentos de texto razonablemente coherentes. Sin esta penalización, la optimización puede comenzar a generar texto que es incoherente pero engaña al modelo de recompensa para dar una alta recompensa. En la práctica, la divergencia KL se aproxima mediante el muestreo de ambas distribuciones (explicado por John Schulman aquí ). La recompensa final enviada a la regla de actualización de RL es r = r θ − λ r KL r = r_\theta – \lambda r_\text{KL} r = r θ − λ r KL .
Algunos sistemas RLHF han añadido términos adicionales a la función de recompensa. Por ejemplo, OpenAI experimentó con éxito en InstructGPT mezclando gradientes adicionales de preentrenamiento (del conjunto de anotaciones humanas) en la regla de actualización de PPO. Es probable que a medida que se investigue más el RLHF, la formulación de esta función de recompensa siga evolucionando.
Finalmente, la regla de actualización es la actualización de parámetros de PPO que maximiza las métricas de recompensa en el lote actual de datos (PPO es de política, lo que significa que los parámetros solo se actualizan con el lote actual de pares generación de indicaciones). PPO es un algoritmo de optimización de región de confianza que utiliza restricciones en el gradiente para asegurar que el paso de actualización no desestabilice el proceso de aprendizaje. DeepMind utilizó una configuración de recompensa similar para Gopher pero utilizó el actor-critic de ventaja síncrona (A2C) para optimizar los gradientes, lo cual es notablemente diferente pero no se ha reproducido externamente.

Nota técnica: El diagrama anterior da la impresión de que ambos modelos generan respuestas diferentes para la misma indicación, pero lo que realmente sucede es que la política RL genera texto, y ese texto se alimenta al modelo inicial para producir sus probabilidades relativas para la penalización KL.
Opcionalmente, RLHF puede continuar a partir de este punto actualizando iterativamente el modelo de recompensa y la política juntos. A medida que la política RL se actualiza, los usuarios pueden seguir clasificando estas salidas versus las versiones anteriores del modelo. La mayoría de los documentos aún no han discutido la implementación de esta operación, ya que el modo de implementación necesario para recopilar este tipo de datos solo funciona para agentes de diálogo con acceso a una base de usuarios comprometida. Anthropic discute esta opción como RLHF en línea iterado (consulte el artículo original), donde las iteraciones de la política se incluyen en el sistema de clasificación ELO entre modelos. Esto introduce dinámicas complejas de la evolución de la política y el modelo de recompensa, lo que representa una cuestión de investigación compleja y abierta.
El primer código lanzado para realizar RLHF en LMs fue de OpenAI en TensorFlow en 2019.
Hoy en día, ya existen varios repositorios activos para RLHF en PyTorch que surgieron a partir de esto. Los repositorios principales son Transformers Reinforcement Learning (TRL), TRLX que se originó como una bifurcación de TRL, y Reinforcement Learning for Language models (RL4LMs).
TRL está diseñado para ajustar finamente LMs preentrenados en el ecosistema de Hugging Face con PPO. TRLX es una bifurcación ampliada de TRL construida por CarperAI para manejar modelos más grandes para entrenamiento en línea y sin conexión. En este momento, TRLX tiene una API capaz de RLHF lista para producción con PPO e Implicit Language Q-Learning (ILQL) en las escalas requeridas para la implementación de LLM (por ejemplo, 33 mil millones de parámetros). Las versiones futuras de TRLX permitirán modelos de lenguaje de hasta 200B parámetros. Por lo tanto, la interfaz con TRLX está optimizada para ingenieros de aprendizaje automático con experiencia en esta escala.
RL4LMs ofrece bloques de construcción para ajustar y evaluar LLMs con una amplia variedad de algoritmos de RL (PPO, NLPO, A2C y TRPO), funciones de recompensa y métricas. Además, la biblioteca es fácilmente personalizable, lo que permite el entrenamiento de cualquier LM basado en codificador-decodificador o transformador de codificador especificado por el usuario. Cabe destacar que está bien probado y evaluado en una amplia gama de tareas en trabajos recientes que ascienden a 2000 experimentos, resaltando varias ideas prácticas sobre la comparación del presupuesto de datos (demostraciones de expertos frente a modelado de recompensa), el manejo de pirateo de recompensas e inestabilidades en el entrenamiento, etc. Los planes actuales de RL4LMs incluyen el entrenamiento distribuido de modelos más grandes y nuevos algoritmos de RL.
Tanto TRLX como RL4LMs están en constante desarrollo, por lo que se esperan más características más allá de estas pronto.
Existe un gran conjunto de datos creado por Anthropic disponible en el Hub.
Aunque estas técnicas son extremadamente prometedoras e impactantes y han captado la atención de los mayores laboratorios de investigación en IA, todavía existen limitaciones claras. Los modelos, aunque son mejores, aún pueden generar texto dañino o incorrecto desde el punto de vista factual sin ninguna incertidumbre. Esta imperfección representa un desafío a largo plazo y una motivación para RLHF: operar en un dominio de problema inherentemente humano significa que nunca habrá una línea final clara que cruzar para etiquetar al modelo como completo.
Cuando se implementa un sistema utilizando RLHF, la recopilación de datos de preferencia humana es bastante costosa debido a la integración directa de otros trabajadores humanos fuera del ciclo de entrenamiento. El rendimiento de RLHF es tan bueno como la calidad de sus anotaciones humanas, que adoptan dos variedades: texto generado por humanos, como el ajuste fino del LM inicial en InstructGPT, y etiquetas de preferencias humanas entre las salidas del modelo.
Generar texto humano bien escrito que responda a preguntas específicas es muy costoso, ya que a menudo requiere contratar personal a tiempo parcial (en lugar de poder confiar en los usuarios del producto o la colaboración masiva). Afortunadamente, la escala de datos utilizada para entrenar el modelo de recompensa en la mayoría de las aplicaciones de RLHF (~ 50k muestras de preferencia etiquetadas) no es tan costosa. Sin embargo, sigue siendo un costo más alto de lo que los laboratorios académicos podrían permitirse. Actualmente, solo existe un conjunto de datos a gran escala para RLHF en un modelo de lenguaje general (de Anthropic) y un par de conjuntos de datos específicos de tareas a menor escala (como datos de resumen de OpenAI). El segundo desafío de los datos para RLHF es que los anotadores humanos a menudo pueden estar en desacuerdo, lo que agrega una variabilidad potencial sustancial a los datos de entrenamiento sin una verdad absoluta.
Con estas limitaciones, aún se podrían explorar opciones de diseño no exploradas que podrían permitir que RLHF avance considerablemente. Muchas de estas opciones caen dentro del dominio de mejorar el optimizador de RL. PPO es un algoritmo relativamente antiguo, pero no hay razones estructurales por las que otros algoritmos no puedan ofrecer beneficios y permutaciones en el flujo de trabajo existente de RLHF. Un gran costo de la parte de retroalimentación del ajuste fino de la política de LM es que cada pieza de texto generada por la política debe evaluarse en el modelo de recompensa (ya que actúa como parte del entorno en el marco estándar de RL). Para evitar estos costosos pases directos de un modelo grande, se podría utilizar RL sin conexión como optimizador de políticas. Recientemente, han surgido nuevos algoritmos, como el aprendizaje implícito de Q-lenguaje (ILQL) [Charla sobre ILQL en CarperAI], que se adaptan particularmente bien a este tipo de optimización. Otros compromisos fundamentales en el proceso de RL, como el equilibrio entre exploración y explotación, tampoco se han documentado. Explorar estas direcciones al menos desarrollaría una comprensión sustancial de cómo funciona RLHF y, de no ser así, proporcionaría un rendimiento mejorado.
Organizamos una conferencia el martes 13 de diciembre de 2022 que amplió esta publicación; ¡puedes verla aquí!
Lecturas adicionales
Aquí hay una lista de los artículos más relevantes sobre RLHF hasta la fecha. El campo se popularizó recientemente con la aparición de DeepRL (alrededor de 2017) y se ha convertido en un estudio más amplio de las aplicaciones de LLMs de muchas grandes empresas de tecnología. Aquí hay algunos artículos sobre RLHF anteriores al enfoque de LM:
- TAMER: Entrenar a un agente manualmente a través de refuerzo evaluativo (Knox y Stone 2008): Propuso un agente aprendido donde los humanos proporcionaban puntuaciones sobre las acciones tomadas de manera iterativa para aprender un modelo de recompensa.
- Aprendizaje interactivo a partir de comentarios humanos dependentes de la política (MacGlashan et al. 2017): Propuso un algoritmo actor-critic, COACH, donde los comentarios humanos (tanto positivos como negativos) se utilizan para ajustar la función de ventaja.
- Aprendizaje profundo de refuerzo a partir de las preferencias humanas (Christiano et al. 2017): RLHF aplicado a preferencias entre trayectorias de Atari.
- TAMER profundo: Moldeado interactivo de agentes en espacios de estado de alta dimensión (Warnell et al. 2018): Amplía el marco de TAMER donde se utiliza una red neuronal profunda para modelar la predicción de recompensa.
Y aquí hay una lista de los “principales” artículos que muestran el rendimiento de RLHF para LMs:
- Ajuste fino de modelos de lenguaje a partir de preferencias humanas (Zieglar et al. 2019): Un artículo temprano que estudia el impacto del aprendizaje de recompensas en cuatro tareas específicas.
- Aprendiendo a resumir con retroalimentación humana (Stiennon et al., 2020): RLHF aplicado a la tarea de resumir texto. También, Resumir libros de forma recursiva con retroalimentación humana (OpenAI Alignment Team 2021), trabajo posterior de resumir libros.
- WebGPT: Navegación asistida por el navegador con retroalimentación humana (OpenAI, 2021): Usar RLHF para entrenar un agente para navegar por la web.
- InstructGPT: Entrenar modelos de lenguaje para seguir instrucciones con retroalimentación humana (OpenAI Alignment Team 2022): RLHF aplicado a un modelo de lenguaje general [Publicación de blog sobre InstructGPT].
- GopherCite: Enseñar a los modelos de lenguaje a proporcionar respuestas con citas verificadas (Menick et al. 2022): Entrenar un modelo de lenguaje con RLHF para devolver respuestas con citas específicas.
- Sparrow: Mejorar la alineación de los agentes de diálogo mediante juicios humanos dirigidos (Glaese et al. 2022): Ajuste fino de un agente de diálogo con RLHF.
- ChatGPT: Optimización de modelos de lenguaje para diálogo (OpenAI 2022): Entrenamiento de un modelo de lenguaje con RLHF para su uso adecuado como un chatbot multiuso.
- Leyes de escala para la sobreoptimización del modelo de recompensa (Gao et al. 2022): Estudia las propiedades de escala del modelo de preferencia aprendido en RLHF.
- Entrenamiento de un asistente útil e inofensivo con aprendizaje por refuerzo a partir de retroalimentación humana (Anthropic, 2022): Una documentación detallada de entrenar a un asistente de modelo de lenguaje con RLHF.
- Red Teaming Language Models para reducir daños: métodos, comportamientos de escala y lecciones aprendidas (Ganguli et al. 2022): Una documentación detallada de los esfuerzos para “descubrir, medir y tratar de reducir las salidas potencialmente dañinas” de los modelos de lenguaje.
- Planificación dinámica en diálogos abiertos utilizando aprendizaje por refuerzo (Cohen et al. 2022): Uso de RL para mejorar la habilidad conversacional de un agente de diálogo abierto.
- ¿El aprendizaje por refuerzo no es para el procesamiento del lenguaje natural?: Referencias, baselines y bloques de construcción para la optimización de la política de lenguaje natural (Ramamurthy y Ammanabrolu et al. 2022): Discute el espacio de diseño de herramientas de código abierto en RLHF y propone un nuevo algoritmo NLPO (Optimización de la Política de Lenguaje Natural) como una alternativa a PPO.
El campo es la convergencia de múltiples áreas, por lo que también puedes encontrar recursos en otras áreas:
- Aprendizaje continuo de instrucciones (Kojima et al. 2021, Suhr y Artzi 2022) o aprendizaje de bandit a partir de la retroalimentación del usuario (Sokolov et al. 2016, Gao et al. 2022)
- Historia anterior sobre el uso de otros algoritmos de RL para la generación de texto (no todos con preferencias humanas), como las redes neuronales recurrentes (Ranzato et al. 2015), un algoritmo de actor-crítico para la predicción de texto (Bahdanau et al. 2016), o un trabajo anterior que agrega preferencias humanas a este marco (Nguyen et al. 2017).
Citación: Si encontraste esto útil para tu trabajo académico, considera citar nuestro trabajo, en texto:
Lambert, et al., "Illustrating Reinforcement Learning from Human Feedback (RLHF)", Hugging Face Blog, 2022.Citación en BibTeX:
@article{lambert2022illustrating,
author = {Lambert, Nathan and Castricato, Louis and von Werra, Leandro and Havrilla, Alex},
title = {Illustrating Reinforcement Learning from Human Feedback (RLHF)},
journal = {Hugging Face Blog},
year = {2022},
note = {https://huggingface.co/blog/rlhf},
}Gracias a Robert Kirk por corregir algunos errores factuales con respecto a implementaciones específicas de RLHF. Gracias a Peter Stone, Khanh X. Nguyen y Yoav Artzi por ayudar a expandir aún más los trabajos relacionados en la historia.
Gracias a Stas Bekman por corregir algunos errores tipográficos o frases confusas.
Gracias a Igor Kotenkov por señalar un error técnico en el término de penalización KL del procedimiento de RLHF, su diagrama y descripción textual.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Introducción al Aprendizaje de Máquina en Grafos
- ¿Qué hace útil a un agente de diálogo?
- Optimum+ONNX Runtime Entrenamiento más fácil y rápido para tus modelos de Hugging Face
- El estado de la Visión por Computadora en Hugging Face 🤗
- Presentando ⚔️ IA vs. IA ⚔️ un sistema de competencia de aprendizaje por refuerzo profundo para múltiples agentes
- Ajuste de Fine-Tuning Eficiente en Parámetros usando 🤗 PEFT
- Generación de texto a partir de imágenes sin entrenamiento previo con BLIP-2





