Sobre el aprendizaje en presencia de grupos subrepresentados
Aprendizaje en grupos subrepresentados
El Cambio es Difícil: Un Vistazo Más Cercano al Desplazamiento de Subpoblaciones (ICML 2023)
Permítame presentarles nuestro último trabajo, el cual ha sido aceptado por ICML 2023: El Cambio es Difícil: Un Vistazo Más Cercano al Desplazamiento de Subpoblaciones. Los modelos de aprendizaje automático han demostrado un gran potencial en muchas aplicaciones, pero a menudo tienen un rendimiento deficiente en subgrupos que están subrepresentados en los datos de entrenamiento. Comprender las variaciones en los mecanismos que causan dichos desplazamientos de subpoblaciones, y cómo los algoritmos generalizan a través de desplazamientos diversos a gran escala, sigue siendo un desafío. En este trabajo, nuestro objetivo es llenar este vacío proporcionando un análisis detallado de los desplazamientos de subpoblaciones y su impacto en los algoritmos de aprendizaje automático.
En primer lugar, presentamos un marco unificado que descompone y explica los desplazamientos comunes en los subgrupos. Además, introducimos una evaluación integral que consiste en 20 algoritmos de vanguardia, los cuales evaluamos en 12 conjuntos de datos del mundo real que abarcan los dominios de visión, lenguaje y atención médica. A través de nuestro análisis y evaluación, proporcionamos observaciones interesantes y una comprensión de los desplazamientos de subpoblaciones y cómo los algoritmos de aprendizaje automático generalizan bajo tales desplazamientos del mundo real. El código, los datos y los modelos están disponibles en GitHub: https://github.com/YyzHarry/SubpopBench.
Antecedentes y Motivación
Los modelos de aprendizaje automático suelen mostrar una disminución en el rendimiento en presencia de desplazamientos en la distribución. Estos desplazamientos ocurren cuando la distribución de datos subyacente cambia (por ejemplo, la distribución de entrenamiento es diferente de la de prueba), lo que resulta en una disminución del rendimiento al implementar los modelos. Construir modelos de aprendizaje automático que sean robustos ante estos desplazamientos es fundamental para la implementación segura de dichos modelos en el mundo real. Un tipo de desplazamiento de distribución omnipresente es el desplazamiento de subpoblación, que se caracteriza por cambios en la proporción de algunas subpoblaciones entre el entrenamiento y la implementación. En este tipo de configuraciones, los modelos pueden tener un rendimiento general alto pero aún así tener un rendimiento deficiente en subgrupos raros.
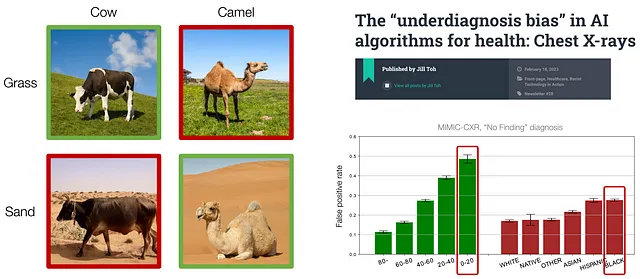
Por ejemplo, en la tarea de clasificación de vacas y camellos, las vacas suelen encontrarse en áreas con pasto verde, y los camellos suelen encontrarse en áreas con arena amarilla. Sin embargo, esta correlación es espuria porque la presencia de vacas o camellos no tiene relación con el color de fondo. Como resultado, el modelo entrenado tiene un buen rendimiento en las imágenes mencionadas, pero no puede generalizar a animales con diferentes colores de fondo que son raros en los datos de entrenamiento, como vacas en la arena o camellos en el pasto.
- Desbloqueando los secretos de la Dimensión de Cambio Lento (SCD) Una Visión Integral de 8 Tipos
- Crea tu propio sitio web impresionante en minutos de forma gratuita
- Creando gráficos científicos de forma sencilla con scienceplots y matplotlib
Además, cuando se trata de diagnóstico médico, se ha encontrado que los modelos de aprendizaje automático suelen tener un peor rendimiento en grupos de edad o etnias subrepresentados, lo que plantea preocupaciones importantes sobre la equidad.
Todos estos desplazamientos han sido generalmente denominados desplazamiento de subpoblación, pero se entiende poco sobre la variación en los mecanismos que causan estos desplazamientos de subpoblaciones, y cómo los algoritmos generalizan a través de estos desplazamientos diversos a gran escala. Entonces, ¿cómo modelar el desplazamiento de subpoblación?
Un Marco Unificado del Desplazamiento de Subpoblación
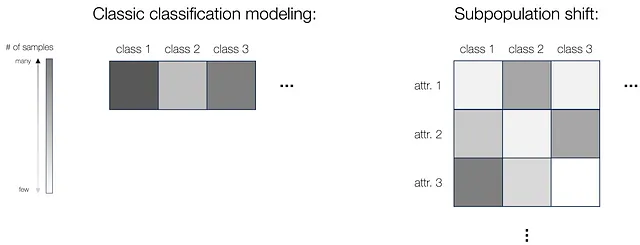
Primero proporcionamos un marco unificado para el modelado del desplazamiento de subpoblación. En la configuración clásica de clasificación, tenemos datos de entrenamiento de múltiples clases (donde usamos densidades de color diferentes para representar diferentes cantidades de muestras en cada clase). Sin embargo, cuando se trata de desplazamiento de subpoblación, existen atributos además de la clase, como los colores de fondo en el problema de vacas y camellos. En este caso, podríamos definir las subpoblaciones discretas en base tanto al atributo como a la etiqueta, y aquí también podría variar el número de muestras para diferentes atributos dentro de la misma clase (ver figura a continuación). Y naturalmente, para probar el modelo, al igual que en la configuración de clasificación donde evaluamos el rendimiento en todas las clases, en el desplazamiento de subpoblación probamos el modelo en todos los subgrupos, para asegurarnos de que el rendimiento más bajo en todas las subpoblaciones sea lo suficientemente bueno, o para garantizar un rendimiento igualmente bueno en todos los grupos.
Específicamente, para proporcionar una formulación matemática genérica, primero reescribimos el modelo de clasificación utilizando el teorema de Bayes. Además, vemos cada entrada x como totalmente descrita o generada a partir de un conjunto de características centrales subyacentes (X_core) y una lista de atributos (a). Aquí, X_core denota los componentes invariantes subyacentes que son específicos de la etiqueta y respaldan una clasificación sólida, mientras que los atributos a pueden tener distribuciones inconsistentes y no son específicos de la etiqueta. Como tal, podemos integrar este modelado de regreso a la ecuación y descomponerlo en tres términos, como se muestra a continuación:
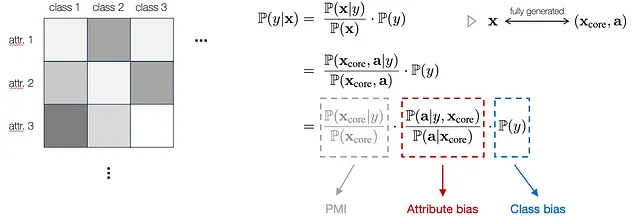
Específicamente, el primer término representa la información mutua punto a punto (PMI) entre X_core y y, que es el indicador sólido relacionado con las etiquetas de clase subyacentes. Los términos segundo y tercero corresponden al sesgo potencial que surge en la distribución del atributo y la distribución de etiquetas, respectivamente. Este modelado explica cómo el atributo y la clase influyen en los resultados bajo el cambio de subpoblación. Por lo tanto, dado X_core invariante entre las distribuciones de entrenamiento y prueba, podemos ignorar los cambios en el primer término y centrarnos en cómo el atributo y la clase influyen en los resultados bajo el cambio de subpoblación.
Basándonos en este marco, definimos y caracterizamos formalmente cuatro tipos básicos de cambio de subpoblación: correlaciones espurias, desequilibrio de atributos, desequilibrio de clases y generalización de atributos. Cada tipo constituye un componente de cambio básico que potencialmente surge en el cambio de subpoblación.
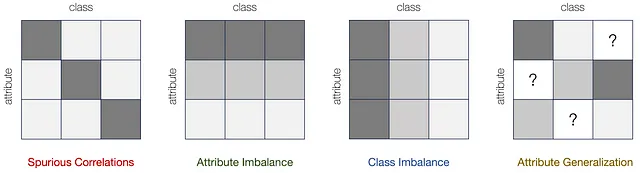
Primero, cuando cierto atributo está correlacionado de manera espuria con la etiqueta y en los datos de entrenamiento pero no en los datos de prueba, implica correlaciones espurias. Además, cuando ciertos atributos se muestrean con una probabilidad mucho menor que otros, se induce desequilibrio de atributos. De manera similar, las etiquetas de clase pueden exhibir distribuciones desequilibradas, lo que provoca una menor preferencia por las etiquetas minoritarias. Esto llevará a un desequilibrio de clases. Y finalmente, ciertos atributos pueden estar completamente ausentes en el entrenamiento, pero presentes en las pruebas para ciertas clases, lo que motiva la necesidad de una generalización de atributos. La fuente de sesgos de atributos/clases para cada uno de estos cambios, así como el impacto en el modelo de clasificación, se resumen en la siguiente tabla:

Estos cuatro casos constituyen los componentes básicos del cambio y son elementos importantes para explicar cambios complejos en subgrupos en datos reales. Y en la práctica, los conjuntos de datos a menudo consisten en múltiples tipos de cambio simultáneamente, en lugar de uno solo.
SubpopBench: Evaluación del cambio de subpoblación
Ahora, después de establecer la formulación, proponemos SubpopBench, un conjunto de pruebas integral que incluye algoritmos de última generación evaluados en 12 conjuntos de datos del mundo real. En particular, estos conjuntos de datos se originan en una variedad de modalidades y tareas, incluyendo aplicaciones de visión, lenguaje y atención médica, con modalidades de datos que van desde imágenes naturales, texto, texto clínico hasta radiografías de tórax. También presentan diferentes componentes de cambio.
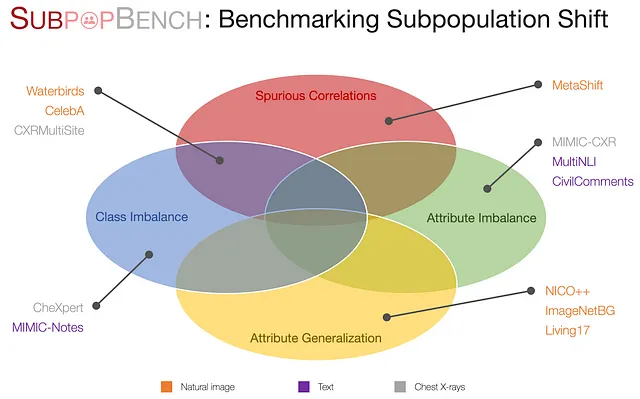

Para obtener más detalles sobre este benchmark, consulte nuestro artículo. Con el benchmark establecido y más de 10K modelos entrenados utilizando 20 algoritmos de última generación, revelamos observaciones intrigantes para futuras investigaciones en este campo.
Un análisis detallado sobre el cambio de subpoblación
Los algoritmos SOTA solo mejoran ciertos tipos de cambio
En primer lugar, observamos que los algoritmos SOTA solo mejoran la robustez de los subgrupos en ciertos tipos de cambios, pero no en otros.
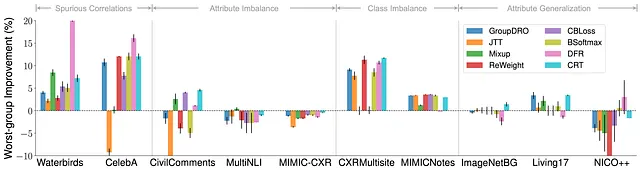
Aquí trazamos la mejora de precisión del peor grupo sobre ERM para varios algoritmos SOTA. Para correlaciones espurias y desequilibrio de clases, los algoritmos existentes pueden proporcionar mejoras consistentes en el peor grupo sobre ERM, lo que indica que se ha progresado en la resolución de estos dos cambios específicos.
Curiosamente, sin embargo, cuando se trata de desequilibrio de atributos, se observa poca mejora en los conjuntos de datos. Además, el rendimiento empeora aún más en la generalización de atributos.
Estos hallazgos destacan que los avances actuales solo se han logrado para cambios específicos, mientras que no se ha progresado en los cambios más desafiantes como AG (generalización de atributos).
El papel de las representaciones y clasificadores
Además, nos motiva explorar el papel de la representación y el clasificador en el cambio de subpoblación. En particular, separamos toda la red en dos partes: el extractor de características f y el clasificador g, donde f extrae las características latentes de la entrada y g emite la predicción final. Nos preguntamos, ¿cómo afectan la representación y el clasificador al rendimiento del subgrupo?
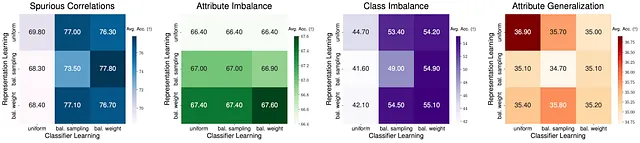
En primer lugar, dado un modelo ERM base, cuando se optimiza solo el aprendizaje del clasificador con la representación fija, puede mejorar sustancialmente el rendimiento para correlaciones espurias y desequilibrio de clases, lo que indica que las representaciones aprendidas por ERM ya son lo suficientemente buenas. Sin embargo, es interesante destacar que mejorar el aprendizaje de la representación en lugar del clasificador puede brindar ganancias notables en el desequilibrio de atributos, lo que indica que es posible que necesitemos características más poderosas para ciertos cambios. Finalmente, no se obtienen ganancias de rendimiento mediante métodos de aprendizaje estratificados en la generalización de atributos. Esto resalta que es necesario considerar el diseño del modelo cuando se enfrenta a diferentes tipos de cambio en la realidad.
Sobre la selección de modelos y la disponibilidad de atributos
Además, observamos que la selección de modelos y la disponibilidad de atributos afectan considerablemente la evaluación del cambio de subpoblación.
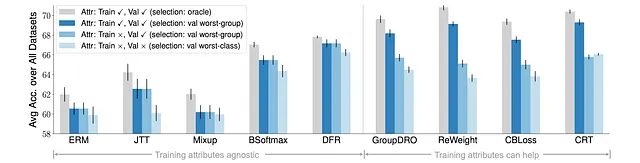
Específicamente, al eliminar gradualmente las anotaciones de atributos en los datos de entrenamiento y/o validación, todos los algoritmos experimentaron una notable disminución en el rendimiento, especialmente cuando no hay atributo disponible tanto en los datos de entrenamiento como en los de validación.
Esto indica que el acceso a los atributos aún desempeña un papel significativo para obtener un rendimiento razonable en el cambio de subpoblación, y los algoritmos futuros deben considerar escenarios más realistas para la selección de modelos y la disponibilidad de atributos.
Métricas más allá de la precisión del peor grupo
Finalmente, revelamos el trade-off fundamental entre las métricas de evaluación. La precisión del peor grupo, o WGA, se considera el estándar de oro en la evaluación del cambio de subpoblación. Sin embargo, ¿mejorar WGA siempre mejora otras métricas significativas?

Primero mostramos que mejorar WGA podría llevar a una mejora en el rendimiento de ciertas métricas, como la precisión ajustada mostrada aquí. Sin embargo, si consideramos además la precisión en el peor caso, sorprendentemente muestra una fuerte correlación lineal negativa con WGA. Esto revela la limitación fundamental de usar WGA como la única métrica para evaluar el rendimiento del modelo en cambios en subpoblaciones: Un modelo bien realizado con alta WGA puede tener, sin embargo, una baja precisión en la peor clase, lo cual es especialmente alarmante en aplicaciones críticas como el diagnóstico médico.
Nuestras observaciones enfatizan la necesidad de contar con un conjunto de métricas de evaluación más realistas y amplio en cambios en subpoblaciones. También mostramos muchas otras métricas que exhiben una correlación inversa con WGA en nuestro artículo.
Conclusiones
Para concluir este artículo, investigamos sistemáticamente el problema del cambio en subpoblaciones, formalizamos un marco unificado para definir y cuantificar diferentes tipos de cambio en subpoblaciones, y establecimos una referencia integral para una evaluación realista en datos del mundo real. Nuestra referencia incluye 20 métodos SOTA y 12 conjuntos de datos del mundo real en diferentes dominios. Basándonos en más de 10K modelos entrenados, revelamos propiedades intrigantes en el cambio de subpoblaciones que tienen implicaciones para futuras investigaciones. Esperamos que nuestra referencia y descubrimientos promuevan evaluaciones realistas y rigurosas e inspiren nuevos avances en el cambio de subpoblaciones. Al final, adjunto varios enlaces relevantes de nuestro artículo; ¡gracias por leer!
Código: https://github.com/YyzHarry/SubpopBench
Página del Proyecto: https://subpopbench.csail.mit.edu/
Charla: https://www.youtube.com/watch?v=WiSrCWAAUNI
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Hacia la Agnosticidad de Herramientas en Ciencia de Datos SQL Case When y Pandas Where
- Informe sobre gastos y tendencias de análisis de datos y ciencia de datos en la primera mitad de 2023
- Redes Neuronales y Aprendizaje Profundo Un Libro de Texto (2da Edición)
- Bard se estrena en Europa y Brasil en medio de preocupaciones sobre la privacidad y una competencia cada vez más intensa
- Desarrollando herramientas de IA confiables para la salud
- Este artículo de IA de Stanford y Google introduce agentes generativos agentes computacionales interactivos que simulan el comportamiento humano’.
- Creando un Chatbot con FalconAI, LangChain y Chainlit






