Aprendizaje automático de efectos mixtos para variables categóricas de alta cardinalidad – Parte I una comparación empírica de diferentes métodos.
Aprendizaje automático de efectos mixtos para variables categóricas - Parte I, comparación empírica de métodos.
Por qué los efectos aleatorios son útiles para los modelos de aprendizaje automático
Las variables categóricas de alta cardinalidad son variables para las cuales el número de niveles diferentes es grande en relación al tamaño de la muestra de un conjunto de datos, o en otras palabras, hay pocos puntos de datos por nivel de una variable categórica. Los métodos de aprendizaje automático pueden tener dificultades con variables de alta cardinalidad. En este artículo, argumentamos que los efectos aleatorios son una herramienta efectiva para modelar variables categóricas de alta cardinalidad en modelos de aprendizaje automático. En particular, comparamos empíricamente varias versiones de dos de los métodos de aprendizaje automático más exitosos, tree-boosting y redes neuronales profundas, así como modelos de efectos mixtos lineales utilizando múltiples conjuntos de datos tabulares con variables categóricas de alta cardinalidad. Nuestros resultados muestran que, primero, los modelos de aprendizaje automático con efectos aleatorios funcionan mejor que sus contrapartes sin efectos aleatorios, y segundo, tree-boosting con efectos aleatorios supera a las redes neuronales profundas con efectos aleatorios.
Tabla de contenidos
· 1 Introducción · 2 Efectos aleatorios para modelar variables categóricas de alta cardinalidad · 3 Comparación de diferentes métodos utilizando conjuntos de datos del mundo real · 4 Conclusión · Referencias
1 Introducción
Una estrategia simple para tratar con variables categóricas es usar la codificación one-hot o variables ficticias. Pero este enfoque a menudo no funciona bien para variables categóricas de alta cardinalidad debido a las razones descritas a continuación. Para las redes neuronales, una solución adoptada con frecuencia son las incrustaciones de entidades [Guo y Berkhahn, 2016], que asignan cada nivel de una variable categórica a un espacio euclidiano de baja dimensión. Para tree-boosting, un enfoque simple es asignar un número a cada nivel de una variable categórica y considerar esto como una variable numérica unidimensional. Una solución alternativa implementada en la biblioteca de impulso LightGBM [Ke et al., 2017] funciona dividiendo todos los niveles en dos subconjuntos utilizando un enfoque aproximado [Fisher, 1958] al encontrar divisiones en el algoritmo de construcción del árbol. Además, la biblioteca de impulso CatBoost [Prokhorenkova et al., 2018] implementa un enfoque basado en estadísticas objetivo ordenadas calculadas utilizando particiones aleatorias de los datos de entrenamiento para manejar variables predictoras categóricas.
2 Efectos aleatorios para modelar variables categóricas de alta cardinalidad
Los efectos aleatorios se pueden utilizar como una herramienta efectiva para modelar variables categóricas de alta cardinalidad. En el caso de regresión con una sola variable categórica de alta cardinalidad, un modelo de efectos aleatorios se puede escribir como
- Aprendiendo el lenguaje de las moléculas para predecir sus propiedades
- Anunciando el primer Desafío de Desaprendizaje Automático
- ‘Mi aplicación 3D favorita’ Fanático de Blender comparte su escena inspirada en Japón esta semana ‘En el NVIDIA Studio’
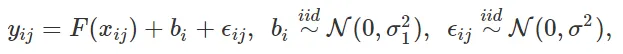
donde j=1,…,ni es el índice de muestra dentro del nivel i, con ni siendo el número de muestras para las cuales la variable categórica alcanza el nivel i, e i denota el nivel con q siendo el número total de niveles de la variable categórica. El número total de muestras es entonces n = n0 + n1 + … + nq. Este modelo también se llama modelo de efectos mixtos ya que contiene tanto efectos fijos F(xij) como efectos aleatorios bi. xij son las variables predictoras o características de efectos fijos. Los modelos de efectos mixtos se pueden extender a otras distribuciones de variables de respuesta (por ejemplo, clasificación) y múltiples variables categóricas.
Tradicionalmente, los efectos aleatorios se utilizaban en modelos lineales en los que se asume que F es una función lineal. En los últimos años, los modelos de efectos mixtos lineales se han extendido a modelos no lineales utilizando bosques aleatorios [Hajjem et al., 2014], tree-boosting [Sigrist, 2022, 2023a] y más recientemente (en términos de primer preimpreso público) redes neuronales profundas [Simchoni y Rosset, 2021, 2023]. A diferencia de los modelos de aprendizaje automático independientes clásicos, los efectos aleatorios introducen dependencia entre las muestras.
¿Por qué son útiles los efectos aleatorios para variables categóricas de alta cardinalidad?
Para variables categóricas de alta cardinalidad, hay poca información para cada nivel. Intuitivamente, si la variable de respuesta tiene una media (condicional) diferente para muchos niveles, los modelos tradicionales de aprendizaje automático (con codificación one-hot, embeddings o variables numéricas unidimensionales) pueden tener problemas de sobreajuste o subajuste para este tipo de datos. Desde el punto de vista del trade-off clásico entre sesgo y varianza, los modelos de aprendizaje automático independientes pueden tener dificultades para equilibrar este trade-off y encontrar una cantidad adecuada de regularización. Por ejemplo, puede ocurrir sobreajuste, lo que significa que un modelo tiene un sesgo bajo pero una varianza alta.
Hablando de manera general, los efectos aleatorios actúan como un prior, o regularizador, que modela la parte difícil de una función, es decir, la parte cuya “dimensión” es similar al tamaño total de la muestra y, al hacerlo, proporciona una manera efectiva de encontrar un equilibrio entre el sobreajuste y el subajuste o entre el sesgo y la varianza. Por ejemplo, para una sola variable categórica, los modelos de efectos aleatorios reducirán las estimaciones de los efectos de intercepción de grupo hacia la media global. Este proceso a veces también se llama “agrupamiento de información”. Representa un trade-off entre ignorar completamente la variable categórica (= subajuste / sesgo alto y varianza baja) y dar a cada nivel de la variable categórica “total libertad” en la estimación (= sobreajuste / sesgo bajo y varianza alta). Es importante destacar que la cantidad de regularización, que está determinada por los parámetros de varianza del modelo, se aprende a partir de los datos. Específicamente, en el modelo de efectos aleatorios de un solo nivel mencionado anteriormente, una predicción (punto) para la variable de respuesta para una muestra con variables predictoras xp y una variable categórica con nivel i se calcula mediante
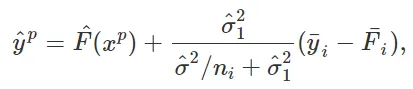
donde F(xp) es la función entrenada evaluada en xp, σ²_1 y σ² son estimaciones de varianza, y yi y Fi son las medias de muestra de yij y F(xij), respectivamente, para el nivel i. Ignorar la variable categórica daría la predicción yp = F(xp), y un modelo completamente flexible sin regularización daría yp = F(xp) + ( yi — Fi). Es decir, la diferencia entre estos dos casos extremos y el modelo de efectos aleatorios es el factor de reducción σ²_1 / (σ²/ni + σ²_1 y σ²) (que tiende a cero si el número de muestras ni para el nivel i es grande). Relacionado con esto, los modelos de efectos aleatorios permiten una estimación más eficiente (es decir, con menor varianza) de la función de efectos fijos F(.) [Sigrist, 2022].
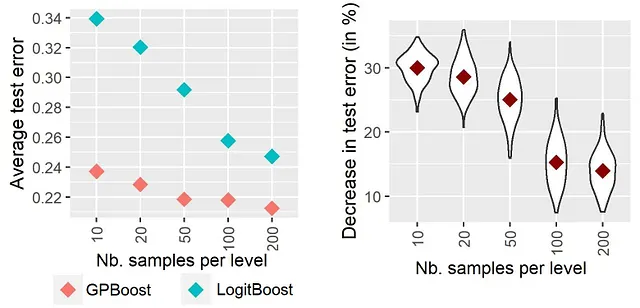
De acuerdo con este argumento, Sigrist [2023a, Sección 4.1] encuentra en experimentos empíricos que el boosting de árboles combinado con efectos aleatorios (“GPBoost”) supera al boosting de árboles independientes clásico (“LogitBoost”) más cuanto menor sea el número de muestras por nivel de una variable categórica, es decir, cuanto mayor sea la cardinalidad de una variable categórica. Los resultados se reproducen arriba en la Figura 1. Estos resultados se obtienen mediante la simulación de datos de clasificación binaria con 5000 muestras, una función predictora no lineal y una variable categórica con cada vez más niveles, es decir, menos muestras por nivel; consulte a Sigrist [2023a] para obtener más detalles. Los resultados muestran que la diferencia en el error de prueba de GPBoost y LogitBoost es mayor cuanto menos muestras haya por nivel de la variable categórica (= mayor número de niveles).
3 Comparación de diferentes métodos utilizando conjuntos de datos del mundo real
A continuación, comparamos varios métodos utilizando múltiples conjuntos de datos del mundo real con variables categóricas de alta cardinalidad. Utilizamos todos los conjuntos de datos tabulares disponibles públicamente de Simchoni y Rosset [2021, 2023] y también la misma configuración experimental que en Simchoni y Rosset [2021, 2023]. Además, incluimos el conjunto de datos de Salarios analizado en Sigrist [2022].
Consideramos los siguientes métodos:
- ‘Lineal’: modelos lineales de efectos mixtos
- ‘NN Embed’: redes neuronales profundas con embeddings
- ‘LMMNN’: combinación de redes neuronales profundas y efectos aleatorios [Simchoni y Rosset, 2021, 2023]
- ‘LGBM_Num’: boosting de árboles asignando un número a cada nivel de las variables categóricas y considerándolas como variables numéricas unidimensionales
- ‘LGBM_Cat’: boosting de árboles con el enfoque de
LightGBM[Ke et al., 2017] para variables categóricas - ‘CatBoost’: boosting de árboles con el enfoque de
CatBoost[Prokhorenkova et al., 2018] para variables categóricas - ‘GPBoost’: combinación de boosting de árboles y efectos aleatorios [Sigrist, 2022, 2023a]
Tenga en cuenta que, recientemente (versión 1.6 y posteriores), la biblioteca XGBoost [Chen y Guestrin, 2016] también ha implementado el mismo enfoque que LightGBM para manejar variables categóricas. No consideramos esto como un enfoque separado aquí.
Utilizamos los siguientes conjuntos de datos:
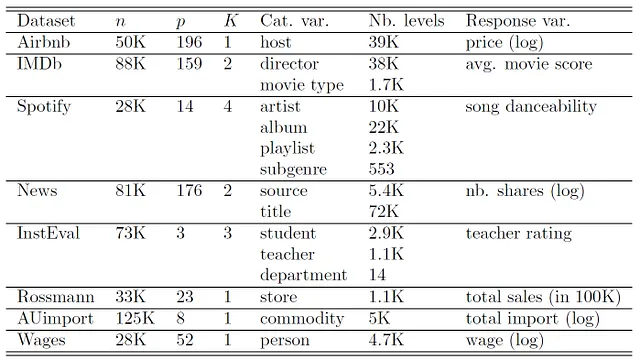
Para todos los métodos con efectos aleatorios, incluimos efectos aleatorios para cada variable categórica mencionada en la Tabla 1 sin correlación previa entre los efectos aleatorios. Los conjuntos de datos Rossmann, AUImport y Wages son conjuntos de datos longitudinales. Para estos, también incluimos pendientes aleatorias lineales y cuadráticas; consulte (el futuro) Parte III de esta serie. Consulte a Simchoni y Rosset [2021, 2023] y a Sigrist [2023b] para obtener más detalles sobre los conjuntos de datos.
Realizamos una validación cruzada de 5 pliegues (CV) en cada conjunto de datos con el error cuadrático medio (MSE) de prueba para medir la precisión de la predicción. Consulte a Sigrist [2023b] para obtener información detallada sobre la configuración experimental. El código para el preprocesamiento de los datos con instrucciones sobre cómo descargar los datos y el código para ejecutar los experimentos se puede encontrar aquí . Los datos preprocesados para el modelado también se pueden encontrar en la página web mencionada anteriormente para los conjuntos de datos cuya licencia de la fuente original lo permita.
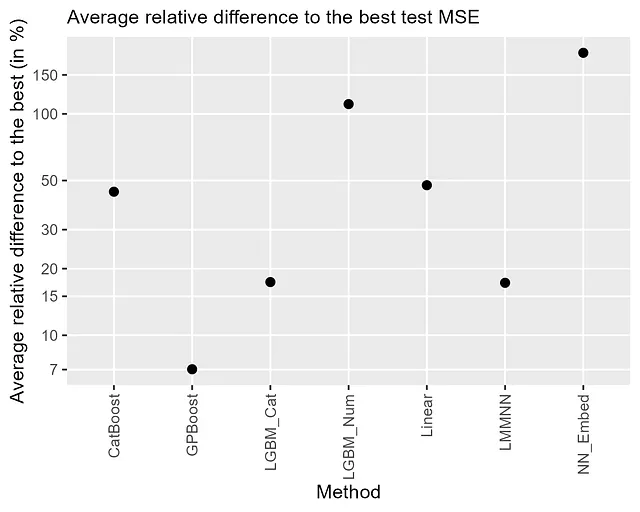
Los resultados se resumen en la Figura 2, que muestra las diferencias relativas promedio con respecto al MSE de prueba más bajo. Esto se obtiene primero calculando la diferencia relativa de un MSE de prueba de un método en comparación con el MSE más bajo para cada conjunto de datos, y luego tomando el promedio de todos los conjuntos de datos. Los resultados detallados se pueden encontrar en Sigrist [2023b] . Observamos que el impulso combinado de árboles y efectos aleatorios (GPBoost) tiene la mayor precisión de predicción con una diferencia relativa promedio a los mejores resultados de aproximadamente 7%. Los segundos mejores resultados se obtienen mediante el enfoque de variables categóricas de LightGBM (LGMB_Cat) y redes neuronales con efectos aleatorios (LMMNN), ambos con una diferencia relativa promedio al mejor método de aproximadamente 17%. CatBoost y los modelos de efectos mixtos lineales tienen un rendimiento considerablemente peor, con una diferencia relativa promedio al mejor método de casi el 50%. Dado que CatBoost “intenta resolver características categóricas” (Wikipedia a partir del 6 de julio de 2023), esto es algo desalentador. En general, las redes neuronales con embeddings tienen el peor rendimiento, con una diferencia relativa promedio al mejor resultado de más del 150%. El impulso de árboles con las variables categóricas transformadas en variables numéricas unidimensionales (LGBM_Num) tiene un rendimiento ligeramente mejor, con una diferencia relativa promedio al mejor resultado de aproximadamente el 100%. En su documentación en línea, LightGBM recomienda “Para una característica categórica con alta cardinalidad, a menudo funciona mejor tratar la característica como numérica” (a partir del 6 de julio de 2023) . Claramente llegamos a una conclusión diferente.
4 Conclusion
Hemos comparado empíricamente varios métodos en datos tabulares con variables categóricas de alta cardinalidad. Nuestros resultados muestran que, en primer lugar, los modelos de aprendizaje automático con efectos aleatorios tienen un mejor rendimiento que sus contrapartes sin efectos aleatorios, y en segundo lugar, el impulso de árboles con efectos aleatorios supera a las redes neuronales profundas con efectos aleatorios. Si bien puede haber varias razones posibles para este último hallazgo, esto está en línea con el trabajo reciente de Grinsztajn et al. [2022], quienes encuentran que el impulso de árboles supera a las redes neuronales profundas (y también a los bosques aleatorios) en datos tabulares sin variables categóricas de alta cardinalidad. De manera similar, Shwartz-Ziv y Armon [2022] concluyen que el impulso de árboles “supera a los modelos profundos en datos tabulares”.
En la Parte II de esta serie, mostraremos cómo aplicar la biblioteca GPBoost con una demostración utilizando uno de los conjuntos de datos del mundo real mencionados anteriormente. En la Parte III, mostraremos cómo se puede modelar datos longitudinales, también conocidos como paneles, con la biblioteca GPBoost.
Referencias
- T. Chen y C. Guestrin. XGBoost: Un sistema de aumento de árboles escalable. En Actas de la 22ª conferencia internacional de ACM SIGKDD sobre descubrimiento de conocimiento y minería de datos, páginas 785–794. ACM, 2016.
- W. D. Fisher. Sobre la agrupación para la máxima homogeneidad. Journal of the American statistical Association, 53(284):789–798, 1958.
- L. Grinsztajn, E. Oyallon y G. Varoquaux. ¿Por qué los modelos basados en árboles siguen superando al aprendizaje profundo en datos tabulares típicos? En S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho y A. Oh, editores, Avances en Sistemas de Información Neural, volumen 35, páginas 507–520. Curran Associates, Inc., 2022.
- C. Guo y F. Berkhahn. Incrustaciones de entidades de variables categóricas. Preimpresión de arXiv arXiv:1604.06737, 2016.
- A. Hajjem, F. Bellavance y D. Larocque. Bosque aleatorio de efectos mixtos para datos agrupados. Journal of Statistical Computation and Simulation, 84(6):1313–1328, 2014.
- G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye y T.-Y. Liu. LightGBM: Un árbol de decisión de aumento de gradiente altamente eficiente. En Avances en Sistemas de Información Neural, páginas 3149–3157, 2017.
- L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush y A. Gulin. CatBoost: aumento imparcial con características categóricas. En Avances en Sistemas de Información Neural, páginas 6638–6648, 2018.
- R. Shwartz-Ziv y A. Armon. Datos tabulares: El aprendizaje profundo no es todo lo que necesitas. Fusion de información, 81:84–90, 2022.
- F. Sigrist. Impulso del Proceso Gaussiano. The Journal of Machine Learning Research, 23(1):10565–10610, 2022.
- F. Sigrist. Impulso del Modelo Gaussiano Latente. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1894–1905, 2023a.
- F. Sigrist. Una comparación de métodos de aprendizaje automático para datos con variables categóricas de alta cardinalidad. Preimpresión de arXiv arXiv::2307.02071 2023b.
- G. Simchoni y S. Rosset. Uso de efectos aleatorios para tener en cuenta características categóricas de alta cardinalidad y medidas repetidas en redes neuronales profundas. Avances en Sistemas de Información Neural, 34:25111–25122, 2021.
- G. Simchoni y S. Rosset. Integración de efectos aleatorios en redes neuronales profundas. Journal of Machine Learning Research, 24(156):1–57, 2023.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 10 millones se registran en la aplicación rival de Twitter de Meta, Threads.
- Las ventas de automóviles nuevos despegan a medida que se alivia la escasez de chips.
- AI Sesgo Desafíos y Soluciones
- ¿Qué tan fácil es engañar a las herramientas de detección de inteligencia artificial?
- Actuadores neumáticos proporcionan aceleración similar a la de un robot cheetah
- Construyendo estructuras ópticas robustas hechas de oscuridad
- Cómo crear un plan de estudio autodidacta de ciencia de datos de 1 año utilizando la estacionalidad de tu cerebro






