Introducción al Aprendizaje Automático de Audio
Aprendizaje Automático de Audio
Actualmente estoy desarrollando un sistema de reconocimiento de voz en audio, por lo que necesitaba repasar mis conocimientos sobre los conceptos básicos relacionados con ello. Este artículo es el resultado de eso.
Introducción al Audio
Índice
- Introducción
Sonido —
- El sonido es una señal continua y tiene valores de señal infinitos
- Los dispositivos digitales requieren arreglos finitos y, por lo tanto, necesitamos convertirlos en una serie de valores discretos
- También conocido como Representación Digital
- Potencia del Sonido — Tasa a la que se transfiere la energía (Vatio)
- Intensidad del Sonido — Potencia del Sonido por unidad de área (Vatio/m**2)
Formatos de Archivos de Audio —
- .wav
- .flac (códec de audio sin pérdida gratuito)
- .mp3
Los formatos de archivos se diferencian por la forma en que comprimen la representación digital de la señal de audio
Pasos de Conversión —
- El micrófono captura una señal analógica.
- La onda de sonido luego se convierte en una señal eléctrica.
- Esta señal eléctrica se digitaliza mediante un convertidor analógico a digital.
Muestreo
- Es el proceso de medir el valor de una señal en puntos de tiempo fijos
- Una vez muestreada, la forma de onda muestreada está en un formato discreto
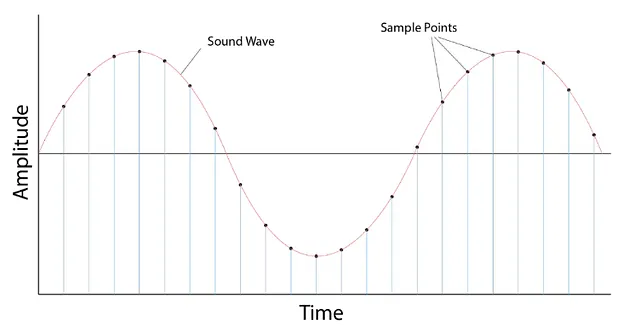
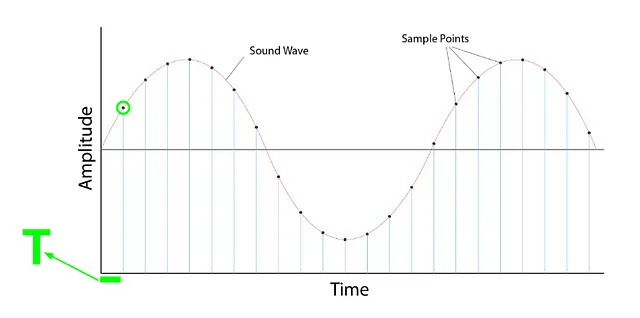
Tasa de Muestreo / Frecuencia de Muestreo
- Número de muestras tomadas por segundo
- Por ejemplo, si se toman 1000 muestras por segundo, entonces la tasa de muestreo (SR) = 1000
- UNA MAYOR SR -> MEJOR CALIDAD DE AUDIO
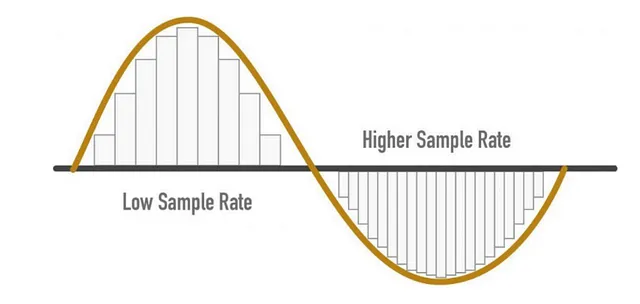
Consideraciones de SR
- Tasa de Muestreo = (Frecuencia más alta que se puede capturar de una señal) * 2
- Para el oído humano – la frecuencia audible es 8KHz, por lo tanto, podemos decir que la tasa de muestreo (SR) es 16KHz
- Aunque una mayor SR proporciona una mejor calidad de audio, eso no significa que debamos seguir aumentándola.
- Después de la línea requerida, no agrega información y solo aumenta el costo de cálculo
- Además, una baja SR puede causar una pérdida de información
Puntos para recordar —
- Mientras se entrena, todas las muestras de audio deben tener la misma tasa de muestreo
- Si estás utilizando un modelo pre-entrenado, la muestra de audio debe ser remuestreada para coincidir con la SR de los datos de audio con los que se entrenó el modelo
- Si se utilizan datos de diferentes SRs, entonces el modelo no se generaliza bien
Amplitud —
- El sonido se produce por un cambio en la presión del aire a frecuencias audibles por los humanos
- Amplitud — nivel de presión del sonido en ese instante medido en dB (decibelios)
- La amplitud es una medida de la intensidad
Profundidad de bits —
- Describe cuánta precisión puede describirse en un valor
- A mayor profundidad de bits, la representación digital se parece más de cerca a la onda continua de sonido original
- Los valores comunes de profundidad de bits son 16 bits y 24 bits
Cuantización —
Inicialmente, el audio está en forma continua, que es una onda suave. Para almacenarlo digitalmente, necesitamos almacenarlo en pequeños pasos; realizamos la cuantización para hacer eso.
- Conoce Retroformer Un elegante marco de inteligencia artificial para mejorar iterativamente los agentes de lenguaje grandes mediante el aprendizaje de un modelo retrospectivo de conexión.
- Transición de carrera de Ingeniero de Sistemas a Analista de Datos
- Investigadores de NVIDIA y la Universidad de Tel Aviv presentan Perfusion una red neuronal compacta de 100 KB con un tiempo de entrenamiento eficiente.
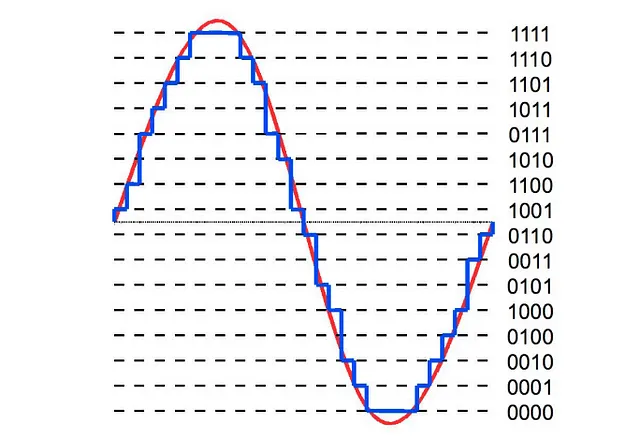
Puedes decir que la profundidad de bits es el número de pasos necesarios para representar el audio
- El audio de 16 bits necesita — 65536 pasos
- El audio de 24 bits necesita — 16777216 pasos
- Esta cuantización genera ruido, por lo tanto se prefiere una mayor profundidad de bits
- Aunque este ruido no es un problema
- El audio de 16 y 24 bits se almacena en muestras int, mientras que las muestras de audio de 32 bits se almacenan en puntos flotantes
- El modelo requiere un punto flotante, por lo que necesitamos convertir este audio en un punto flotante antes de entrenar el modelo
Implementación —
#cargar la bibliotecaimport librosa
#la función librosa.load devuelve el arreglo de audio y la tasa de muestreoaudio, tasa_muestreo = librosa.load(librosa.ex('pistachio'))
import matplotlib.pyplot as pltplt.figure().set_figwidth(12)librosa.display.waveshow(audio,sr = tasa_muestreo)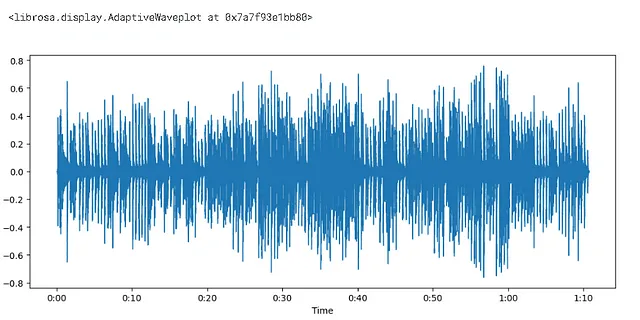
- La amplitud se trazó en el eje y y el tiempo en el eje x
- varía entre [-1.0,1.0] — ya es un número de punto flotante
print(len(audio))print(tasa_muestreo/1e3)>>1560384>>22.05
## Espectro de frecuenciaimport numpy as np# en lugar de centrarse en cada valor discreto, veamos solo los primeros 4096 valoresinput_data = audio[:4096]# DFT = transformada discreta de Fourier# este espectro de frecuencia se traza usando la DFTwindow = np.hanning(len(input_data))window>>array([0.00000000e+00, 5.88561497e-07, 2.35424460e-06, ..., 2.35424460e-06, 5.88561497e-07, 0.00000000e+00])
dft_input = input_data * window
figure = plt.figure(figsize = (15,5))plt.subplot(131)plt.plot(input_data)plt.title('entrada')plt.subplot(132)plt.plot(window)plt.title('ventana de Hanning')plt.subplot(133)plt.plot(dft_input)plt.title('entrada DFT')# se genera un gráfico similar para cada instancia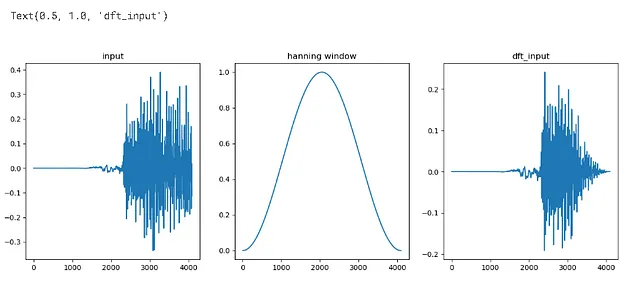
Transformada Discreta de Frecuencia = DFT
- ¿Estarías de acuerdo conmigo si dijera que hasta ahora tenemos datos de señales discretas?
- Si es así, puedes entender que hasta ahora teníamos los datos en el dominio del tiempo y ahora queremos convertirlos en el dominio de frecuencia. Por eso el señor DFT está aquí para ayudar.
# calcular la DFT - transformada discreta de Fourierdft = np.fft.rfft(dft_input)plt.plot(dft)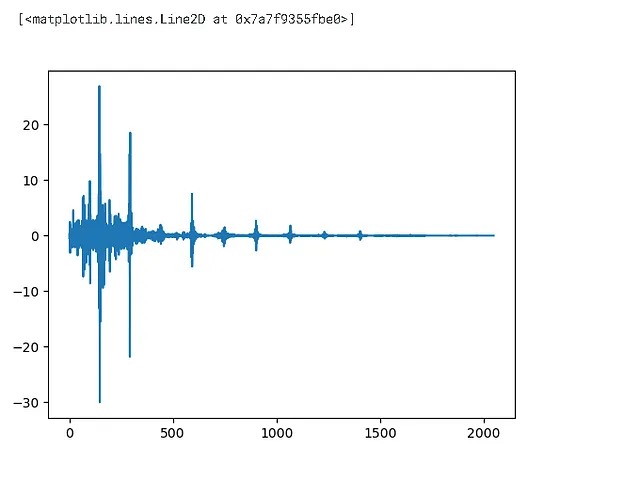
# amplitudamplitud = np.abs(dft)# convertirlo a dBamplitud_dB = librosa.amplitude_to_db(amplitud, ref=np.max)# a veces las personas quieren usar el espectro de potencia -> A**2¿Por qué tomar el valor absoluto?
Cuando tomamos la amplitud, aplicamos la función abs, la razón es el número complejo
- la salida devuelta después de la transformada de Fourier está en forma compleja, y tomar el valor absoluto nos dio la magnitud, por lo tanto, el valor absoluto.
print(len(amplitud))print(len(dft_input))print(len(dft))>>2049>>4096>>2049¿Por qué el arreglo actualizado es (mitad+1) del arreglo original?
Cuando se calcula la DFT para una entrada puramente real, la salida es hermitiana-simétrica, es decir, los términos de frecuencia negativa son simplemente los conjugados complejos de los términos de frecuencia positiva correspondientes, y los términos de frecuencia negativa son redundantes. Esta función no calcula los términos de frecuencia negativa, y la longitud del eje transformado de la salida es por lo tanto n//2 + 1. [fuente – documentación]
# frecuenciafrecuencia = librosa.fft_frequencies(n_fft=len(input_data), sr=sampling_rate)
plt.figure().set_figwidth(12)plt.plot(frecuencia, amplitud_dB)plt.xlabel("Frecuencia (Hz)")plt.ylabel("Amplitud (dB)")plt.xscale("log")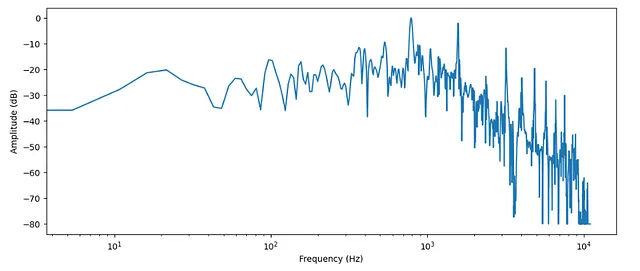
- Como se mencionó anteriormente, dominio del tiempo -> dominio de frecuencia
- El dominio de frecuencia generalmente se representa en una escala logarítmica
Espectrogramas —
- muestra cómo cambia la frecuencia con respecto al tiempo
- El algoritmo que realiza esta transformación es STFT = transformada de tiempo-frecuencia corta
Cómo crear un espectrograma —
- los espectrogramas son una pila de transformaciones de frecuencia, ¿cómo? veamos
- Para un audio dado, tomamos segmentos pequeños y encontramos su espectro de frecuencia. Después, los apilamos a lo largo del eje del tiempo. El diagrama resultante es un espectrograma
librosa.stftdivide por defecto en 2048 segmentos
Espectro de Frecuencia —
- Representa la amplitud de diferentes frecuencias en un solo momento en el tiempo.
- El espectro de frecuencia es más adecuado para comprender los componentes de frecuencia presentes en una señal en un instante específico. Ambas representaciones son herramientas valiosas para comprender las características de las señales en el dominio de frecuencia.
- AMPLITUD vs. FRECUENCIA
Espectrograma —
- Representa los cambios en el contenido de frecuencia a lo largo del tiempo al descomponer la señal en segmentos y trazar sus espectros de frecuencia a lo largo del tiempo.
- El espectrograma es particularmente útil para analizar y visualizar señales que varían en el tiempo, como señales de audio o datos de series de tiempo, ya que proporciona información sobre cómo evolucionan los componentes de frecuencia en diferentes intervalos de tiempo.
- FRECUENCIA vs. TIEMPO
spectogram = librosa.stft(audio)
spectogram_to_dB = librosa.amplitude_to_db(np.abs(spectogram), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(spectogram_to_dB, x_axis="time", y_axis="hz")
plt.colorbar()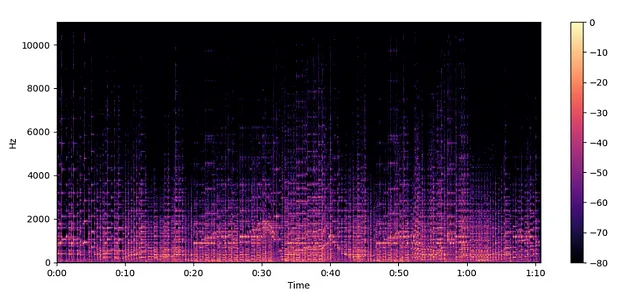
Mel Spectrogramas —
- El espectrograma en diferentes escalas de frecuencia.
Antes de continuar, uno debe recordar que:
- En frecuencias más bajas, los humanos son más sensibles a los cambios de audio que en frecuencias más altas
- Esta sensibilidad cambia de manera logarítmica con un aumento de la frecuencia
- Entonces, en términos más simples, un espectrograma de Mel es una versión comprimida del espectrograma.
MelSpectogram = librosa.feature.melspectrogram(y=audio, sr=sampling_rate, n_mels=128, fmax=8000)
MelSpectogram_dB = librosa.power_to_db(MelSpectogram, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(MelSpectogram_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()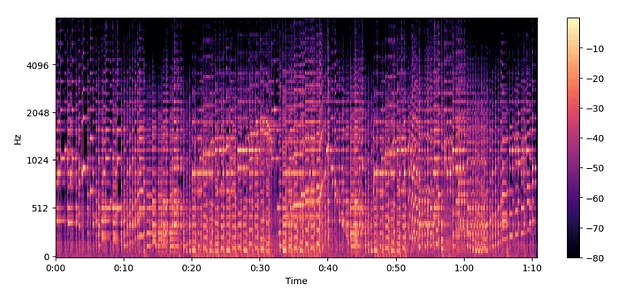
- El ejemplo anterior utiliza
librosa.power_to_db()ya quelibrosa.feature.melspectrogram()se utiliza para crear un espectrograma de potencia.
Conclusión —
El Espectrograma de Mel ayuda a capturar características más significativas que el espectrograma normal y, por lo tanto, es popular.
Referencia —
Huggingface
Kernel personal de Kaggle (para practicar)
Redes Sociales —
Kaggle
Si te gustó el artículo, no olvides mostrar tu aprecio aplaudiendo. Nos vemos en el próximo cuaderno, donde veremos ‘Cómo cargar y transmitir datos de audio.’
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Revolucionando el Diseño de Proteínas Cómo esta investigación de IA aumentó las tasas de éxito diez veces con mejoras en el Aprendizaje Profundo
- Descifrando el comportamiento colectivo Cómo la inferencia bayesiana activa impulsa los movimientos naturales de los grupos de animales
- Conoce Jupyter AI Desatando el poder de la inteligencia artificial en los cuadernos de Jupyter
- Tres desafíos en la implementación de modelos generativos en producción
- Construyendo PCA desde cero
- Cómo construir un pipeline de detección de cambios de datos completamente automatizado
- Fundamentos de Estadística para Científicos de Datos y Analistas






