Aprendizaje automático con efectos mixtos para datos longitudinales y de panel con GPBoost (Parte III)
Aprendizaje automático con GPBoost para datos longitudinales y de panel (Parte III)
Una demostración de GPBoost en Python y R utilizando datos del mundo real
En la Parte I y Parte II de esta serie, mostramos cómo se pueden utilizar efectos aleatorios para modelar variables categóricas de alta cardinalidad en modelos de aprendizaje automático, y dimos una introducción a la biblioteca GPBoost que implementa el algoritmo GPBoost que combina el impulso de árbol con efectos aleatorios. En este artículo, demostramos cómo se pueden utilizar los paquetes de Python y R de la biblioteca GPBoost para datos longitudinales (también conocidos como medidas repetidas o datos de panel). Puede ser útil leer primero la Parte II de esta serie, ya que brinda una primera introducción a la biblioteca GPBoost. En esta demostración se utiliza la versión 1.2.1 de GPBoost.
Tabla de contenidos
∘ 1 Datos: descripción, carga y división de muestra∘ 2 Opciones de modelado para datos longitudinales en GPBoost · · 2.1 Efectos aleatorios agrupados por sujeto · · 2.2 Solo efectos fijos · · 2.3 Efectos aleatorios agrupados por sujeto y tiempo · · 2.4 Efectos aleatorios por sujeto con pendientes aleatorias temporales · · 2.5 Modelos AR(1) / de proceso gaussiano específicos por sujeto · · 2.6 Efectos aleatorios agrupados por sujeto y modelo AR(1) conjunto∘ 3 Entrenamiento de un modelo GPBoost∘ 4 Selección de parámetros de ajuste∘ 5 Predicción∘ 6 Conclusión y referencias
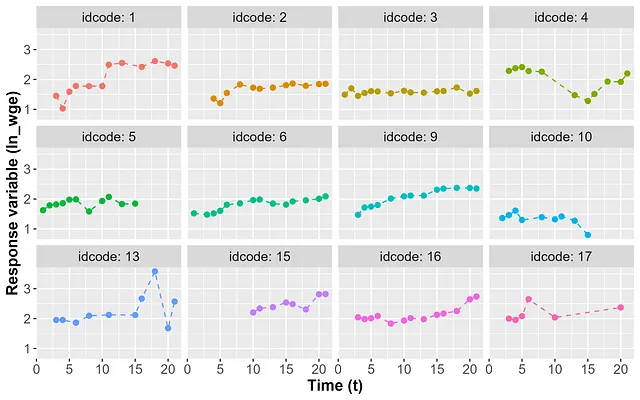
1 Datos: descripción, carga y división de muestra
Los datos utilizados en esta demostración son los datos salariales que ya se utilizaron en la Parte II. Se pueden descargar desde aquí. El conjunto de datos contiene un total de 28,013 muestras para 4,711 personas para las cuales se midieron los datos durante varios años. Estos datos se llaman datos longitudinales o datos de panel, ya que para cada sujeto (ID de persona = idcode), se recopilaron datos repetidamente a lo largo del tiempo (años = t). En otras palabras, las muestras para cada nivel de la variable categórica idcode son mediciones repetidas a lo largo del tiempo. La variable de respuesta es el salario real logarítmico (ln_wage), y los datos incluyen varias variables predictoras como edad, trabajo total…
- Explora el poder de las imágenes dinámicas con Text2Cinemagraph una nueva herramienta de IA para la generación de cinemagraphs a partir de indicaciones de texto
- Introducción práctica a los modelos de Transformer BERT
- Principios efectivos de ingeniería de indicaciones para la aplicación de IA generativa
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Esta es la razón por la que deberías leer esto antes de usar Pandas en la limpieza de datos
- ChatGPT destronado cómo Claude se convirtió en el nuevo líder de IA
- Justin McGill, Fundador y CEO de Content at Scale – Serie de entrevistas
- Conoce a Tongyi Qianwen, el competidor de ChatGPT de Alibaba un modelo de lenguaje grande que se integrará en sus altavoces inteligentes Tmall Genie y en la plataforma de mensajería laboral DingTalk.
- Sobre el aprendizaje en presencia de grupos subrepresentados
- Desbloqueando los secretos de la Dimensión de Cambio Lento (SCD) Una Visión Integral de 8 Tipos
- Crea tu propio sitio web impresionante en minutos de forma gratuita






