Aprendizaje automático a gran escala Paralelismo de modelos frente a paralelismo de datos
Aprendizaje automático a gran escala paralelismo de modelos vs paralelismo de datos
Descifrando los secretos del aprendizaje automático a gran escala
Introducción
A medida que los modelos se vuelven cada vez más complejos y los conjuntos de datos se vuelven gigantescos, la necesidad de formas eficientes de distribuir las cargas de trabajo computacionales es más importante que nunca. Las configuraciones de una sola computadora de la vieja escuela no pueden seguir el ritmo de las necesidades actuales de computación de aprendizaje automático.
Pregunta clave: ¿Cómo podemos distribuir estos trabajos complejos de aprendizaje automático (entrenamiento e inferencia del modelo) de manera efectiva en múltiples recursos informáticos?
La respuesta se encuentra en dos técnicas clave de computación de aprendizaje automático distribuido: Paralelismo de Modelo y Paralelismo de Datos. Cada una tiene sus fortalezas, debilidades y casos de uso ideales. En este artículo, profundizaremos en estas técnicas, explorando sus matices y comparándolas directamente.
¿Qué es el Paralelismo de Modelo y el Paralelismo de Datos?
Paralelismo de Modelo
Este método implica distribuir diferentes partes del modelo de aprendizaje automático en múltiples recursos informáticos, como GPUs. Es el antídoto perfecto para esos modelos sobredimensionados que no caben en la memoria de una sola máquina.
- Visión del PM Modi sobre la regulación de la IA en India Cumbre B20 2023
- IA y el futuro del fútbol universitario
- Solucionando cuellos de botella en la tubería de entrada de datos con PyTorch Profiler y TensorBoard
Paralelismo de Datos
Por otro lado, el paralelismo de datos mantiene el modelo en cada máquina pero distribuye el conjunto de datos en fragmentos o lotes más pequeños en múltiples recursos. Esta técnica es útil cuando se tienen conjuntos de datos grandes pero modelos que se ajustan fácilmente en la memoria.
Paralelismo de Modelo: Una Mirada Más Cercana
¿Cuándo usarlo?
¿Alguna vez has intentado cargar una gran red neuronal en tu GPU y has obtenido un temido error de “sin memoria”? Eso es como tratar de encajar una pieza cuadrada en un agujero redondo. Simplemente no funcionará. Pero no te preocupes, el paralelismo de modelo está aquí para ayudarte.
¿Cómo funciona?
Imagina que tu red neuronal es como un edificio de varios pisos, donde cada piso es una capa de la red. Ahora, ¿qué pasaría si pudieras colocar cada piso de ese edificio en un terreno diferente (o en nuestro caso, una GPU diferente)? De esa manera, no estás tratando de apilar todo el rascacielos en un pequeño terreno. En términos técnicos, esto significa dividir tu modelo y poner diferentes partes en diferentes GPUs.
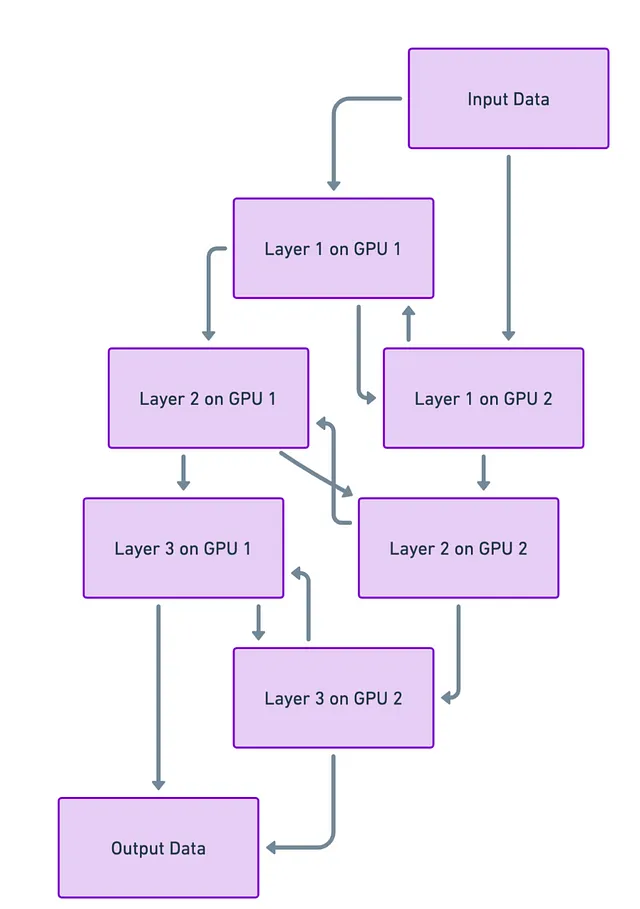
Desafíos
Pero no todo es un camino fácil. Cuando divides el edificio, o la red neuronal, aún necesitas escaleras y ascensores (o vías de datos) para moverte entre los pisos (capas). Y a veces, estos pueden atascarse. En otras palabras, el desafío principal es hacer que las diferentes partes se comuniquen entre sí de manera rápida y fluida. Si esta comunicación es lenta, puede ralentizar todo el proceso de aprendizaje o “entrenamiento” del modelo.
Paralelismo de Datos: Una Mirada Más Cercana
¿Cuándo usarlo?
Imagina que tienes una gran cantidad de datos, pero tu modelo de aprendizaje automático no es demasiado complejo. En este caso, el paralelismo de datos es como tu licuadora de cocina de confianza; puede manejar fácilmente todos los ingredientes que le arrojes sin abrumarse.
¿Cómo funciona?
Imagina que cada computadora o GPU es una cocina separada con su propia licuadora (el modelo). Tomas tu gran montón de datos y lo divides en porciones más pequeñas. Cada “cocina” obtiene una pequeña porción de datos y su propia licuadora para trabajar en esos datos. De esta manera, varias cocinas están haciendo batidos (calculando gradientes) al mismo tiempo.
Después de que cada cocina termine de licuar, llevas todos los batidos a un solo lugar. Luego los mezclas juntos para hacer un batido gigante y perfectamente mezclado (actualizando el modelo en función de todos los cálculos individuales).
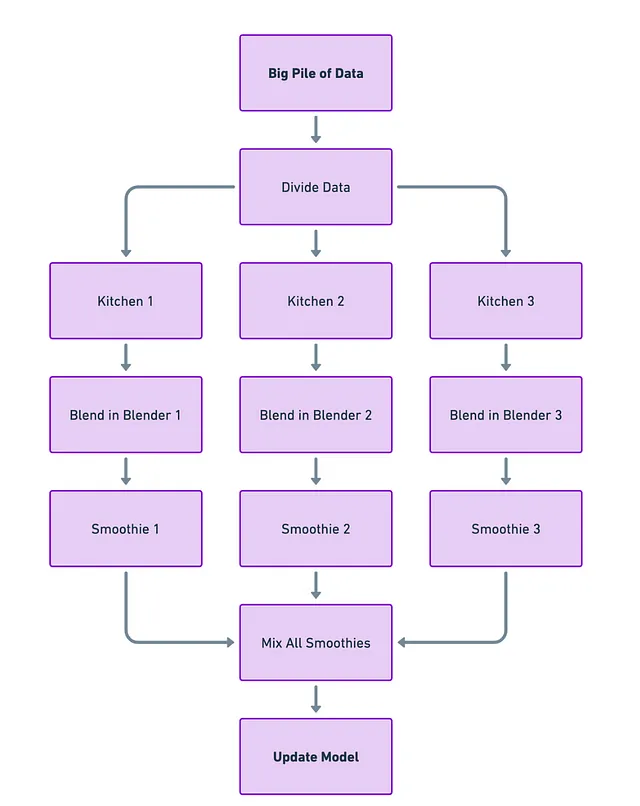
Desafíos
La parte complicada es el último paso: mezclar todos esos batidos de manera eficiente. Si eres lento o desordenado al combinarlos, no solo perderás tiempo, sino que también podrías terminar con un batido final no tan bueno (entrenamiento del modelo ineficiente). Por lo tanto, el desafío consiste en reunir todo de manera eficiente y rápida.
En términos técnicos, esto significa que debes encontrar una forma rápida de recopilar todos los gradientes calculados de cada GPU y actualizar el modelo. Si no lo haces bien, tu modelo podría tardar más en entrenar o incluso funcionar mal cuando lo uses para tareas reales.
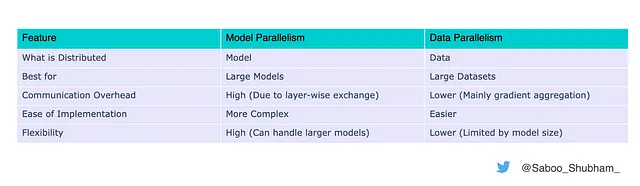
Resumen de diferencias
¿Por qué no ambos?
En el siempre complejo campo del aprendizaje automático, rara vez hay una solución única para todos. Una combinación sinérgica de paralelismo de modelo y paralelismo de datos se emplea a menudo para obtener resultados óptimos. Por ejemplo, podrías dividir un modelo grande en múltiples GPU (paralelismo de modelo) y luego distribuir los datos a cada una de estas configuraciones paralelas (paralelismo de datos).
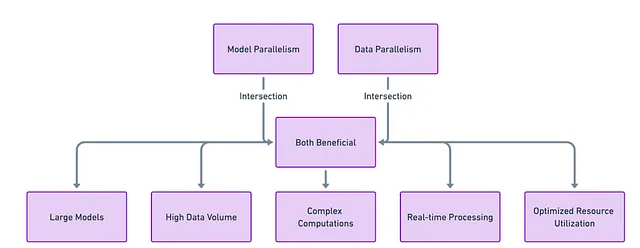
Una mezcla de paralelismo de modelo y paralelismo de datos a menudo es la clave para perfeccionar tu “receta” de aprendizaje automático.
La analogía del rango de cocina para el aprendizaje automático
En esta analogía, el rango de cocina es como una sola GPU o computadora. Tiene tanto un horno como una cocina, que se pueden usar al mismo tiempo para diferentes tareas de cocina.
Horno = Paralelismo de modelo
Si tienes un pavo que es demasiado grande para entrar en el horno, podrías cortarlo en trozos más pequeños para cocinarlos por separado, por ejemplo, el pecho en una sección del horno y las piernas en otra. Esto es similar al paralelismo de modelo, donde un modelo grande se divide en múltiples GPU. En este caso, los compartimentos del horno de un solo rango de cocina representan partes de una GPU o un recurso informático.
Cocina = Paralelismo de datos
Ahora, supongamos que tienes diferentes platos acompañantes que estás cocinando en las hornillas de la cocina. Puedes preparar el puré de papas en una hornilla mientras salteas los frijoles verdes en otra. Aquí, cada hornilla representa un enfoque de paralelismo de datos, donde diferentes porciones de los datos se procesan de manera independiente pero dentro de la misma GPU o entorno informático.
Combinando ambos para un festín
Finalmente, para completar tu festín, usarías tanto el horno como la cocina al mismo tiempo. Las partes del pavo están en el horno (paralelismo de modelo) y los platos acompañantes están en la cocina (paralelismo de datos). Una vez que la cocción esté completa, combinas todas las partes del pavo y los acompañantes para servir una comida completa. De manera similar, en el aprendizaje automático, combinar el paralelismo de modelo y el paralelismo de datos te permite procesar de manera eficiente modelos grandes y conjuntos de datos grandes, lo que en última instancia resulta en un modelo entrenado con éxito.
Al aprovechar tanto el ‘horno’ como la ‘estufa’ en tu ‘cocina’ de aprendizaje automático, puedes cocinar tus datos y modelos de manera más eficiente, aprovechando al máximo todos los recursos que tienes a mano.
Conclusión
A medida que el campo del aprendizaje automático continúa evolucionando, la importancia de técnicas como el paralelismo de modelos y datos solo crecerá y será cada vez más relevante en las cargas de trabajo diarias de ML. Comprender los matices de ambos es fundamental para cualquier persona que busque desarrollar e implementar modelos de aprendizaje automático a gran escala como LLMs, Stable Diffusion, etc.
Al elegir la técnica adecuada o una combinación de ambas, puedes superar los desafíos del aprendizaje automático moderno y desbloquear la escalabilidad y eficiencia para tus cargas de trabajo de ML.
¿Interesado en estar al día con lo último en aprendizaje automático? Sigue mi viaje para estar actualizado con los nuevos desarrollos de IA de vanguardia 👇
Conéctate conmigo: LinkedIn | Twitter | Github

Si te gustó esta publicación o te resultó útil, tómate un minuto para presionar el botón de aplauso, aumenta la visibilidad de la publicación para otros usuarios de VoAGI.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Versión de ChatGPT para Grandes Empresas a ser lanzada por OpenAI
- Tutorial Avanzado Cómo Dominar Matplotlib como un Verdadero Jefe
- Revolucionando la productividad del correo electrónico Cómo la IA de SaneBox transforma tu experiencia en la bandeja de entrada
- Conoce a Nous-Hermes-Llama2-70b Un modelo de lenguaje de última generación ajustado finamente en más de 300,000 instrucciones.
- Cadenas de Markov de Tiempo Discreto – Identificando Trayectorias Ganadoras de Clientes en una Campaña de Devolución de Dinero
- Seis recursos útiles para ingenieros
- 5 Razones para considerar un Bootcamp de Ciencia de Datos antes de la educación superior






