Por qué la API de OpenAI es más cara para los idiomas que no son inglés
API de OpenAI más cara para idiomas no ingleses
Más allá de las palabras: Cómo el codificado de pares de bytes y el codificado Unicode influyen en las disparidades de precios

Después de publicar mi artículo reciente sobre cómo estimar el costo de la API de OpenAI, recibí un comentario interesante de alguien que notó que la API de OpenAI es mucho más cara en otros idiomas, como aquellos que utilizan caracteres chinos, japoneses o coreanos (CJK), que en inglés.
No estaba al tanto de este problema, pero rápidamente me di cuenta de que este es un campo de investigación activo: A principios de este año, un artículo llamado “Los tokenizadores de modelos de lenguaje introducen desigualdad entre idiomas” de Petrov et al. [2] mostró que “el mismo texto traducido a diferentes idiomas puede tener longitudes de tokenización drásticamente diferentes, con diferencias de hasta 15 veces en algunos casos”.
A modo de recordatorio, la tokenización es el proceso de dividir un texto en una lista de tokens, que son secuencias comunes de caracteres en un texto.
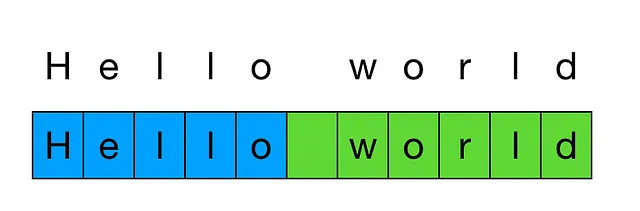
La diferencia en las longitudes de tokenización es un problema porque la API de OpenAI se factura en unidades de 1,000 tokens. Por lo tanto, si tienes hasta 15 veces más tokens en un texto comparable, esto resultará en 15 veces los costos de la API.
- Desenmascarando Deepfakes Aprovechando los patrones de estimación de la posición de la cabeza para mejorar la precisión de detección
- Este boletín de inteligencia artificial es todo lo que necesitas #60
- Qué saber sobre StableCode el generador de código de IA de Stability AI
Experimento: Número de Tokens en Diferentes Idiomas
Traduzcamos la frase “Hola mundo” al japonés (こんにちは世界) y transcribámosla al hindi (हैलो वर्ल्ड). Cuando tokenizamos las nuevas frases con el tokenizador cl100k_base utilizado en los modelos GPT de OpenAI, obtenemos los siguientes resultados (puedes encontrar el código que utilicé para estos experimentos al final de este artículo):
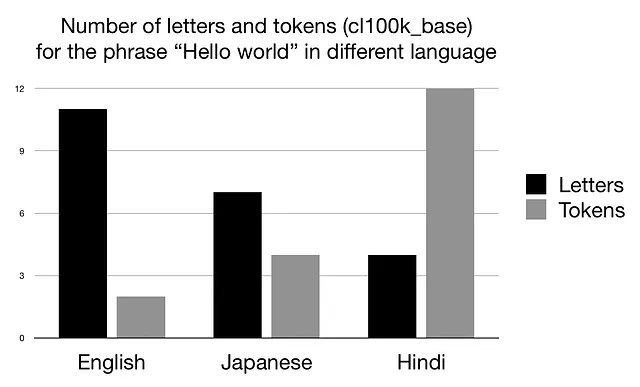
A partir del gráfico anterior, podemos hacer dos observaciones interesantes:
- El número de letras para…
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Los modelos de IA son poderosos, pero ¿son biológicamente plausibles?
- Aprende mientras buscas (y navegas) utilizando la IA generativa
- Preguntas y respuestas inteligentes de video y audio con soporte multilingüe utilizando LLMs en Amazon SageMaker
- Cómo Amazon Shopping utiliza la moderación de contenido de Amazon Rekognition para revisar imágenes dañinas en las reseñas de productos
- Avances en la comprensión de documentos
- Gran Tecnología y IA Generativa ¿Controlará la Gran Tecnología la IA Generativa?
- La IA generativa puede cambiar el mundo, pero solo si la infraestructura de datos se mantiene al día






