Anunciando la vista previa de Amazon SageMaker Profiler Haga un seguimiento y visualice datos detallados de rendimiento de hardware para sus cargas de trabajo de entrenamiento de modelos.
Anunciando Amazon SageMaker Profiler seguimiento y visualización de datos de rendimiento de hardware para entrenamiento de modelos.
Hoy nos complace anunciar la vista previa de Amazon SageMaker Profiler, una capacidad de Amazon SageMaker que proporciona una vista detallada de los recursos informáticos de AWS provisionados durante el entrenamiento de modelos de aprendizaje profundo en SageMaker. Con SageMaker Profiler, puede realizar un seguimiento de todas las actividades en CPUs y GPUs, como la utilización de CPU y GPU, las ejecuciones de núcleos en GPUs, los lanzamientos de núcleos en CPUs, las operaciones de sincronización, las operaciones de memoria en GPUs, las latencias entre lanzamientos de núcleos y ejecuciones correspondientes, y la transferencia de datos entre CPUs y GPUs. En esta publicación, le mostramos las capacidades de SageMaker Profiler.
SageMaker Profiler proporciona módulos de Python para anotar scripts de entrenamiento de PyTorch o TensorFlow y activar SageMaker Profiler. También ofrece una interfaz de usuario (UI) que visualiza el perfil, un resumen estadístico de los eventos perfilados y la línea de tiempo de un trabajo de entrenamiento para realizar un seguimiento y comprender la relación temporal de los eventos entre GPUs y CPUs.
La necesidad de perfilar trabajos de entrenamiento
Con el auge del aprendizaje profundo (DL), el aprendizaje automático (ML) se ha vuelto intensivo en cómputo y datos, lo que generalmente requiere clústeres multinodo y multi-GPU. A medida que los modelos de última generación crecen en tamaño en el orden de billones de parámetros, su complejidad computacional y coste también aumentan rápidamente. Los profesionales de ML tienen que enfrentarse a desafíos comunes de utilización eficiente de recursos al entrenar modelos tan grandes. Esto es especialmente evidente en los modelos de lenguaje grandes (LLMs), que típicamente tienen miles de millones de parámetros y, por lo tanto, requieren clústeres multinodo de GPU grandes para entrenarlos de manera eficiente.
Al entrenar estos modelos en clústeres de cómputo grandes, podemos encontrarnos con desafíos de optimización de recursos informáticos como cuellos de botella de E/S, latencias de lanzamiento de núcleo, límites de memoria y bajos niveles de utilización de recursos. Si la configuración del trabajo de entrenamiento no está optimizada, estos desafíos pueden resultar en una utilización ineficiente del hardware y tiempos de entrenamiento más largos o ejecuciones de entrenamiento incompletas, lo que aumenta los costes y los plazos generales del proyecto.
- El algoritmo de Google hace que la encriptación FIDO sea segura contra ordenadores cuánticos
- El mito de la IA de ‘código abierto
- Un derrame le robó la capacidad de hablar a los 30 años. La IA está ayudando a restaurarla años después.
Requisitos previos
Los siguientes son los requisitos previos para comenzar a usar SageMaker Profiler:
- Un dominio de SageMaker en su cuenta de AWS – Para obtener instrucciones sobre cómo configurar un dominio, consulte Inicio en el dominio de Amazon SageMaker mediante una configuración rápida. También necesita agregar perfiles de usuario de dominio para que los usuarios individuales puedan acceder a la aplicación de interfaz de usuario de SageMaker Profiler. Para obtener más información, consulte Agregar y quitar perfiles de usuario de dominio de SageMaker.
- Permisos – La siguiente lista es el conjunto mínimo de permisos que se deben asignar al rol de ejecución para utilizar la aplicación de interfaz de usuario de SageMaker Profiler:
sagemaker:CreateAppsagemaker:DeleteAppsagemaker:DescribeTrainingJobsagemaker:SearchTrainingJobss3:GetObjects3:ListBucket
Preparar y ejecutar un trabajo de entrenamiento con SageMaker Profiler
Para comenzar a capturar las ejecuciones de núcleos en GPUs mientras se ejecuta el trabajo de entrenamiento, modifique su script de entrenamiento utilizando los módulos de Python de SageMaker Profiler. Importe la biblioteca y agregue los métodos start_profiling() y stop_profiling() para definir el inicio y el final del perfilado. También puede utilizar anotaciones personalizadas opcionales para agregar marcadores en el script de entrenamiento para visualizar las actividades del hardware durante operaciones particulares en cada paso.
Hay dos enfoques que puede tomar para perfilar sus scripts de entrenamiento con SageMaker Profiler. El primer enfoque se basa en perfilar funciones completas; el segundo enfoque se basa en perfilar líneas de código específicas en funciones.
Para perfilar por funciones, use el administrador de contexto smppy.annotate para anotar funciones completas. El siguiente ejemplo de script muestra cómo implementar el administrador de contexto para envolver el bucle de entrenamiento y las funciones completas en cada iteración:
import smppy
sm_prof = smppy.SMProfiler.instance()
config = smppy.Config()
config.profiler = {
"EnableCuda": "1",
}
sm_prof.configure(config)
sm_prof.start_profiling()
for epoch in range(args.epochs):
if world_size > 1:
sampler.set_epoch(epoch)
tstart = time.perf_counter()
for i, data in enumerate(trainloader, 0):
with smppy.annotate("step_"+str(i)):
inputs, labels = data
inputs = inputs.to("cuda", non_blocking=True)
labels = labels.to("cuda", non_blocking=True)
optimizer.zero_grad()
with smppy.annotate("Forward"):
outputs = net(inputs)
with smppy.annotate("Loss"):
loss = criterion(outputs, labels)
with smppy.annotate("Backward"):
loss.backward()
with smppy.annotate("Optimizer"):
optimizer.step()
sm_prof.stop_profiling()También puedes usar smppy.annotation_begin() y smppy.annotation_end() para anotar líneas específicas de código en funciones. Para obtener más información, consulta la documentación.
Configurar el lanzador del trabajo de entrenamiento de SageMaker
Después de haber anotado y configurado los módulos de inicio de perfilador, guarda el script de entrenamiento y prepara el estimador del marco de trabajo de SageMaker para el entrenamiento utilizando el SDK de Python de SageMaker.
-
Configura un objeto
profiler_configutilizando los módulosProfilerConfigyProfilerde la siguiente manera:from sagemaker import ProfilerConfig, Profiler profiler_config = ProfilerConfig( profiler_params = Profiler(cpu_profiling_duration=3600)) -
Crea un estimador de SageMaker con el objeto
profiler_configcreado en el paso anterior. El siguiente código muestra un ejemplo de creación de un estimador de PyTorch:import sagemaker from sagemaker.pytorch import PyTorch estimator = PyTorch( framework_version="2.0.0", image_uri="763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-sagemaker", role=sagemaker.get_execution_role(), entry_point="train_with_profiler_demo.py", # tu punto de entrada del trabajo de entrenamiento source_dir=source_dir, # directorio fuente para tu script de entrenamiento output_path=output_path, base_job_name="sagemaker-profiler-demo", hyperparameters=hyperparameters, # si los hay instance_count=1, instance_type=ml.p4d.24xlarge, profiler_config=profiler_config )
Si quieres crear un estimador de TensorFlow, importa sagemaker.tensorflow.TensorFlow en su lugar, y especifica una de las versiones de TensorFlow compatibles con SageMaker Profiler. Para obtener más información sobre los marcos de trabajo y tipos de instancia compatibles, consulta los marcos de trabajo compatibles.
-
Inicia el trabajo de entrenamiento ejecutando el método
fit:estimator.fit(wait=False)
Iniciar la interfaz de usuario de SageMaker Profiler
Cuando el trabajo de entrenamiento esté completo, puedes iniciar la interfaz de usuario de SageMaker Profiler para visualizar y explorar el perfil del trabajo de entrenamiento. Puedes acceder a la aplicación de la interfaz de usuario de SageMaker Profiler a través de la página de inicio de SageMaker Profiler en la consola de SageMaker o a través del dominio de SageMaker.
Para iniciar la aplicación de la interfaz de usuario de SageMaker Profiler en la consola de SageMaker, sigue los siguientes pasos:
- En la consola de SageMaker, selecciona Profiler en el panel de navegación.
- En Comenzar, selecciona el dominio en el que deseas iniciar la aplicación de la interfaz de usuario de SageMaker Profiler.
Si tu perfil de usuario solo pertenece a un dominio, no verás la opción para seleccionar un dominio.
- Selecciona el perfil de usuario para el que deseas iniciar la aplicación de la interfaz de usuario de SageMaker Profiler.
Si no hay un perfil de usuario en el dominio, selecciona Crear perfil de usuario. Para obtener más información sobre cómo crear un nuevo perfil de usuario, consulta Agregar y quitar perfiles de usuario.
- Selecciona Abrir Profiler.
También puedes iniciar la interfaz de usuario de SageMaker Profiler desde la página de detalles del dominio.
Obtener información del perfilador de SageMaker
Cuando abras la interfaz de usuario de SageMaker Profiler, se abrirá la página Seleccionar y cargar un perfil, como se muestra en la siguiente captura de pantalla.
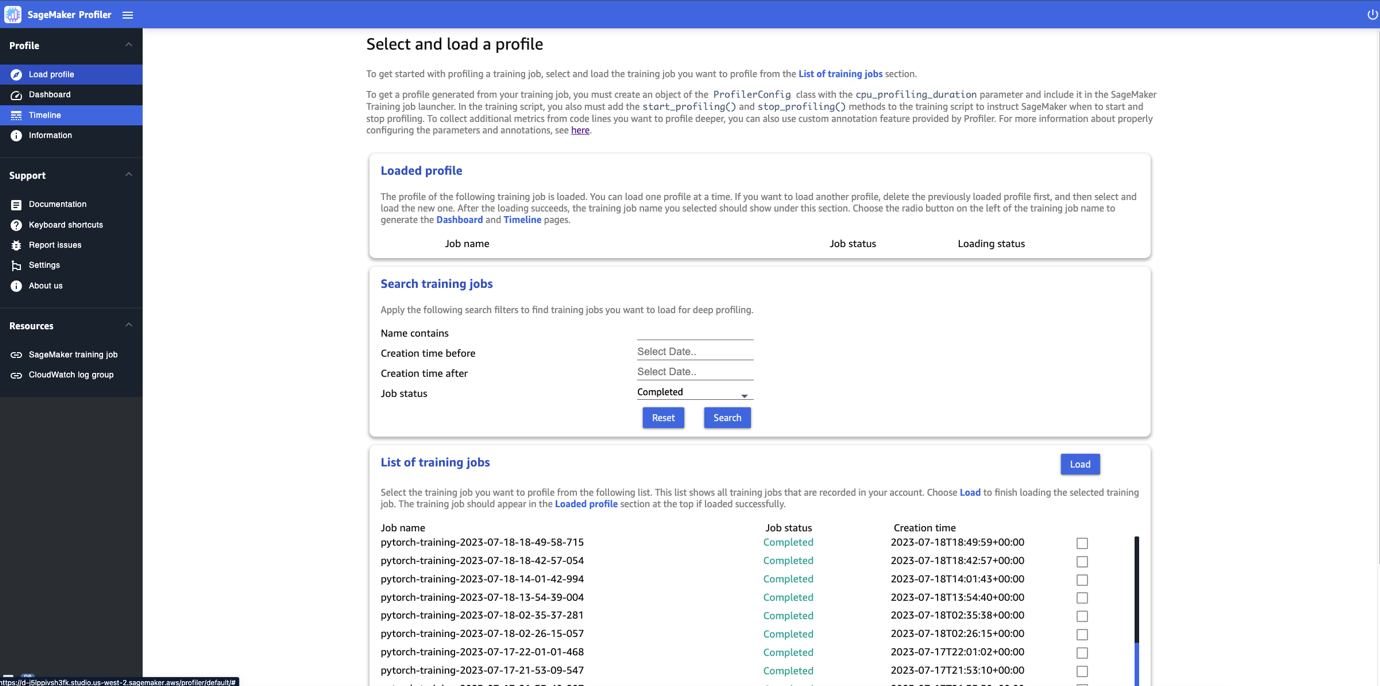
Puedes ver una lista de todos los trabajos de entrenamiento que se han enviado a SageMaker Profiler y buscar un trabajo de entrenamiento en particular por su nombre, hora de creación y estado de ejecución (En progreso, Completado, Fallido, Detenido o Deteniéndose). Para cargar un perfil, selecciona el trabajo de entrenamiento que deseas ver y elige Cargar. El nombre del trabajo debería aparecer en la sección Perfil cargado en la parte superior.
Elige el nombre del trabajo para generar el panel de control y la línea de tiempo. Ten en cuenta que cuando elijas el trabajo, la interfaz de usuario abre automáticamente el panel de control. Solo puedes cargar y visualizar un perfil a la vez. Para cargar otro perfil, primero debes descargar el perfil cargado anteriormente. Para descargar un perfil, elige el ícono de la papelera en la sección Perfil cargado.
Para este artículo, visualizamos el perfil de un trabajo de entrenamiento de ALBEF en dos instancias ml.p4d.24xlarge.
Una vez que termines de cargar y seleccionar el trabajo de entrenamiento, la interfaz de usuario abre la página Panel de control, como se muestra en la siguiente captura de pantalla.
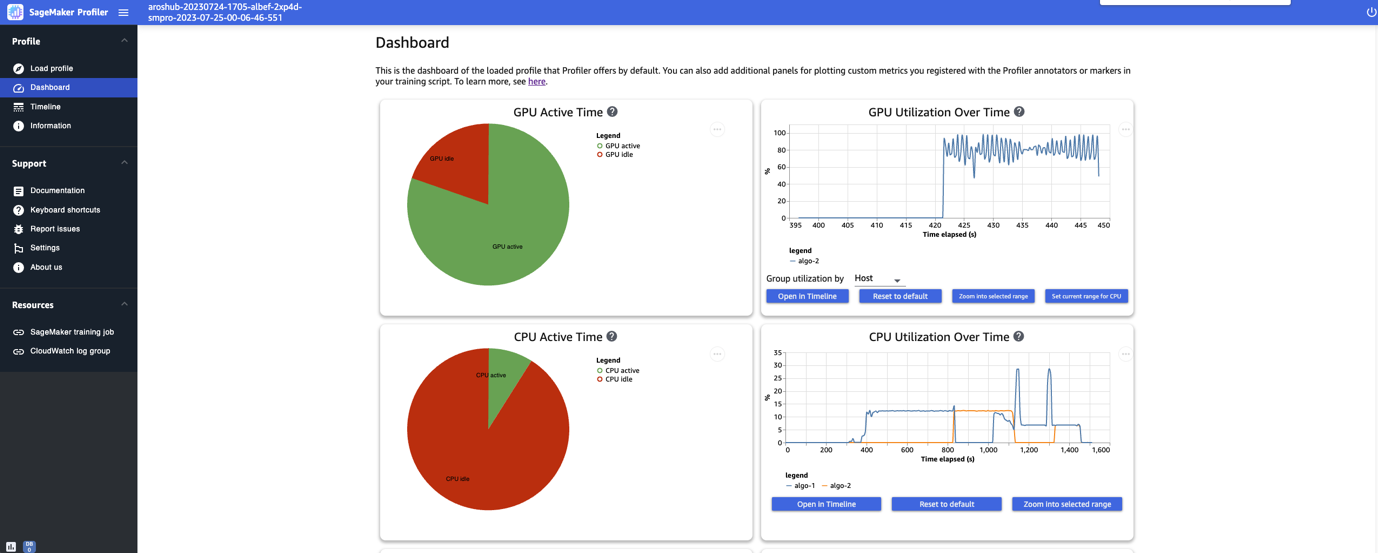
Puedes ver las gráficas de las métricas clave, como el tiempo activo de la GPU, la utilización de la GPU a lo largo del tiempo, el tiempo activo de la CPU y la utilización de la CPU a lo largo del tiempo. El gráfico circular del tiempo activo de la GPU muestra el porcentaje de tiempo activo de la GPU vs. el tiempo inactivo de la GPU, lo que nos permite verificar si las GPU están más activas que inactivas durante todo el trabajo de entrenamiento. El gráfico de la utilización de la GPU a lo largo del tiempo muestra la tasa promedio de utilización de la GPU a lo largo del tiempo por nodo, agregando todos los nodos en un solo gráfico. Puedes verificar si las GPU tienen una carga de trabajo desequilibrada, problemas de subutilización, cuellos de botella o problemas de inactividad durante ciertos intervalos de tiempo. Para obtener más detalles sobre la interpretación de estas métricas, consulta la documentación.
El panel de control te ofrece gráficas adicionales, como el tiempo invertido por todos los kernels de la GPU, el tiempo invertido por los 15 mejores kernels de la GPU, el número de lanzamientos de todos los kernels de la GPU y el número de lanzamientos de los 15 mejores kernels de la GPU, como se muestra en la siguiente captura de pantalla.
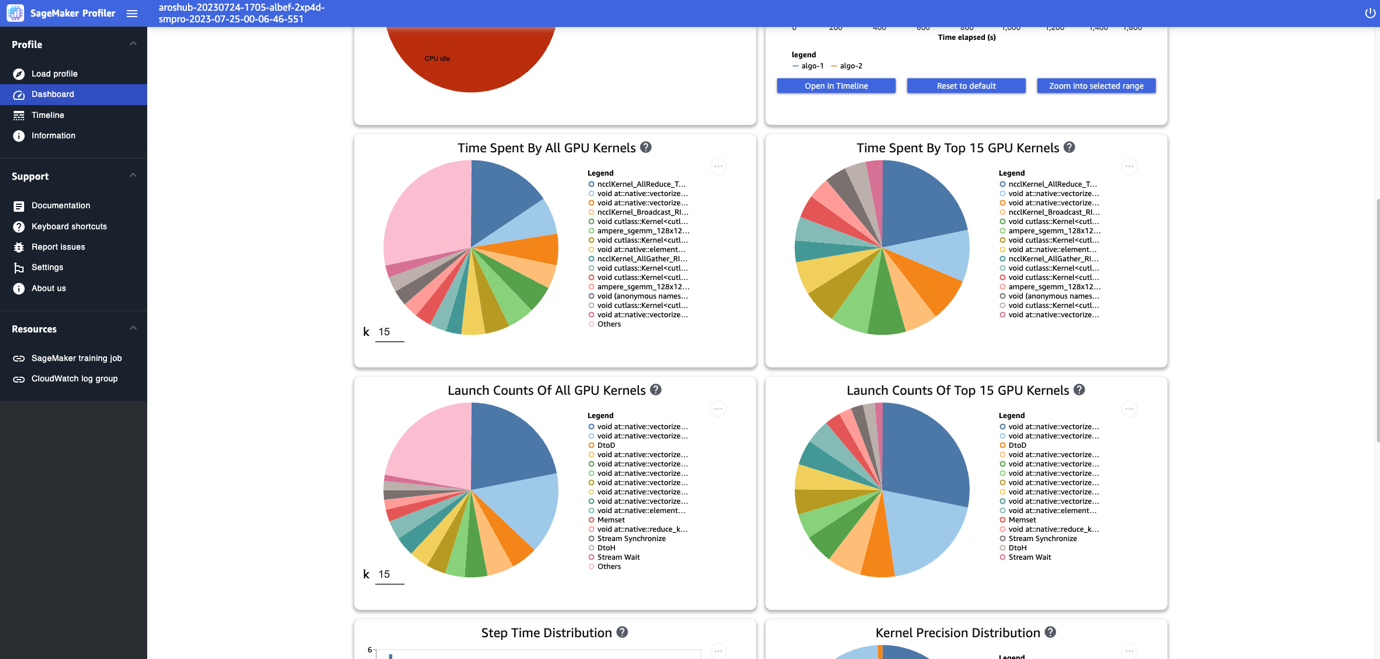
Por último, el panel de control te permite visualizar métricas adicionales, como la distribución de tiempo de paso, que es un histograma que muestra la distribución de las duraciones de paso en las GPU, y el gráfico circular de distribución de precisión de los kernels, que muestra el porcentaje de tiempo invertido en la ejecución de kernels en diferentes tipos de datos como FP32, FP16, INT32 e INT8.
También puedes obtener un gráfico circular sobre la distribución de actividad de la GPU que muestra el porcentaje de tiempo invertido en actividades de la GPU, como la ejecución de kernels, la memoria (memcpy y memset), y la sincronización (sync). Puedes visualizar el porcentaje de tiempo invertido en operaciones de memoria de la GPU a partir del gráfico circular de distribución de operaciones de memoria de la GPU.
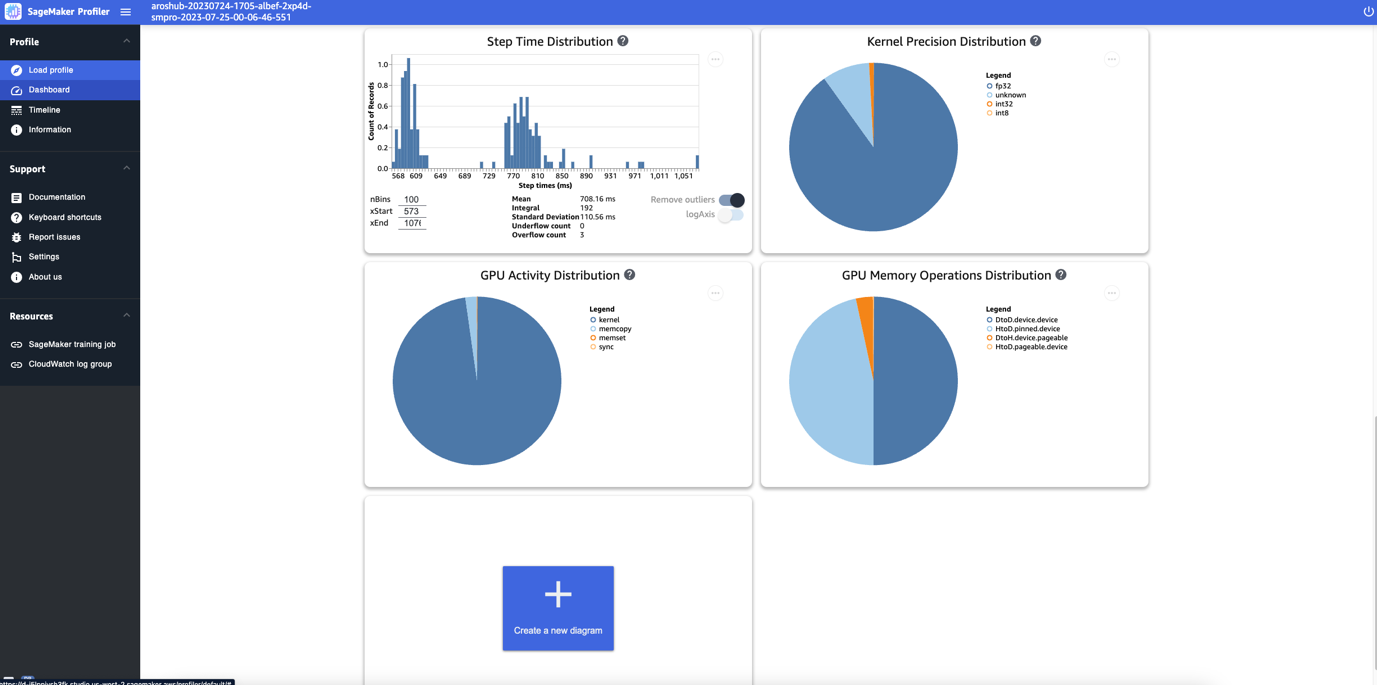
También puedes crear tus propios histogramas basados en una métrica personalizada que hayas anotado manualmente como se describió anteriormente en este artículo. Al agregar una anotación personalizada a un nuevo histograma, selecciona o ingresa el nombre de la anotación que agregaste en el script de entrenamiento.
Interfaz de línea de tiempo
La interfaz de usuario de SageMaker Profiler también incluye una interfaz de línea de tiempo, que te proporciona una vista detallada de los recursos informáticos a nivel de operaciones y kernels programados en las CPU y ejecutados en las GPU. La línea de tiempo está organizada en una estructura de árbol, brindándote información desde el nivel del host hasta el nivel del dispositivo, como se muestra en la siguiente captura de pantalla.
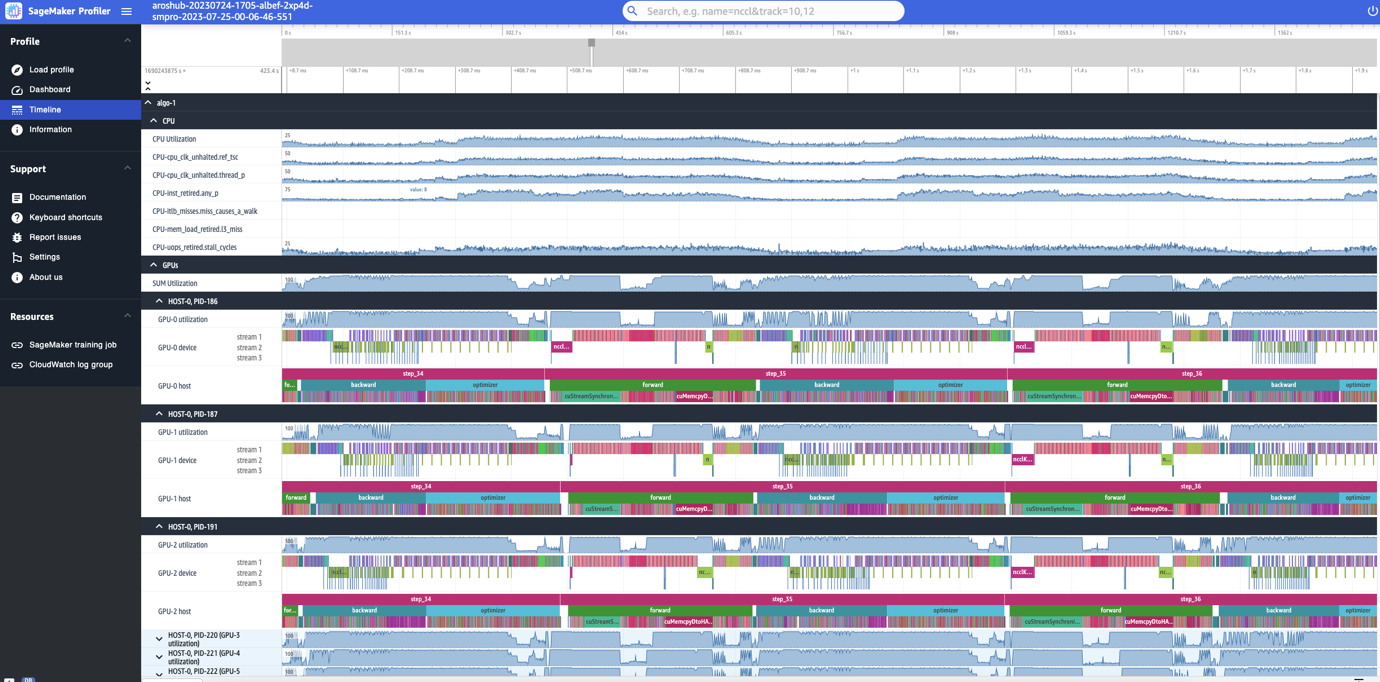
Para cada CPU, puedes realizar un seguimiento de los contadores de rendimiento de la CPU, como clk_unhalted_ref.tsc y itlb_misses.miss_causes_a_walk. Para cada GPU en la instancia p4d.24xlarge de 2x, puedes ver una línea de tiempo del host y una línea de tiempo del dispositivo. Los lanzamientos de kernels están en la línea de tiempo del host y las ejecuciones de kernels están en la línea de tiempo del dispositivo.
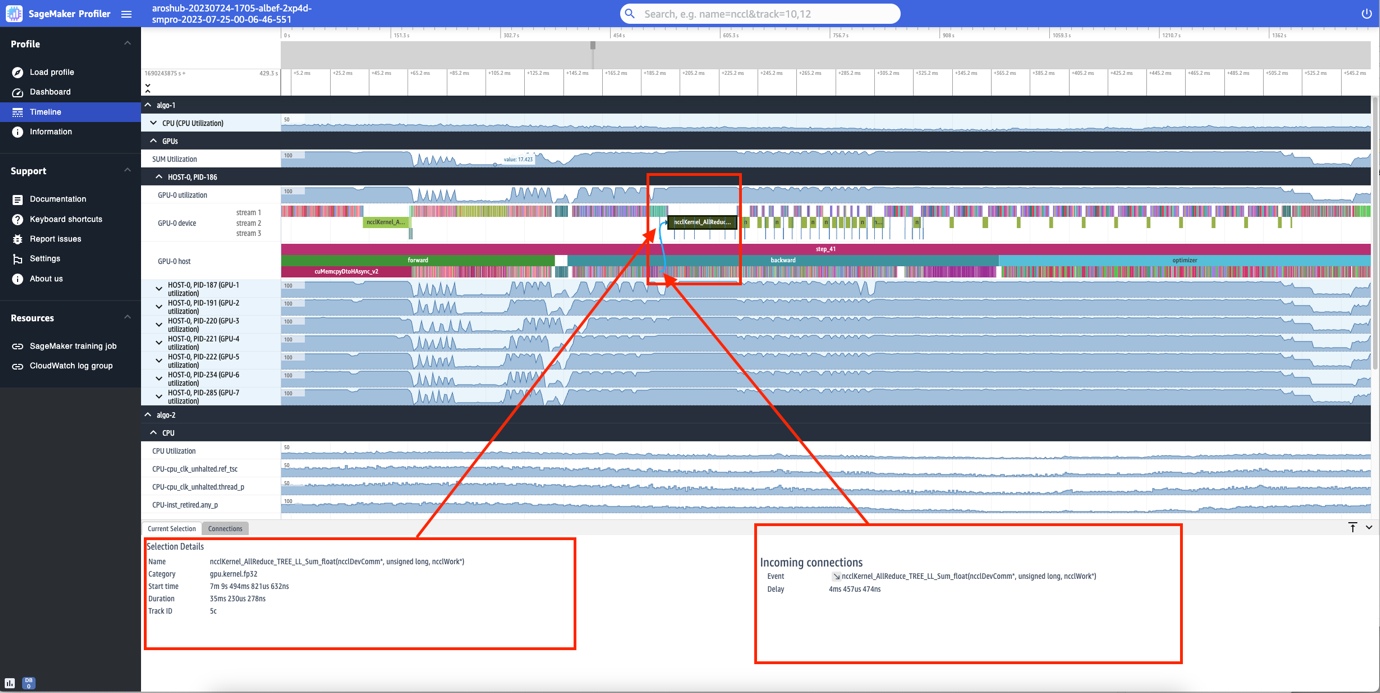
También puedes hacer zoom en los pasos individuales. En la siguiente captura de pantalla, hemos ampliado el paso_41. La franja de tiempo seleccionada en la siguiente captura de pantalla es la operación AllReduce, un paso de comunicación y sincronización esencial en el entrenamiento distribuido, ejecutado en la GPU-0. En la captura de pantalla, ten en cuenta que el lanzamiento del kernel en el host de GPU-0 se conecta a la ejecución del kernel en el flujo del dispositivo de GPU-0 1, indicado con la flecha en cian.
Disponibilidad y consideraciones
SageMaker Profiler está disponible en PyTorch (versión 2.0.0 y 1.13.1) y TensorFlow (versión 2.12.0 y 2.11.1). La siguiente tabla proporciona los enlaces a los AWS Deep Learning Containers compatibles con SageMaker.
| Framework | Versión | URI de imagen de AWS DLC |
| PyTorch | 2.0.0 | 763104351884.dkr.ecr.<región>.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| PyTorch | 1.13.1 | 763104351884.dkr.ecr.<región>.amazonaws.com/pytorch-training:1.13.1-gpu-py39-cu117-ubuntu20.04-sagemaker |
| TensorFlow | 2.12.0 | 763104351884.dkr.ecr.<región>.amazonaws.com/tensorflow-training:2.12.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| TensorFlow | 2.11.1 | 763104351884.dkr.ecr.<región>.amazonaws.com/tensorflow-training:2.11.1-gpu-py39-cu112-ubuntu20.04-sagemaker |
SageMaker Profiler está actualmente disponible en las siguientes regiones: US East (Ohio, N. Virginia), US West (Oregon) y Europa (Frankfurt, Irlanda).
SageMaker Profiler está disponible en los tipos de instancia de entrenamiento ml.p4d.24xlarge, ml.p3dn.24xlarge y ml.g4dn.12xlarge.
Para obtener la lista completa de frameworks y versiones compatibles, consulta la documentación.
SageMaker Profiler genera cargos después de la capa gratuita de SageMaker o el período de prueba gratuito de la función. Para obtener más información, consulta Precios de Amazon SageMaker.
Rendimiento de SageMaker Profiler
Comparamos la sobrecarga de SageMaker Profiler con varios perfiles de código abierto. La línea base utilizada para la comparación se obtuvo ejecutando el trabajo de entrenamiento sin un perfilador.
Nuestro resultado clave reveló que SageMaker Profiler generalmente resultó en una duración de entrenamiento facturable más corta porque tenía menos tiempo de sobrecarga en las ejecuciones de entrenamiento de principio a fin. También generó menos datos de perfilado (hasta 10 veces menos) en comparación con las alternativas de código abierto. Los artefactos de perfilado más pequeños generados por SageMaker Profiler requieren menos almacenamiento, lo que también ahorra costos.
Conclusión
SageMaker Profiler te permite obtener información detallada sobre la utilización de los recursos informáticos al entrenar tus modelos de aprendizaje profundo. Esto te permitirá resolver puntos calientes de rendimiento y cuellos de botella para garantizar una utilización eficiente de los recursos que finalmente reducirá los costos de entrenamiento y acortará la duración general del entrenamiento.
Para comenzar con SageMaker Profiler, consulte la documentación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- RAG vs Finetuning ¿Cuál es la mejor herramienta para impulsar tu solicitud de LLM?
- ¿Podemos evitar que los LLMs alucinen?
- Explorando el paisaje de la inteligencia artificial generativa
- Agentes de IA Tendencia del Mes en IA Generativa
- Descubriendo el Teorema de Flujo Máximo Corte Mínimo Un Enfoque Integral y Formal
- IA generativa para conocimientos biomédicos
- GPT-3 ¿Aprendizaje de pocos ejemplos para modelos de lenguaje?






