Análisis en base de datos aprovechando las funciones analíticas de SQL
'Analysis in databases using SQL's analytical functions'
Aprende sobre diversas funciones analíticas de SQL como RANK(), NTILE(), CUME_DIST() y más, para aprovechar al máximo tus habilidades de análisis de datos.

Todos sabemos la importancia del análisis de datos en el mundo actual impulsado por datos y cómo nos ofrece información valiosa a partir de los datos disponibles. Pero a veces, el análisis de datos se vuelve muy desafiante y consume mucho tiempo para el analista de datos. La razón principal por la cual se ha vuelto agitado en la actualidad es el volumen explosivo de datos generados y la necesidad de herramientas externas para realizar técnicas de análisis complejas sobre ellos.
Pero, ¿qué pasa si analizamos los datos dentro de la base de datos misma y con consultas significativamente simplificadas? Esto se puede lograr utilizando las funciones analíticas de SQL. En este artículo se discutirán varias funciones analíticas de SQL que se pueden ejecutar dentro del servidor SQL y obtener resultados valiosos.
- Deja de usar PowerPoint para tus presentaciones de ML y prueba esto en su lugar
- ¿Por qué el aprendizaje profundo siempre se realiza en datos de matriz? Nueva investigación de IA introduce ‘Spatial Functa’, donde desde los datos hasta la Functa se tratan como uno solo.
- La guía de campo de datos sintéticos
Estas funciones calculan el valor agregado en función de un grupo de filas y van más allá de las operaciones básicas de fila. Nos proporcionan herramientas para clasificar, realizar cálculos de series temporales, análisis de ventanas y análisis de tendencias. Entonces, sin perder más tiempo, comencemos a discutir estas funciones una por una con algunos detalles y ejemplos prácticos. El requisito previo de este tutorial es el conocimiento práctico básico de consultas SQL.
Creando una tabla de demostración
Crearemos una tabla de demostración y aplicaremos todas las funciones analíticas a esta tabla para que puedas seguir fácilmente el tutorial.
Nota: Algunas de las funciones discutidas en este tutorial no están presentes en SQLite. Por lo tanto, es preferible utilizar MySQL o PostgreSQL Server.
Esta tabla contiene los datos de varios estudiantes universitarios, con cuatro columnas: ID del estudiante, Nombre del estudiante, Asignatura y Calificaciones finales sobre 100.
Creando una tabla de estudiantes que contiene 4 columnas:
CREATE TABLE students
(
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
subject VARCHAR(30),
final_marks INT
); Ahora, insertaremos algunos datos ficticios en esa tabla.
INSERT INTO Students (id, name, subject, final_marks)
VALUES (1, 'John', 'Maths', 89),
(2, 'Kelvin', 'Physics', 67),
(3, 'Peter', 'Chemistry', 78),
(4, 'Saina', 'Maths', 44),
(5, 'Pollard', 'Chemistry', 91),
(6, 'Steve', 'Biology', 88),
(7, 'Jos', 'Physics', 89),
(8, 'Afridi', 'Maths', 97),
(9, 'Ricky', 'Biology', 78),
(10, 'David', 'Chemistry', 93),
(11, 'Jofra', 'Chemistry', 93),
(12, 'James', 'Biology', 65),
(13, 'Adam', 'Maths', 90),
(14, 'Warner', 'Biology', 45),
(15, 'Virat', 'Physics', 56);Ahora visualizaremos nuestra tabla.
SELECT *
FROM studentsSalida:
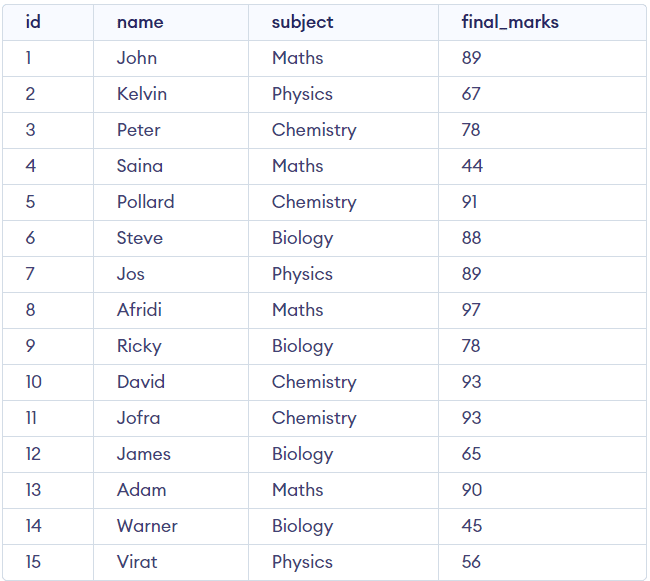
Estamos listos para ejecutar las funciones analíticas.
RANK() y DENSE_RANK()
La función RANK() asignará un rango particular a cada fila dentro de una partición en función del orden especificado. Si las filas tienen valores idénticos dentro de la misma partición, se les asigna el mismo rango.
Veámoslo más claramente con el siguiente ejemplo.
SELECT *,
Rank()
OVER (
ORDER BY final_marks DESC) AS 'ranks'
FROM students;Salida:
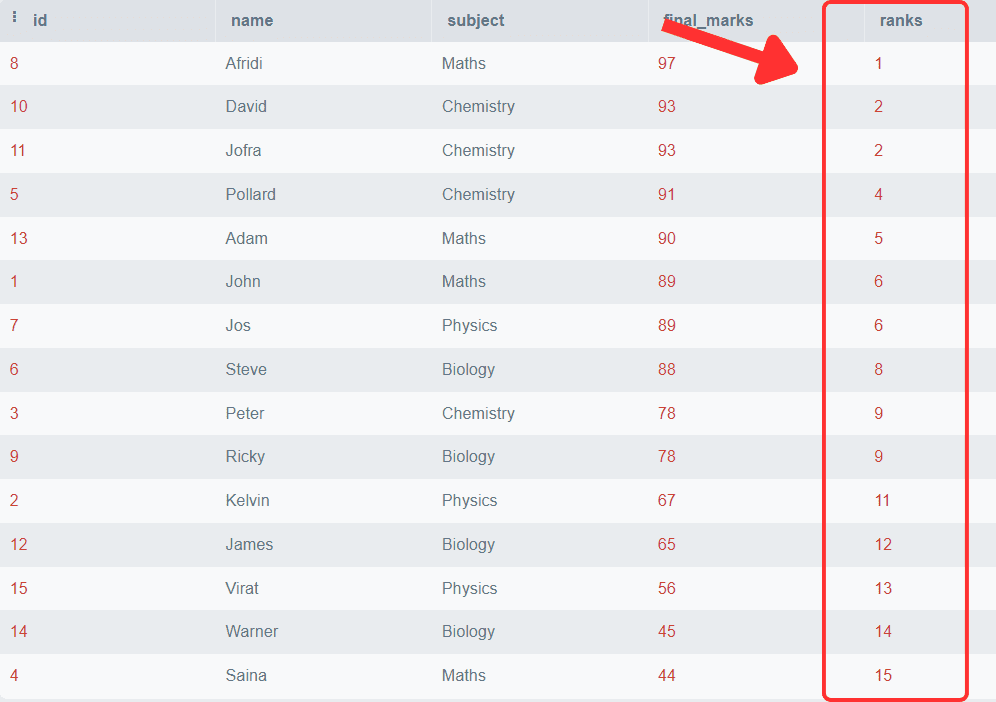
Puedes observar que las calificaciones finales se organizan en orden descendente y se asocia un rango particular con cada fila. También puedes observar que los estudiantes con las mismas calificaciones obtienen el mismo rango y el siguiente rango después de la fila duplicada se salta.
También podemos encontrar los mejores estudiantes de cada asignatura, es decir, podemos particionar el rango en función de las asignaturas. Veamos cómo hacerlo.
SELECT *,
Rank()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;Salida:
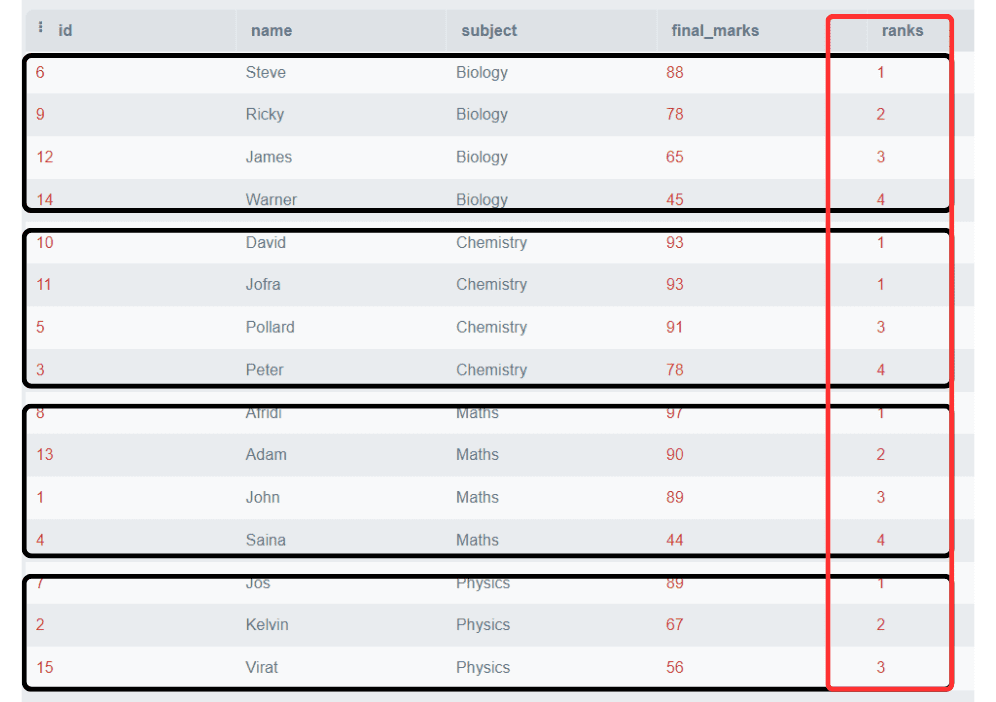
En este ejemplo, hemos particionado el ranking basado en las materias y las clasificaciones se asignan por separado para cada materia.
Nota: Observa que dos estudiantes obtuvieron las mismas notas en la materia de Química, clasificados como 1, y el rango para la siguiente fila comienza directamente desde 3. Se salta el rango 2.
Esta es la característica de la función RANK() que no siempre es necesario producir rangos consecutivos. El siguiente rango será la suma del rango anterior y los números duplicados.
Para superar este problema, se introduce la función DENSE_RANK() que funciona de manera similar a la función RANK(), pero siempre asigna rangos consecutivos. Sigue el siguiente ejemplo:
SELECT *,
DENSE_RANK()
OVER (
PARTITION BY materia
ORDER BY notas_finales DESC) AS 'rango'
FROM estudiantes;Salida:
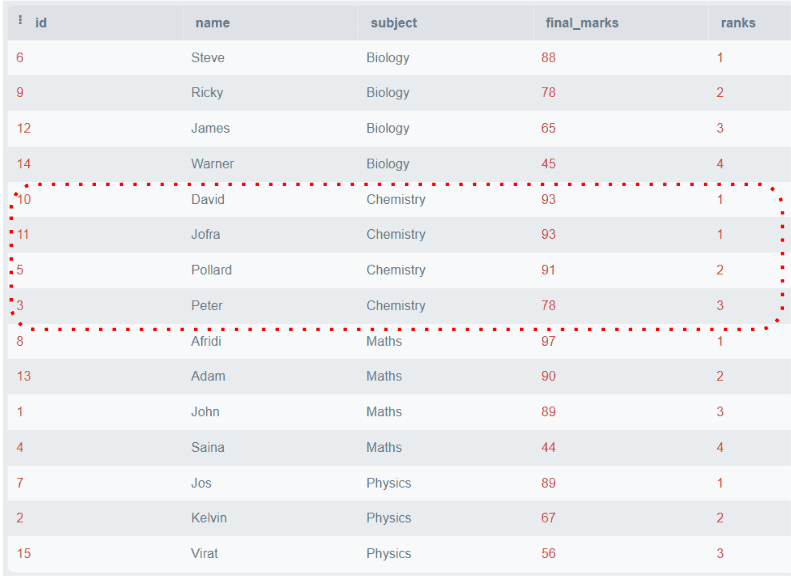 La figura anterior muestra que todos los rangos son consecutivos, incluso si hay notas duplicadas en la misma partición.
La figura anterior muestra que todos los rangos son consecutivos, incluso si hay notas duplicadas en la misma partición.
NTILE()
La función NTILE() se utiliza para dividir las filas en un número especificado (N) de grupos de tamaño aproximadamente igual. A cada fila se le asigna un número de grupo que va desde 1 hasta N (número total de grupos).
También podemos aplicar la función NTILE() en una partición u orden específico, que se especifican en las cláusulas PARTITION BY y ORDER BY.
Supongamos que N no es perfectamente divisible por el número de filas. Entonces, la función creará grupos de diferentes tamaños con una diferencia de uno.
Sintaxis:
NTILE(n) OVER (PARTITION BY c1, c2 ORDER BY c3)La función NTILE() toma un parámetro requerido N, es decir, el número de grupos, y algunos parámetros opcionales como las cláusulas PARTITION BY y ORDER BY. NTILE() dividirá las filas en función del orden especificado por estas cláusulas.
Veamos un ejemplo considerando nuestra tabla “Estudiantes”. Supongamos que queremos dividir a los estudiantes en grupos según sus notas finales. Crearemos tres grupos. El Grupo 1 contendrá a los estudiantes con las notas más altas. El Grupo 2 tendrá a todos los estudiantes mediocres y el Grupo 3 incluirá a los estudiantes con notas bajas.
SELECT *,
NTILE(3)
OVER (
ORDER BY notas_finales DESC) AS grupo
FROM estudiantes; Salida:
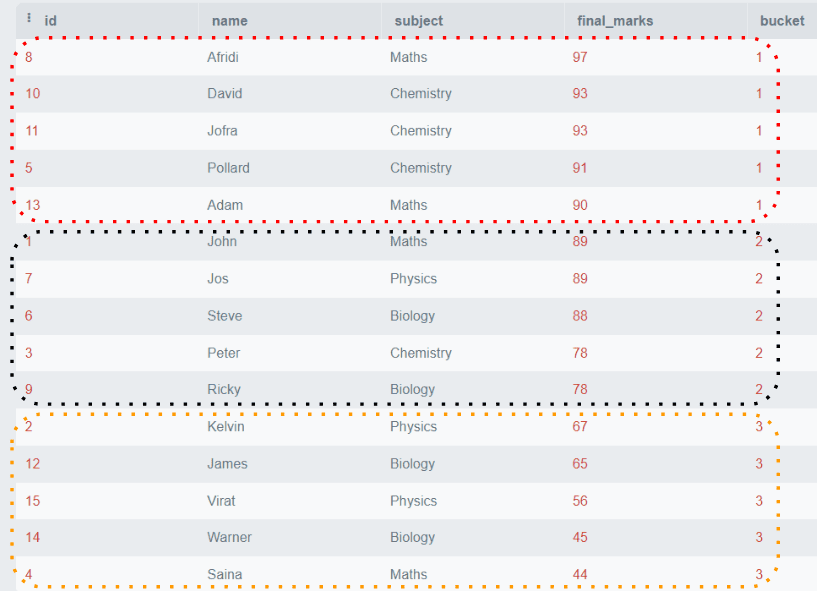
El ejemplo anterior muestra que todas las filas están ordenadas por notas_finales y se dividen en tres grupos que contienen cinco filas por grupo.
NTILE() es útil cuando queremos dividir datos en grupos iguales según algunos criterios específicos. Se puede utilizar en aplicaciones como la segmentación de clientes basada en los artículos comprados o la categorización del rendimiento de los empleados, etc.
CUME_DIST()
La función CUME_DIST() encuentra la distribución acumulativa de un valor particular en cada fila dentro de una partición u orden especificado. La Función de Distribución Acumulativa (CDF) denota la probabilidad de que la variable aleatoria X sea menor o igual a x. Se denota por F(x), y su fórmula matemática se representa como,
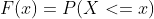
P(x) es la Función de Distribución de Probabilidad.
En palabras sencillas, la función CUME_DIST() devuelve el porcentaje de filas cuyo valor es menor o igual al valor actual de la fila. Ayudará a analizar la distribución de los datos y también la posición relativa de un valor con respecto al conjunto.
SELECT *,
CUME_DIST()
OVER (
ORDER BY notas_finales) AS dist_cum
FROM estudiantes; Salida:
El código anterior ordenará todas las filas basado en final_marks y encontrará la Distribución Acumulativa, pero si deseas particionar los datos basados en las asignaturas, puedes usar la cláusula PARTITION BY. A continuación se muestra un ejemplo de cómo hacerlo.
SELECT *,
CUME_DIST()
OVER (
PARTITION BY subject
ORDER BY final_marks) AS cum_dis
FROM students; Resultado:
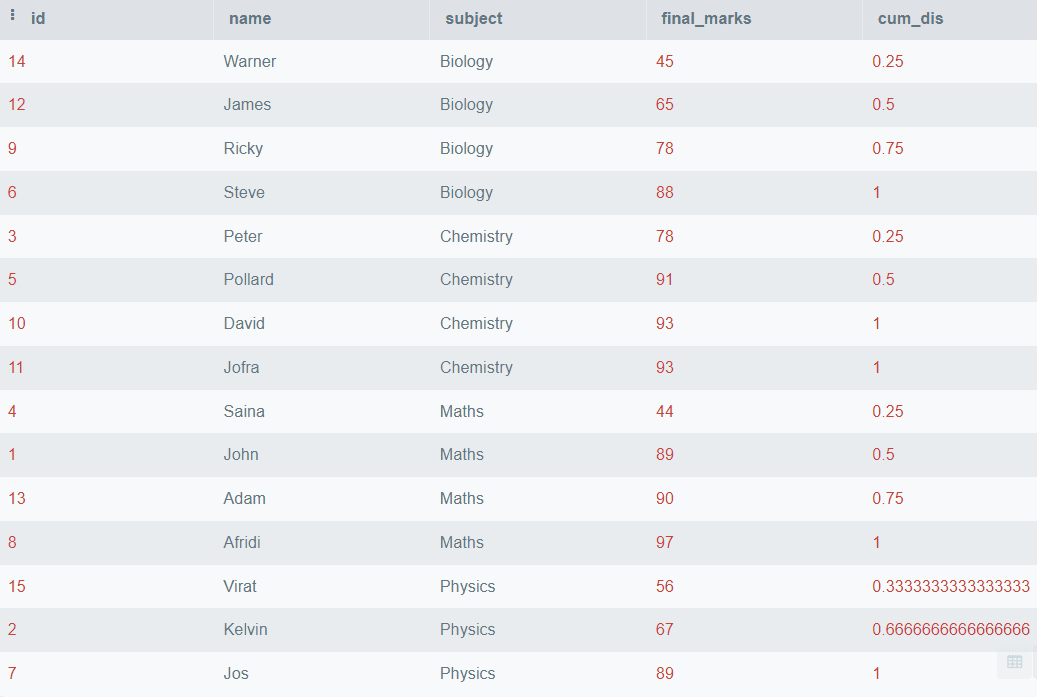
En el resultado anterior, hemos visto la distribución acumulativa de final_marks particionada por el nombre de la asignatura.
STDDEV() y VARIANCE()
La función VARIANCE() se utiliza para encontrar la varianza de un valor dado dentro de la partición. En estadística, la varianza representa qué tan lejos está un número de su valor medio, o representa el grado de dispersión entre los números. Se representa con ?^2.
La función STDDEV() se utiliza para encontrar la desviación estándar de un valor dado dentro de la partición. La desviación estándar también mide la variación en los datos y es igual a la raíz cuadrada de la varianza. Se representa con ?.
Estos parámetros nos pueden ayudar a encontrar la dispersión y variabilidad en los datos. Veamos cómo podemos hacerlo en la práctica.
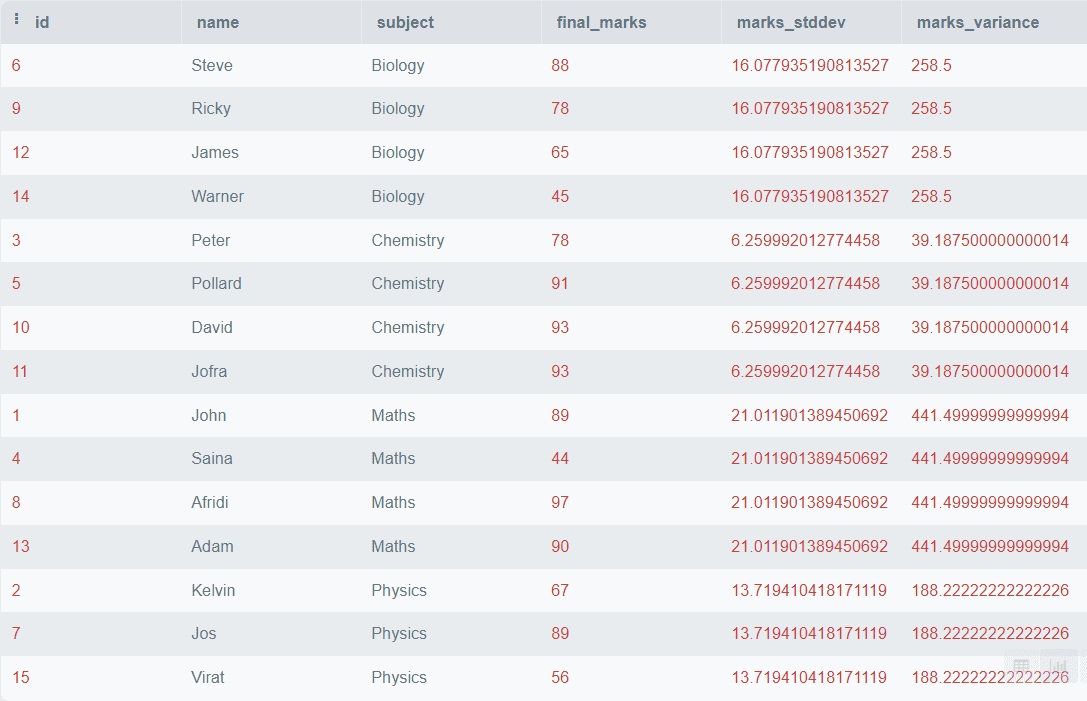
SELECT *,
STDDEV(final_marks)
OVER (
PARTITION BY subject) AS marks_stddev,
VARIANCE(final_marks)
OVER (
PARTITION BY subject) AS marks_variance
FROM students; Resultado: 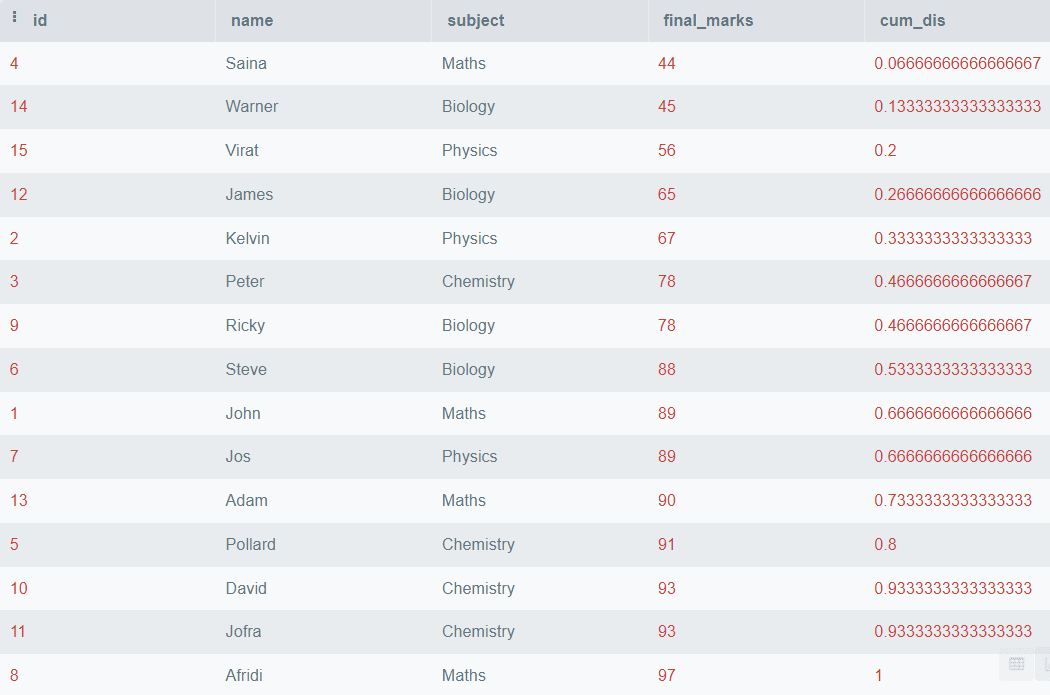 El resultado anterior muestra la Desviación Estándar y la Varianza de las notas finales para cada asignatura.
El resultado anterior muestra la Desviación Estándar y la Varianza de las notas finales para cada asignatura.
FIRST_VALUE() y LAST_VALUE()
La función FIRST_VALUE() mostrará el primer valor de una partición basado en un ordenamiento específico. De manera similar, la función LAST_VALUE() mostrará el último valor de esa partición. Estas funciones se pueden utilizar cuando queremos identificar la primera y última aparición de una partición especificada.
Sintaxis:
SELECT *,
FIRST_VALUE(col1)
OVER (
PARTITION BY col2, col3
ORDER BY col4) AS first_value
FROM table_nameConclusión
Las Funciones Analíticas de SQL nos proporcionan las funciones para realizar análisis de datos dentro del servidor SQL. Utilizando estas funciones, podemos desbloquear el verdadero potencial de los datos y obtener información valiosa de ellos para aumentar nuestro negocio. Además de las funciones discutidas anteriormente, existen muchas más funciones excelentes que pueden resolver tus problemas complejos muy rápidamente. Puedes obtener más información sobre estas Funciones Analíticas en este artículo de Microsoft. Aryan Garg es un estudiante de Ingeniería Eléctrica de B.Tech., actualmente en el último año de su licenciatura. Su interés se encuentra en el campo del Desarrollo Web y el Aprendizaje Automático. Ha perseguido este interés y está ansioso por trabajar más en estas direcciones.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Un nuevo estudio de investigación en IA presenta AttrPrompt un generador de datos de entrenamiento LLM para un nuevo paradigma en el aprendizaje de cero disparos.
- 4 Ideas Estadísticas Importantes que Deberías Comprender en un Mundo Impulsado por los Datos
- 5 Lecciones esenciales para los científicos de datos junior que aprendí en Spotify (Parte 2)
- Conquistar reintentos en Python utilizando Tenacity Un tutorial de principio a fin
- Cómo construir una plataforma de análisis semi-estructurado en tiempo real en Snowflake
- ¿Es la Ciencia de Datos una buena carrera?
- ¿Cómo cambiar de carrera de analista de datos a científico de datos?






