Análisis de acordes de jazz con Transformers
Análisis de acordes de jazz con Transformers' (Jazz chord analysis with Transformers)
Un enfoque basado en datos para el análisis de música basado en árboles

En este artículo, resumo parte de mi trabajo de investigación “Predicción de jerarquías de música con un decodificador neuronal basado en gráficos”, que presenta un sistema basado en datos capaz de analizar secuencias de acordes de jazz.
Esta investigación está motivada por mi frustración con los sistemas de análisis basados en gramática (que eran la única opción disponible para los datos de música):
- La fase de construcción de gramática requiere mucho conocimiento del dominio
- El analizador fallará en caso de algunas configuraciones no vistas o datos ruidosos
- Es difícil tener en cuenta múltiples dimensiones musicales en una sola regla gramatical
- No existe un marco de trabajo activo en Python bien respaldado para ayudar con el desarrollo
Mi enfoque (inspirado en trabajos similares en Procesamiento del Lenguaje Natural), en cambio, no se basa en ninguna gramática, produce resultados parciales para entradas ruidosas, maneja fácilmente múltiples dimensiones musicales y está implementado en PyTorch.
- Principales artículos de Visión por Computadora durante la semana del 24/7 al 31/7
- 10 Mejores Herramientas de Intercambio de Caras de IA (Agosto 2023)
- API de Pronóstico Un Ejemplo con Django y Google Trends
Si no estás familiarizado con el análisis y las gramáticas, o simplemente necesitas refrescar tus conocimientos, ahora daré un paso atrás.
¿Qué es “análisis”?
El término análisis se refiere a predecir/inferir un árbol (la estructura matemática) cuyas hojas son los elementos de las secuencias.
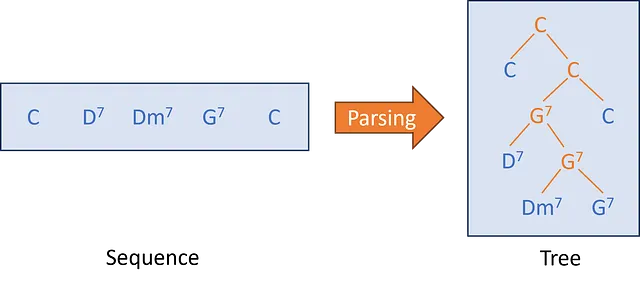
De acuerdo, pero ¿por qué necesitaríamos un árbol?
Comencemos con la siguiente secuencia de acordes de jazz (sección A de “Take the A Train”).

En la música de jazz, los acordes están conectados por un sistema complejo de relaciones perceptuales. Por ejemplo, el Dm7 es una preparación para el acorde dominante G7. Esto significa que el Dm7 es menos importante que el G7 y, por ejemplo, se puede omitir en una reharmonización diferente. De manera similar, el D7 es un dominante secundario (un dominante de un dominante) que también se refiere a G7.
Este tipo de relación armónica se puede expresar con un árbol y puede ser útil para el análisis musical o para realizar tareas como la reharmonización. Sin embargo, dado que los acordes en las piezas musicales están disponibles principalmente como una secuencia, queremos un sistema que sea capaz de construir automáticamente esa estructura de árbol.
Árboles de constituyentes vs. Árboles de dependencias
Antes de continuar, necesitamos diferenciar entre dos tipos de árboles.
Los musicólogos tienden a usar lo que se llama árboles de constituyentes, que se pueden ver en la imagen a continuación. Los árboles de constituyentes contienen hojas (acordes en azul, elementos de la secuencia de entrada) y nodos internos (acordes en naranja, reducciones de las hojas de los hijos).
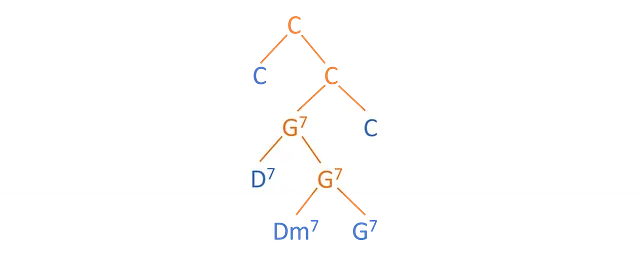
En este trabajo, en cambio, consideramos otro tipo de árbol, llamado árbol de dependencias. Este tipo de árbol no tiene nodos internos, sino solo arcos dirigidos que conectan los elementos de la secuencia.
Podemos obtener el árbol de dependencias a partir del árbol de constituyentes, con algunos algoritmos que se discutirán más adelante.
Conjunto de datos
Dado que este es un enfoque basado en datos, necesitamos un conjunto de datos de secuencias de acordes (los datos de entrada) asociado con un conjunto de árboles (la verdad fundamental) para entrenamiento y pruebas. Utilizamos el Jazz Treebank¹, que está disponible públicamente en este repositorio de GitHub (se puede usar de forma gratuita para aplicaciones no comerciales y obtuve el permiso del autor para usarlo en este artículo). En particular, proporcionan un archivo JSON con todos los acordes y anotaciones.
Modelamos cada acorde en la entrada a nuestro sistema con tres características:
- La raíz, un entero en [0..11], donde C -> 0, C# -> 1, etc…
- La forma básica, un entero en [0..5], que selecciona entre mayor, menor, aumentado, semidisminuido, disminuido y suspendido (sus).
- La extensión, un entero en [0,1,2] que selecciona entre 6, menor 7 o mayor 7.
Para obtener las características del acorde a partir de una etiqueta de acorde (una cadena), podemos usar una expresión regular de la siguiente manera (ten en cuenta que este código funciona para este conjunto de datos, ya que el formato puede variar en otros conjuntos de datos de acordes).
def parse_chord_label(chord_label): # Definir un patrón de regex para los símbolos de acordes pattern = r"([A-G][#b]?)(m|\+|%|o|sus)?(6|7|\^7)?" # Coincidir el patrón con el acorde de entrada match = re.match(pattern, chord_label) if match: # Extraer la raíz, la forma básica del acorde y la extensión del objeto coincidente root = match.group(1) form = match.group(2) or "M" ext = match.group(3) or "" return root, form, ext else: # Devolver None si la entrada no es un símbolo de acorde válido raise ValueError("Símbolo de acorde inválido: {}".format(chord_label))Finalmente, necesitamos producir el árbol de dependencias. El conjunto de datos JHT solo contiene árboles constituyentes, codificados como un diccionario anidado. Los importamos y los transformamos en árboles de dependencias con una función recursiva. El mecanismo de nuestra función se puede describir de la siguiente manera.
Comenzamos desde un árbol de constituyentes completamente formado y un árbol de dependencias sin ningún arco de dependencia, que consiste solo en los nodos etiquetados con elementos de secuencia. El algoritmo agrupa todos los nodos internos del árbol con su hijo principal (que tienen la misma etiqueta) y utiliza todas las relaciones secundarias de hijos que se originan en cada grupo para crear arcos de dependencia entre la etiqueta del grupo y la etiqueta del hijo secundario.
def parse_jht_to_dep_tree(jht_dict): """Analiza el diccionario de árboles de armonía de jazz de Python en una lista de dependencias y una lista de acordes en las hojas. """ all_leaves = [] def _iterative_parse_jht(dict_elem): """Función iterativa para analizar el diccionario de árboles de armonía de jazz de Python en una lista de dependencias.""" children = dict_elem["children"] if children == []: # Condición de finalización de recursión out = ( [], {"index": len(all_leaves), "label": dict_elem["label"]}, ) # agregar la etiqueta del nodo actual a la lista global de hojas all_leaves.append(dict_elem["label"]) return out else: # Llamada recursiva assert len(children) == 2 current_label = noast(dict_elem["label"]) out_list = [] # lista de dependencias iterative_result_left = _iterative_parse_jht(children[0]) iterative_result_right = _iterative_parse_jht(children[1]) # combinar las listas de dependencias calculadas más profundamente out_list.extend(iterative_result_left[0]) out_list.extend(iterative_result_right[0]) # verificar si la etiqueta corresponde a los hijos izquierdo o derecho y devolver el resultado correspondiente if iterative_result_right[1]["label"] == current_label: # si ambos hijos son iguales, se va por el arco izquierdo-derecho # agregar la dependencia para el nodo actual out_list.append((iterative_result_right[1]["index"], iterative_result_left[1]["index"])) return out_list, iterative_result_right[1] elif iterative_result_left[1]["label"] == current_label: # print("right-left arc on label", current_label) # agregar la dependencia para el nodo actual out_list.append((iterative_result_left[1]["index"], iterative_result_right[1]["index"])) return out_list, iterative_result_left[1] else: raise ValueError("Algo salió mal con la etiqueta", current_label) dep_arcs, root = _iterative_parse_jht(jht_dict) dep_arcs.append((-1,root["index"])) # agregar conexión a la raíz, con índice -1 # agregar bucle propio a la raíz dep_arcs.append((-1,-1)) # agregar conexión de bucle a la raíz, con índice -1 return dep_arcs, all_leavesModelo de Análisis de Dependencias
El mecanismo de funcionamiento de nuestro modelo de análisis es bastante simple: consideramos todos los posibles arcos y utilizamos un predictor de arcos (un clasificador binario simple) para predecir si este arco debe formar parte del árbol o no.
Sin embargo, es bastante difícil tomar esta decisión solo basándonos en los dos acordes que estamos tratando de conectar. Necesitamos algo de contexto. Construimos dicho contexto con un codificador transformador.
Para resumir, nuestro modelo de análisis actúa en dos pasos:
- la secuencia de entrada pasa a través de un codificador transformador para enriquecerla con información contextual;
- un clasificador binario evalúa el grafo de todos los posibles arcos de dependencia para filtrar los arcos no deseados.
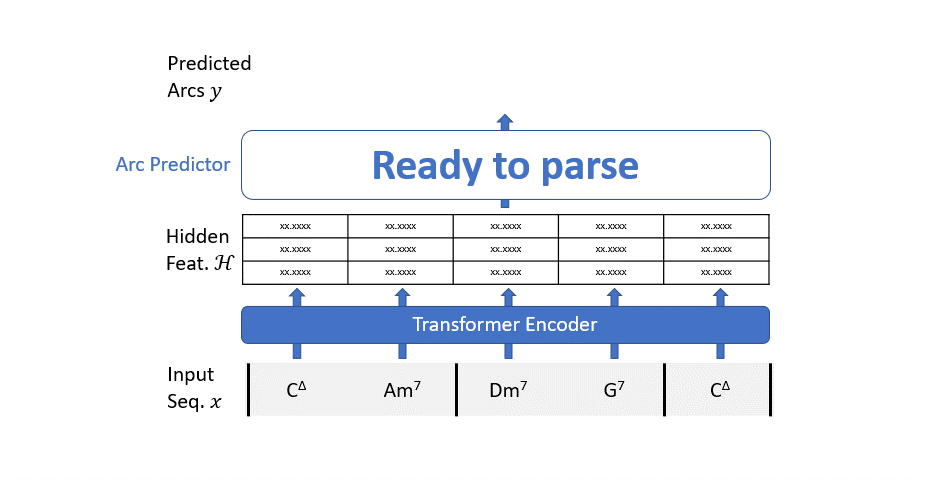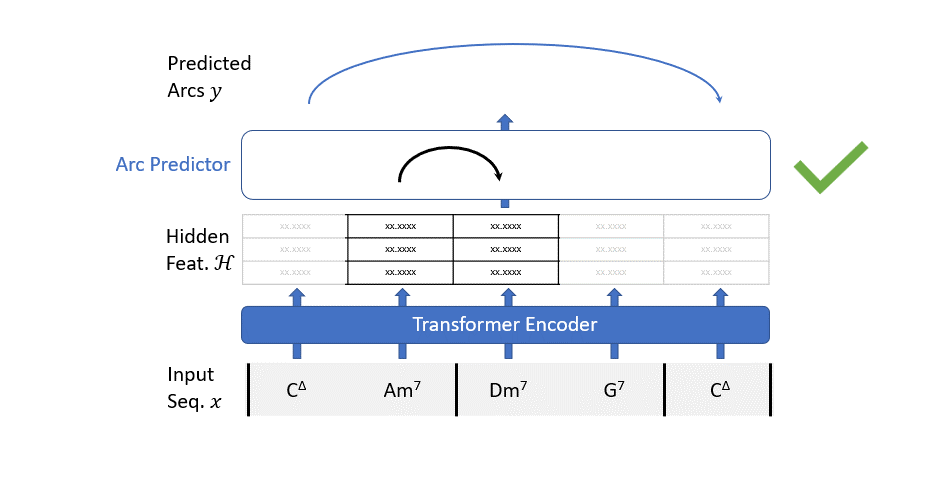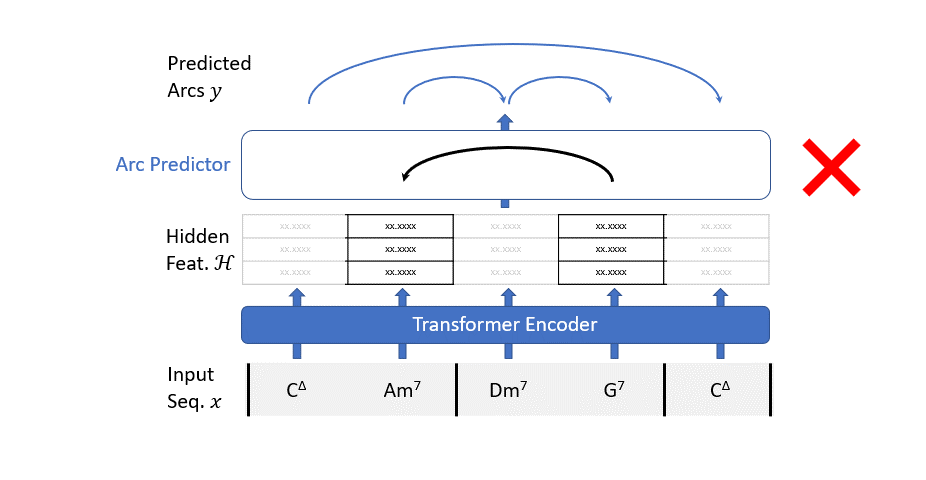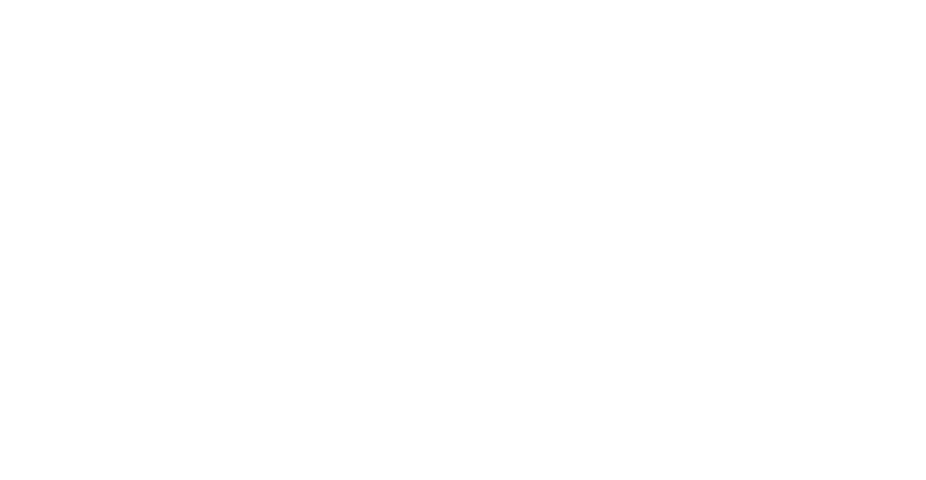
El Codificador Transformador sigue la arquitectura estándar. Usamos una capa de incrustación aprendible para mapear cada característica de entrada categórica a puntos en un espacio multidimensional continuo. Todas las incrustaciones se suman, por lo que depende de la red “decidir” la dimensión a usar para cada característica.
import torch.nn as nnclass TransformerEncoder(nn.Module): def __init__( self, input_dim, hidden_dim, encoder_depth, n_heads = 4, dropout=0, embedding_dim = 8, activation = "gelu", ): super().__init__() self.input_dim = input_dim self.positional_encoder = PositionalEncoding( d_model=input_dim, dropout=dropout, max_len=200 ) encoder_layer = nn.TransformerEncoderLayer(d_model=input_dim, dim_feedforward=hidden_dim, nhead=n_heads, dropout =dropout, activation=activation) encoder_norm = nn.LayerNorm(input_dim) self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=encoder_depth, norm=encoder_norm) self.embeddings = nn.ModuleDict({ "root": nn.Embedding(12, embedding_dim), "form": nn.Embedding(len(CHORD_FORM), embedding_dim), "ext": nn.Embedding(len(CHORD_EXTENSION), embedding_dim), "duration": nn.Embedding(len(JTB_DURATION), embedding_dim, "metrical": nn.Embedding(METRICAL_LEVELS, embedding_dim) }) def forward(self, sequence): root = sequence[:,0] form = sequence[:,1] ext = sequence[:,2] duration = sequence[:,3] metrical = sequence[:,4] # transform categorical features to embedding root = self.embeddings["root"](root.long()) form = self.embeddings["form"](form.long()) ext = self.embeddings["ext"](ext.long()) duration = self.embeddings["duration"](duration.long()) metrical = self.embeddings["metrical"](metrical.long()) # sum all embeddings z = root + form + ext + duration + metrical # add positional encoding z = self.positional_encoder(z) # reshape to (seq_len, batch = 1, input_dim) z = torch.unsqueeze(z,dim= 1) # run transformer encoder z = self.transformer_encoder(src=z, mask=src_mask) # remove batch dim z = torch.squeeze(z, dim=1) return z, ""class PositionalEncoding(nn.Module): def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 500): super().__init__() self.dropout = nn.Dropout(p=dropout) position = torch.arange(max_len).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model)) pe = torch.zeros(max_len, d_model) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) self.register_buffer('pe', pe) def forward(self, x: torch.Tensor) -> torch.Tensor: x = x + self.pe[:x.size(0)] return self.dropout(x)El predictor de arcos es simplemente una capa lineal que toma como entrada la concatenación de las características ocultas de los dos acordes. La etapa de clasificación para todos los arcos se realiza en paralelo gracias al poder de la multiplicación de matrices.
class ArcPredictor(nn.Module): def __init__(self, hidden_channels, activation=F.gelu, dropout=0.3): super().__init__() self.activation = activation self.root_linear = nn.Linear(1, hidden_channels) # lineal para producir características de la raíz self.lin1 = nn.Linear(2*hidden_channels, hidden_channels) self.lin2 = nn.Linear(hidden_channels, 1) self.dropout = nn.Dropout(dropout) self.norm = nn.LayerNorm(hidden_channels) def forward(self, z, pot_arcs): # añadir columna para el elemento raíz root_feat = self.root_linear(torch.ones((1,1), device=z.device)) z = torch.vstack((root_feat,z)) # proceder con el cálculo z = self.norm(z) # concatenar las incrustaciones de los dos nodos, forma (num_pot_arcs, 2*hidden_channels) z = torch.cat([z[pot_arcs[:, 0]], z[pot_arcs[:, 1]]], dim=-1) # pasar por una capa lineal, forma (num_pot_arcs, hidden_channels) z = self.lin1(z) # pasar por la activación, forma (num_pot_arcs, hidden_channels) z = self.activation(z) # normalizar z = self.norm(z) # dropout z = self.dropout(z) # pasar por otra capa lineal, forma (num_pot_arcs, 1) z = self.lin2(z) # devolver un vector de forma (num_pot_arcs,) return z.view(-1)Podemos poner el codificador de transformador y el predictor de arco en un solo módulo torch para simplificar su uso.
class ChordParser(nn.Module): def __init__(self, input_dim, hidden_dim, num_layers, dropout=0.2, embedding_dim = 8, use_embedding = True, n_heads = 4): super().__init__() self.activation = nn.functional.gelu # inicializar el codificador self.encoder = NotesEncoder(input_dim, hidden_dim, num_layers, dropout, embedding_dim, n_heads=n_heads) # inicializar el decodificador self.decoder = ArcDecoder(input_dim, dropout=dropout) def forward(self, note_features, pot_arcs, mask=None): z = self.encoder(note_features) return self.decoder(z, pot_arcs)Función de Pérdida
Como función de pérdida, utilizamos la suma de dos pérdidas:
- La pérdida de entropía cruzada binaria: la idea es ver nuestro problema como un problema de clasificación binaria, donde cada arco puede ser predicho o no.
- La pérdida de entropía cruzada: la idea es ver nuestro problema como un problema de clasificación multiclase, donde para cada cabeza en un arco de cabeza → dependiente, necesitamos predecir cuál es el dependiente correcto entre todos los demás acordes
loss_bce = torch.nn.BCEWithLogitsLoss()loss_ce = torch.nn.CrossEntropyLoss(ignore_index=-1)total_loss = loss_bce + loss_cePostprocesamiento
Hay un problema que todavía tenemos que resolver. El hecho de que los arcos predichos deben formar una estructura de árbol no se cumple en ningún momento durante nuestro entrenamiento. Por lo tanto, podríamos tener una configuración inválida como un bucle de arco. Afortunadamente, hay un algoritmo que podemos usar para garantizar que esto no suceda: el algoritmo de Eisner.²
En lugar de asumir simplemente que existe un arco si su probabilidad predicha es mayor que 0.5, guardamos todas las predicciones en una matriz cuadrada (la matriz de adyacencia) de tamaño (número de acordes, número de acordes) y ejecutamos el algoritmo de Eisner en ella.
# Adaptado de https://github.com/HMJW/biaffine-parserdef eisner(scores, return_probs = False): """Analizar utilizando el algoritmo de Eisner. La matriz sigue la siguiente convención: scores[i][j] = p(i=cabeza, j=dep) = p(i --> j) """ filas, columnas = scores.shape assert filas == columnas, 'la matriz de scores debe ser cuadrada' num_palabras = filas - 1 # Número de palabras (excluyendo la raíz). # Inicializar la tabla CKY. completa = np.zeros([num_palabras+1, num_palabras+1, 2]) # s, t, dirección (derecha=1). incompleta = np.zeros([num_palabras+1, num_palabras+1, 2]) # s, t, dirección (derecha=1). backtrack_completa = -np.ones([num_palabras+1, num_palabras+1, 2], dtype=int) # s, t, dirección (derecha=1). backtrack_incompleta = -np.ones([num_palabras+1, num_palabras+1, 2], dtype=int) # s, t, dirección (derecha=1). incompleta[0, :, 0] -= np.inf # Bucle desde los elementos más pequeños a los más grandes. for k in range(1, num_palabras+1): for s in range(num_palabras-k+1): t = s + k # Primero, crear elementos incompletos. # árbol izquierdo valores_incompletos0 = completa[s, s:t, 1] + completa[(s+1):(t+1), t, 0] + scores[t, s] incompleta[s, t, 0] = np.max(valores_incompletos0) backtrack_incompleta[s, t, 0] = s + np.argmax(valores_incompletos0) # árbol derecho valores_incompletos1 = completa[s, s:t, 1] + completa[(s+1):(t+1), t, 0] + scores[s, t] incompleta[s, t, 1] = np.max(valores_incompletos1) backtrack_incompleta[s, t, 1] = s + np.argmax(valores_incompletos1) # Segundo, crear elementos completos. # árbol izquierdo valores_completos0 = completa[s, s:t, 0] + incompleta[s:t, t, 0] completa[s, t, 0] = np.max(valores_completos0) backtrack_completa[s, t, 0] = s + np.argmax(valores_completos0) # árbol derecho valores_completos1 = incompleta[s, (s+1):(t+1), 1] + completa[(s+1):(t+1), t, 1] completa[s, t, 1] = np.max(valores_completos1) backtrack_completa[s, t, 1] = s + 1 + np.argmax(valores_completos1) valor = completa[0][num_palabras][1] cabezas = -np.ones(num_palabras + 1, dtype=int) backtrack_eisner(backtrack_incompleta, backtrack_completa, 0, num_palabras, 1, 1, cabezas) valor_proj = 0.0 for m in range(1, num_palabras+1): h = cabezas[m] valor_proj += scores[h, m] if return_probs: return cabezas, valor_proj else: return cabezasdef backtrack_eisner(backtrack_incompleta, backtrack_completa, s, t, direccion, completa, cabezas): """ Paso de retroceso en el algoritmo de Eisner. - backtrack_incompleta es una matriz numpy de tamaño (NW+1)-por-(NW+1) indexada por una posición de inicio, una posición de finalización y una bandera de dirección (0 significa izquierda, 1 significa derecha). Esta matriz contiene los arg-máximos de cada paso en el algoritmo de Eisner al construir fragmentos *incompletos*. - backtrack_completa es una matriz numpy de tamaño (NW+1)-por-(NW+1) indexada por una posición de inicio, una posición de finalización y una bandera de dirección (0 significa izquierda, 1 significa derecha). Esta matriz contiene los arg-máximos de cada paso en el algoritmo de Eisner al construir fragmentos *completos*. - s es el inicio actual del fragmento - t es el final actual del fragmento - direccion es 0 (unión izquierda) o 1 (unión derecha) - completa es 1 si el fragmento actual es completo y 0 en caso contrario - cabezas es una matriz numpy de tamaño (NW+1) de enteros que es un marcador de posición para almacenar la cabeza de cada palabra. """ if s == t: return if completa: r = backtrack_completa[s][t][direccion] if direccion == 0: backtrack_eisner(backtrack_incompleta, backtrack_completa, s, r, 0, 1, cabezas) backtrack_eisner(backtrack_incompleta, backtrack_completa, r, t, 0, 0, cabezas) return else: backtrack_eisner(backtrack_incompleta, backtrack_completa, s, r, 1, 0, cabezas) backtrack_eisner(backtrack_incompleta, backtrack_completa, r, t, 1, 1, cabezas) return else: r = backtrack_incompleta[s][t][direccion] if direccion == 0: cabezas[s] = t backtrack_eisner(backtrack_incompleta, backtrack_completa, s, r, 1, 1, cabezas) backtrack_eisner(backtrack_incompleta, backtrack_completa, r+1, t, 0, 1, cabezas) return else: cabezas[t] = s backtrack_eisner(backtrack_incompleta, backtrack_completa, s, r, 1, 1, cabezas) backtrack_eisner(backtrack_incompleta, backtrack_completa, r+1, t, 0, 1, cabezas) returnConclusiones
Presenté un sistema para el análisis de dependencia de secuencias de acordes que utiliza un transformador para construir representaciones ocultas de acordes contextuales y un clasificador para seleccionar si dos acordes deben estar vinculados por un arco.
La principal ventaja con respecto a otros sistemas competidores es que este enfoque no depende de ninguna gramática simbólica en particular, por lo tanto, puede considerar múltiples características musicales simultáneamente, utilizar información contextual secuencial y producir resultados parciales para entradas ruidosas.
Para mantener este artículo de un tamaño razonable, tanto la explicación como el código se centran en la parte más interesante del sistema. Puede encontrar una explicación más completa en este artículo científico y todo el código en este repositorio de GitHub.
(Todas las imágenes son del autor.)
Referencias
- D. Harasim, C. Finkensiep, P. Ericson, T. J. O’Donnell y M. Rohrmeier, “The jazz harmony treebank”, en Actas de la Conferencia de la Sociedad Internacional de Recuperación de Información Musical (ISMIR), 2020, pp. 207–215.
- J. M. Eisner, “Tres nuevos modelos probabilísticos para el análisis de dependencias: una exploración”, en Actas de la Conferencia Internacional de Lingüística Computacional (COLING), 1996.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ChatGPT y la ingeniería avanzada de instrucciones impulsando la evolución de la IA
- Detecta cualquier cosa que desees con UniDetector
- Investigadores de la Universidad Nacional de Singapur proponen Mind-Video una nueva herramienta de IA que utiliza datos de fMRI del cerebro para recrear imágenes de video
- Investigadores de UT Austin y UC Berkeley presentan Ambient Diffusion un marco de inteligencia artificial para entrenar/ajustar modelos de difusión dados solo datos corruptos como entrada.
- Conoce a QLORA Un enfoque de ajuste eficiente que reduce el uso de memoria lo suficiente como para ajustar un modelo de 65B parámetros en una sola GPU de 48GB, preservando al mismo tiempo el rendimiento completo de la tarea de ajuste fino de 16 bits.
- LLMs superan al aprendizaje por refuerzo Conozca SPRING un innovador marco de trabajo de sugerencias para LLMs diseñado para permitir la planificación y el razonamiento en cadena de pensamiento en contexto.
- Investigadores de UC Berkeley presentan Video Prediction Rewards (VIPER) un algoritmo que aprovecha los modelos de predicción de video preentrenados como señales de recompensa sin acción para el aprendizaje por refuerzo.





