Ajuste fino de Llama 2 70B utilizando PyTorch FSDP
Ajuste fino de Llama 2 70B con PyTorch FSDP
Introducción
En esta publicación del blog, veremos cómo afinar Llama 2 70B utilizando PyTorch FSDP y las mejores prácticas relacionadas. Aprovecharemos Hugging Face Transformers, Accelerate y TRL. También aprenderemos cómo utilizar Accelerate con SLURM.
El Paralelismo de Datos Totalmente Segmentado (FSDP, por sus siglas en inglés) es un paradigma en el que los estados del optimizador, los gradientes y los parámetros se dividen en segmentos entre dispositivos. Durante el pase hacia adelante, cada unidad de FSDP realiza una operación de recopilación total para obtener los pesos completos, se realiza la computación seguida de la eliminación de los segmentos de otros dispositivos. Después del pase hacia adelante, se calcula la pérdida seguida del pase hacia atrás. En el pase hacia atrás, cada unidad de FSDP realiza una operación de recopilación total para obtener los pesos completos, con computación realizada para obtener los gradientes locales. Estos gradientes locales se promedian y se dividen en segmentos entre los dispositivos mediante una operación de reducción y dispersión para que cada dispositivo pueda actualizar los parámetros de su segmento. Para obtener más información sobre qué es PyTorch FSDP, consulte esta publicación del blog: Acelere el entrenamiento de modelos grandes utilizando PyTorch Fully Sharded Data Parallel.

(Fuente: enlace)
- Aplicando Estadísticas Descriptivas e Inferenciales en Python
- Stability AI lanza el primer modelo japonés de visión y lenguaje
- Conoce a PyGraft una herramienta de IA basada en Python de código abierto que genera esquemas y grafos de conocimiento altamente personalizados y agnósticos al dominio.
Hardware utilizado
Número de nodos: 2. El mínimo requerido es 1. Número de GPU por nodo: 8. Tipo de GPU: A100. Memoria de la GPU: 80 GB. Conexión intra-nodo: NVLink. RAM por nodo: 1 TB. Núcleos de CPU por nodo: 96. Conexión inter-nodo: Adaptador de tejido elástico.
Desafíos en la afinación de LLaMa 70B
Enfrentamos tres desafíos principales al intentar afinar LLaMa 70B con FSDP:
-
FSDP envuelve el modelo después de cargar el modelo pre-entrenado. Si cada proceso/rango dentro de un nodo carga el modelo Llama-70B, requeriría 70*4*8 GB ~ 2 TB de RAM de la CPU, donde 4 es el número de bytes por parámetro y 8 es el número de GPU en cada nodo. Esto resultaría en que la RAM de la CPU se quede sin memoria, lo que lleva a la terminación de los procesos.
-
Guardar puntos de control intermedios completos utilizando
FULL_STATE_DICTcon la desactivación de la CPU en el rango 0 lleva mucho tiempo y a menudo resulta en errores de tiempo de espera de NCCL debido a una suspensión indefinida durante la difusión. Sin embargo, al final del entrenamiento, queremos el diccionario de estado del modelo completo en lugar del diccionario de estado segmentado que solo es compatible con FSDP. -
Necesitamos mejorar la velocidad y reducir el uso de VRAM para entrenar más rápido y ahorrar costos de cómputo.
¡Veamos cómo resolver los desafíos anteriores y afinar un modelo de 70B!
Antes de comenzar, aquí están todos los recursos necesarios para reproducir nuestros resultados:
-
Base de código: https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/training con parche de mono flash-attn V2
-
Configuración de FSDP: https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml
-
Script de SLURM
launch.slurm: https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25 -
Modelo:
meta-llama/Llama-2-70b-chat-hf -
Conjunto de datos: smangrul/code-chat-assistant-v1 (mezcla de LIMA+GUANACO con formato adecuado en un formato listo para entrenar)
Prerrequisitos
Primero, siga estos pasos para instalar Flash Attention V2: Dao-AILab/flash-attention: Atención exacta rápida y eficiente en memoria (github.com). Instale las últimas versiones nocturnas de PyTorch con CUDA ≥11.8. Instale los requisitos restantes según DHS-LLM-Workshop/code_assistant/training/requirements.txt. Aquí, instalaremos 🤗 Accelerate y 🤗 Transformers desde la rama principal.
Afinación
Abordando el desafío 1
Los PRs huggingface/transformers#25107 y huggingface/accelerate#1777 resuelven el primer desafío y no requieren cambios de código por parte del usuario. Hacen lo siguiente:
- Crea el modelo sin pesos en todos los rangos (usando el dispositivo
meta). - Carga el diccionario de estados solo en el rango == 0 y establece los pesos del modelo con ese diccionario de estados en el rango 0.
- Para todos los demás rangos, ejecuta
torch.empty(*param.size(), dtype=dtype)para cada parámetro en el dispositivometa. - Por lo tanto, el rango == 0 habrá cargado el modelo con el diccionario de estados correcto, mientras que todos los demás rangos tendrán pesos aleatorios.
- Establece
sync_module_states=Truepara que el objeto FSDP se encargue de transmitirlos a todos los rangos antes de que comience el entrenamiento.
A continuación se muestra un fragmento de salida de un modelo de 7B en 2 GPUs que muestra la memoria consumida y los parámetros del modelo en varias etapas. Podemos observar que durante la carga del modelo pre-entrenado, el rango 0 y el rango 1 tienen una memoria total máxima de CPU de 32744 MB y 1506 MB, respectivamente. Por lo tanto, solo el rango 0 está cargando el modelo pre-entrenado, lo que permite un uso eficiente de la RAM de la CPU. Los registros completos se pueden encontrar aquí
accelerator.process_index=0 Memoria de GPU antes de ingresar a la carga: 0
accelerator.process_index=0 Memoria de GPU consumida al final de la carga (fin-inicio): 0
accelerator.process_index=0 Memoria de GPU máxima consumida durante la carga (máx-inicio): 0
accelerator.process_index=0 Memoria total máxima de GPU consumida durante la carga (máx): 0
accelerator.process_index=0 Memoria de CPU antes de ingresar a la carga: 926
accelerator.process_index=0 Memoria de CPU consumida al final de la carga (fin-inicio): 26415
accelerator.process_index=0 Memoria de CPU pico consumida durante la carga (pico-inicio): 31818
accelerator.process_index=0 Memoria total máxima de CPU consumida durante la carga (máx): 32744
accelerator.process_index=1 Memoria de GPU antes de ingresar a la carga: 0
accelerator.process_index=1 Memoria de GPU consumida al final de la carga (fin-inicio): 0
accelerator.process_index=1 Memoria de GPU pico consumida durante la carga (pico-inicio): 0
accelerator.process_index=1 Memoria total máxima de GPU consumida durante la carga (máx): 0
accelerator.process_index=1 Memoria de CPU antes de ingresar a la carga: 933
accelerator.process_index=1 Memoria de CPU consumida al final de la carga (fin-inicio): 10
accelerator.process_index=1 Memoria de CPU pico consumida durante la carga (pico-inicio): 573
accelerator.process_index=1 Memoria total máxima de CPU consumida durante la carga (máx): 1506Abordando el desafío 2
Se aborda eligiendo el tipo de diccionario de estados SHARDED_STATE_DICT al crear la configuración de FSDP. SHARDED_STATE_DICT guarda los fragmentos por GPU por separado, lo que facilita guardar o reanudar el entrenamiento desde un punto intermedio. Cuando se utiliza FULL_STATE_DICT, el primer proceso (rango 0) recopila el modelo completo en la CPU y luego lo guarda en un formato estándar.
Creemos la configuración de aceleración mediante el siguiente comando:
accelerate config --config_file "fsdp_config.yaml"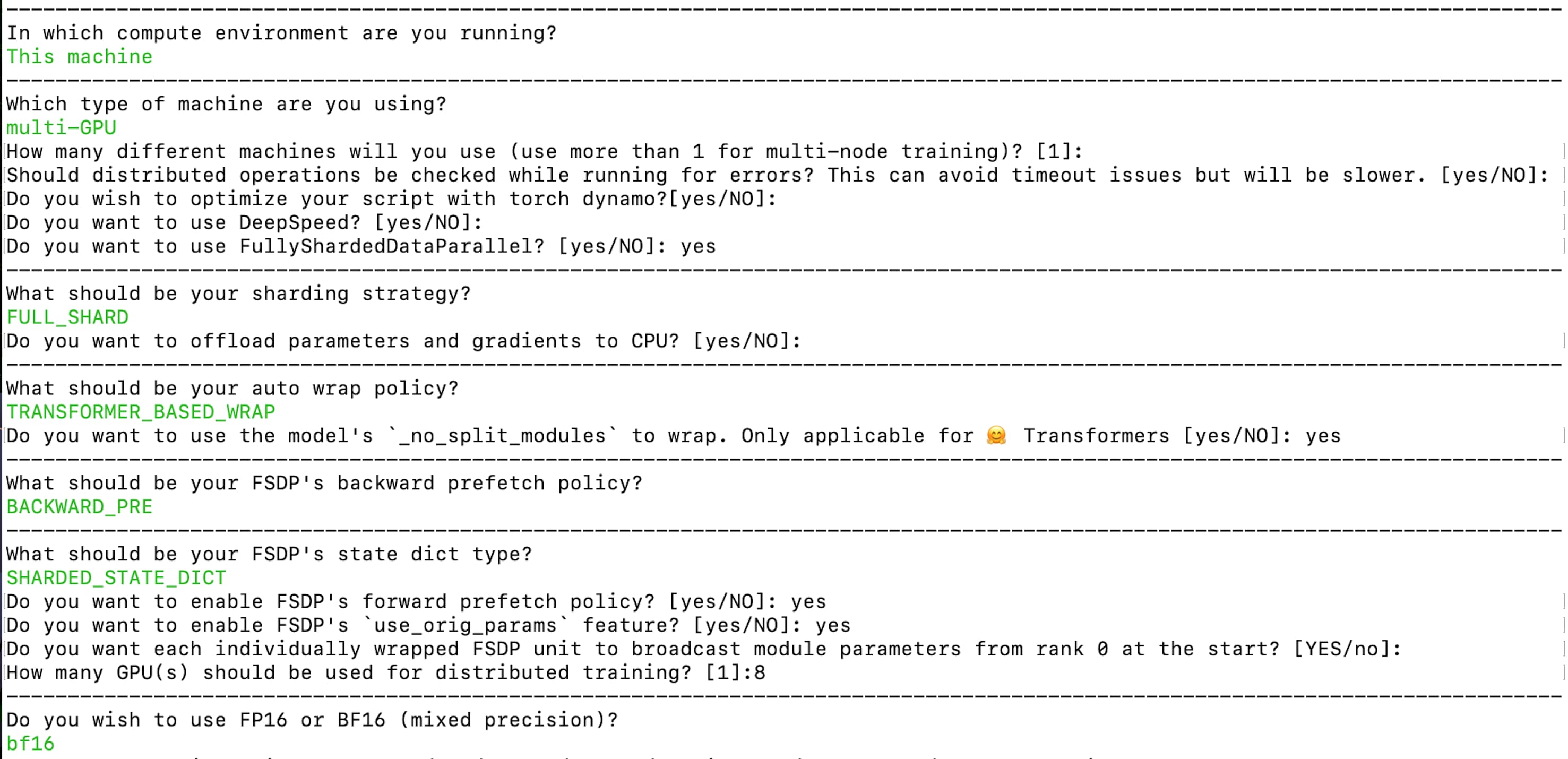
La configuración resultante está disponible aquí: fsdp_config.yaml. Aquí, la estrategia de fragmentación es FULL_SHARD. Estamos utilizando TRANSFORMER_BASED_WRAP para la política de envoltura automática y utiliza _no_split_module para encontrar el nombre del bloque Transformer para la envoltura automática anidada de FSDP. Usamos SHARDED_STATE_DICT para guardar los puntos de control intermedios y los estados del optimizador en este formato recomendado por el equipo de PyTorch. Asegúrese de habilitar la transmisión de parámetros de los módulos desde el rango 0 al inicio, como se menciona en el párrafo anterior sobre el desafío 1. Estamos habilitando el entrenamiento de precisión mixta bf16.
Para el punto de control final que es el diccionario de estados completo del modelo, se utiliza el siguiente fragmento de código:
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir) # alternativamente, trainer.push_to_hub() si el archivo ckpt completo tiene menos de 50GB, ya que el límite de LFS por archivo es de 50GB Abordando el desafío 3
Se requiere Flash Attention y habilitar el checkpointing de gradientes para un entrenamiento más rápido y reducir el uso de VRAM para permitir el ajuste fino y ahorrar costos de cálculo. La base de código actualmente utiliza monkey patching y la implementación se encuentra en chat_assistant/training/llama_flash_attn_monkey_patch.py.
FlashAttention: Atención rápida y eficiente en memoria con conciencia de E/S introduce una forma de calcular la atención exacta siendo más rápida y eficiente en memoria, aprovechando el conocimiento de la jerarquía de memoria del hardware/GPUs subyacente: a mayor ancho de banda/velocidad de la memoria, menor es su capacidad ya que se vuelve más cara.
Si seguimos el blog Haciendo que el Aprendizaje Profundo Vaya Vrum Vrum desde los Principios Básicos, podemos entender que el módulo Attention en el hardware actual está limitado por la memoria/por el ancho de banda. La razón es que la atención principalmente consiste en operaciones elemento a elemento como se muestra a continuación en el lado izquierdo. Podemos observar que las operaciones de enmascaramiento, softmax y dropout ocupan la mayor parte del tiempo en lugar de las multiplicaciones de matrices, que constituyen la mayor parte de los FLOPs.
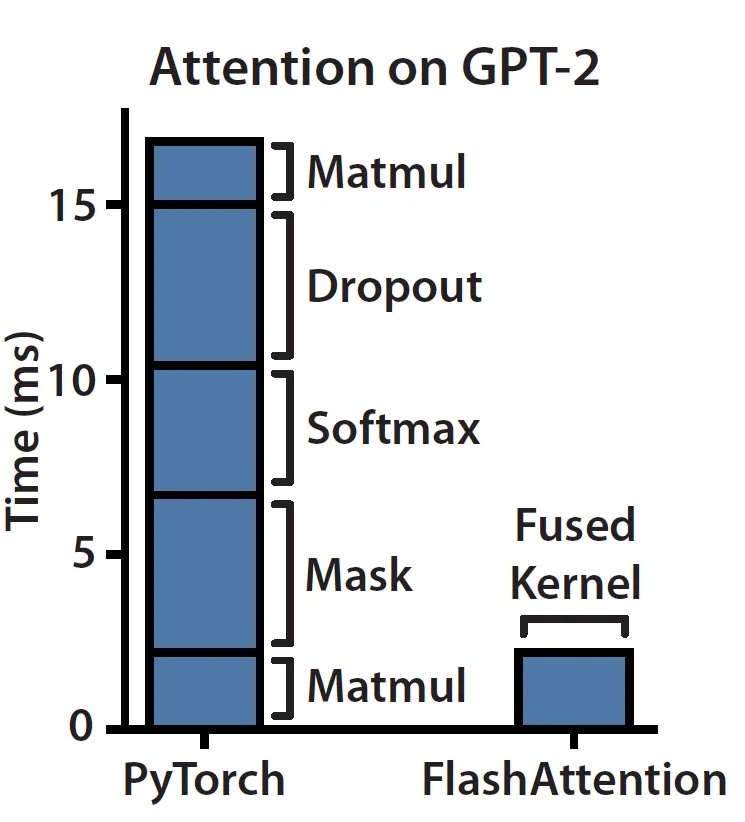
(Fuente: enlace)
Este es precisamente el problema que Flash Attention aborda. La idea es eliminar las lecturas/escrituras redundantes de HBM. Lo hace manteniendo todo en SRAM, realizando todos los pasos intermedios y luego escribiendo el resultado final en HBM, también conocido como Fusión de Kernel. A continuación se muestra una ilustración de cómo se supera el cuello de botella limitado por la memoria. 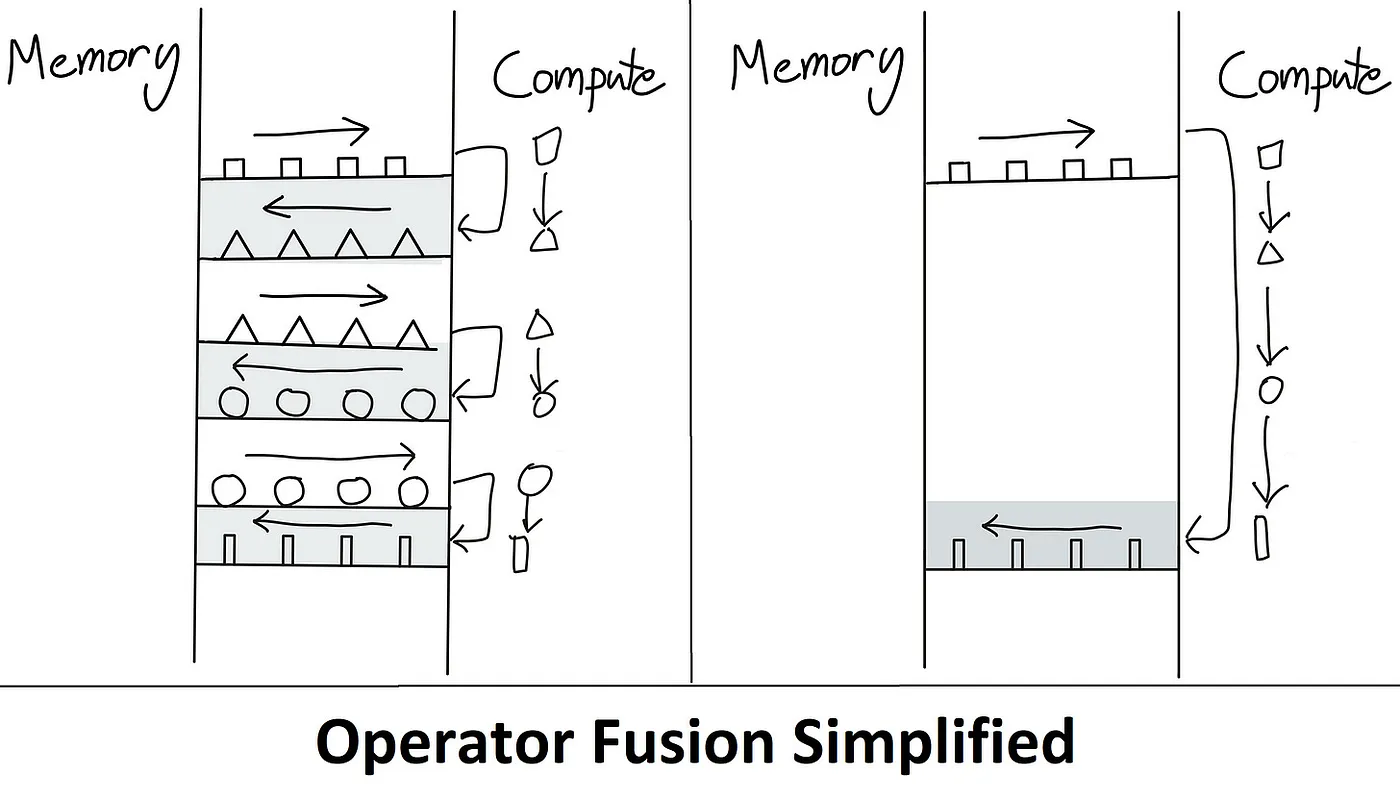
(Fuente: enlace)
Se utiliza el entramado durante los pases hacia adelante y hacia atrás para dividir el cálculo de softmax/puntajes NxN en bloques y superar la limitación del tamaño de la memoria SRAM. Para habilitar el entramado, se utiliza un algoritmo de softmax en línea. Se utiliza la recomputación durante el pase hacia atrás para evitar almacenar la matriz completa de softmax/puntajes NxN durante el pase hacia adelante. Esto reduce enormemente el consumo de memoria.
Para una comprensión simplificada y en profundidad de Flash Attention, consulte las publicaciones de blog ELI5: FlashAttention y Haciendo que el Aprendizaje Profundo Vaya Vrum Vrum desde los Principios Básicos junto con el documento original FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.
Poniéndolo todo junto
Para ejecutar el entrenamiento utilizando el lanzador Accelerate con SLURM, consulte este archivo gist launch.slurm. A continuación se muestra un comando equivalente que muestra cómo utilizar el lanzador Accelerate para ejecutar el entrenamiento. Observa que estamos sobrescribiendo los valores de main_process_ip, main_process_port, machine_rank, num_processes y num_machines del archivo fsdp_config.yaml. Aquí, otro punto importante a tener en cuenta es que el almacenamiento se comparte entre todos los nodos.
accelerate launch \
--config_file configs/fsdp_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank \$MACHINE_RANK \
--num_processes 16 \
--num_machines 2 \
train.py \
--model_name "meta-llama/Llama-2-70b-chat-hf" \
--dataset_name "smangrul/code-chat-assistant-v1" \
--max_seq_len 2048 \
--max_steps 500 \
--logging_steps 25 \
--eval_steps 100 \
--save_steps 250 \
--bf16 True \
--packing True \
--output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--dataset_text_field "content" \
--use_gradient_checkpointing True \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
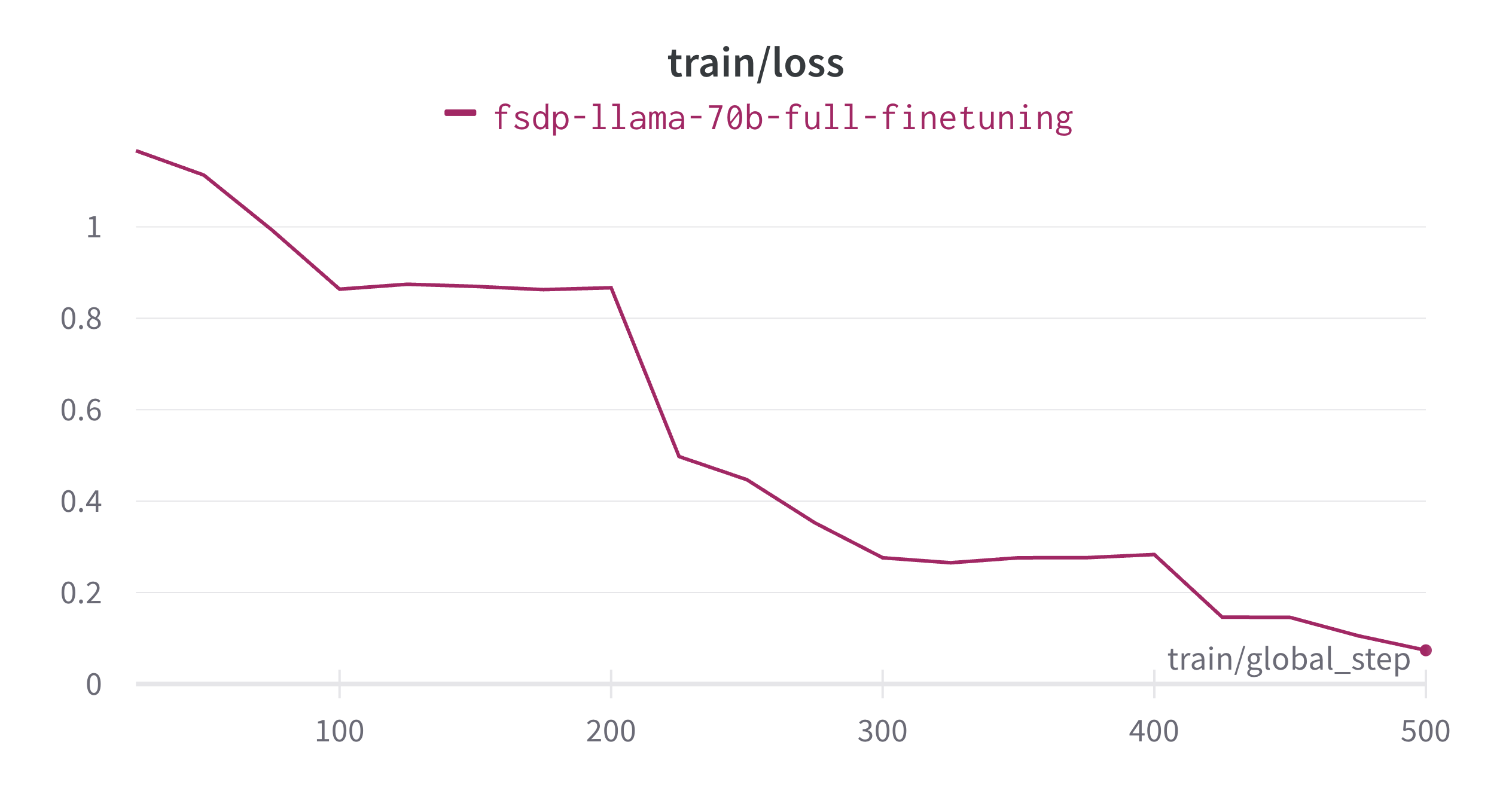
--use_flash_attn TrueLa afinación fina se completó en aproximadamente 13,5 horas y a continuación se muestra el gráfico de pérdida de entrenamiento. Vamos a calcular la utilización de las operaciones de punto flotante del modelo (MFU) para la ejecución de entrenamiento.
- Las GPUs A100 realizan ~3,12e14 FLOPS por segundo (en float32 o bfloat16)
- Número de tokens entrenados en los experimentos anteriores = longitud de secuencia * tamaño de lote * número de pasos de entrenamiento = (2048 * 16 *
- = 16,384,000 = 1,64e7
- Cálculo aproximado para los experimentos anteriores = 6 * P (num_params) * D (num_tokens) = 6 * 7e10 * 1,64e7 = 6,89e18 FLOPS
- FLOPS de entrenamiento por segundo = Cálculo aproximado / tiempo de entrenamiento = 6,89e17 / (13,5 * 3600) = 6,89e18 / 4,86e4 = 1,42e14 FLOPS por segundo
- MFU = FLOPS de entrenamiento por segundo / Rendimiento máximo del A100 = 1,42e14 / 3,12e14 = 0,4551 = 45,51% del rendimiento máximo
A continuación se muestra una conversación de ejemplo utilizando el modelo anterior:
Promotor del sistema: Eres un asistente servicial, respetuoso y honesto. Siempre responde de manera útil, siendo seguro. Tus respuestas no deben incluir contenido perjudicial, no ético, racista, sexista, tóxico, peligroso o ilegal. Asegúrate de que tus respuestas sean socialmente imparciales y positivas en su naturaleza.
Si una pregunta no tiene sentido o no es coherente desde el punto de vista factual, explícalo en lugar de responder algo incorrecto. Si no sabes la respuesta a una pregunta, por favor no compartas información falsa.
- Humano: ¿Qué es el Aprendizaje Profundo? Explícalo como un Pirata.
+ Asistente: ¡Arrr Grumete! ¿Estás buscando una explicación adecuada sobre el Aprendizaje Profundo?
+ ¡Muy bien entonces, escucha atentamente, camarada! El Aprendizaje Profundo es un tipo de aprendizaje automático que utiliza redes neuronales artificiales para analizar datos.
+ ¡Sí, has oído bien, compañeros! Las redes neuronales artificiales son modelos del cerebro humano, pero en lugar de utilizar neuronas, utilizan nodos interconectados o "neuronas artificiales" para procesar información.
+ Estos nodos trabajan juntos para formar capas de unidades de procesamiento que pueden aprender a partir de grandes cantidades de datos.
+ Cuantos más datos reciban estos sistemas, mejor se vuelven para reconocer patrones y tomar decisiones por sí mismos.
+ Así que levanta las velas y pon rumbo a la aventura con el aprendizaje profundo, ¡mis valientes! Es un tesoro de conocimiento esperando a ser descubierto.
+ ¡Vientos favorables y mares tranquilos!
- Humano: Ahora explícalo como un chef.
+ Asistente: ¡Por supuesto! Aquí tienes una explicación del aprendizaje profundo desde una perspectiva culinaria:
+ Piensa en una receta como una secuencia de pasos utilizados para transformar ingredientes crudos en un plato delicioso.
+ De manera similar, en el aprendizaje profundo, hay múltiples capas de "ingredientes" (o características) que se combinan y transforman a través de diversas operaciones para producir un resultado final o predicción.
+ Cada capa se basa en la anterior, refinando y mejorando la representación de los datos de entrada hasta que se alcanza el resultado deseado.
+ Así como diferentes especias realzan los sabores de la comida, cada capa añade profundidad y complejidad a la comprensión del modelo de la entrada, lo que le permite realizar predicciones más precisas.
+ Y al igual que los chefs deben equilibrar cuidadosamente la cantidad de sal, azúcar y otros condimentos en una receta, el proceso de entrenamiento en el aprendizaje profundo implica ajustar los pesos y sesgos de la red para lograr la mezcla perfecta de precisión y eficiencia.
+ Con suficiente práctica y experimentación, cualquiera puede convertirse en un chef maestro... ¡quiero decir, un maestro del aprendizaje profundo! ¡Buen provecho!La conversación completa se muestra de la siguiente manera:
<|sistema|> mensaje del sistema <|endoftext|> <|promotor|> Q1 <|endoftext|> <|asistente|> A1 <|endoftext|> ...Conclusión
Hemos afinado finamente el modelo Llama de 70B utilizando PyTorch FSDP en un entorno multi-nodo y multi-gpu, a la vez que hemos abordado diversos desafíos. Hemos visto cómo 🤗 Transformers y 🤗 Accelerates ahora admiten una forma eficiente de inicializar modelos grandes cuando se utiliza FSDP para evitar que la RAM de la CPU se quede sin memoria. A esto le siguió las prácticas recomendadas para guardar/cargar puntos de control intermedios y cómo guardar el modelo final de una manera lista para usar. Para permitir un entrenamiento más rápido y reducir el uso de memoria de la GPU, hemos destacado la importancia de la Atención Flash y la Verificación Gradiente. En general, podemos ver cómo una configuración sencilla utilizando 🤗 Accelerate permite el ajuste fino de modelos tan grandes en un entorno multi-nodo y multi-gpu.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Pueden los modelos de lenguaje grandes realmente hacer matemáticas? Esta investigación de inteligencia artificial AI presenta MathGLM un modelo robusto para resolver problemas matemáticos sin una calculadora.
- ¿Pueden los robots cuadrúpedos de bajo costo dominar el parkour? Revelando un revolucionario sistema de aprendizaje para el movimiento ágil de robots
- ¿Ha terminado la espera por Jurassic Park? Este modelo de IA utiliza la traducción de imagen a imagen para dar vida a los antiguos fósiles
- El algoritmo de Reingold Tilford explicado, con explicación paso a paso
- Resuelve el Misterio del Gráfico Dentado de COVID
- ¿Cómo influye el Índice Socioeducativo en los resultados de los estudiantes que abandonan la escuela? – Un análisis bayesiano con R y brms
- Mejorando la Sumarización de GPT-4 a través de una Cadena de Indicaciones de Densidad






