Ajusta tu propio modelo de Llama 2 en un cuaderno de Colab
Ajusta modelo Llama 2 en Colab
Una introducción práctica al ajuste fino de LLM

Con el lanzamiento de LLaMA v1, vimos una explosión Cámbrica de modelos ajustados finamente, incluyendo Alpaca, Vicuña y WizardLM, entre otros. Esta tendencia animó a diferentes empresas a lanzar sus propios modelos base con licencias adecuadas para uso comercial, como OpenLLaMA, Falcon, XGen, etc. El lanzamiento de Llama 2 ahora combina los mejores elementos de ambos lados: ofrece un modelo base altamente eficiente junto con una licencia más permisiva.
Durante la primera mitad de 2023, el panorama del software fue significativamente moldeado por el uso generalizado de APIs (como OpenAI API) para crear infraestructuras basadas en Modelos de Lenguaje Grandes (LLMs). Bibliotecas como LangChain y LlamaIndex jugaron un papel crítico en esta tendencia. A medida que avanzamos hacia la segunda mitad del año, el proceso de ajuste fino de estos modelos se está convirtiendo en un procedimiento estándar en el flujo de trabajo de LLMOps. Esta tendencia es impulsada por varios factores: el potencial de ahorro de costos, la capacidad de procesar datos confidenciales e incluso el potencial de desarrollar modelos que superen el rendimiento de modelos prominentes como ChatGPT y GPT-4 en ciertas tareas específicas.
En este artículo, veremos por qué funciona el ajuste fino y cómo implementarlo en un cuaderno de Google Colab para crear tu propio modelo Llama 2. Como de costumbre, el código está disponible en Colab y GitHub.
🔧 Antecedentes sobre el ajuste fino de LLMs
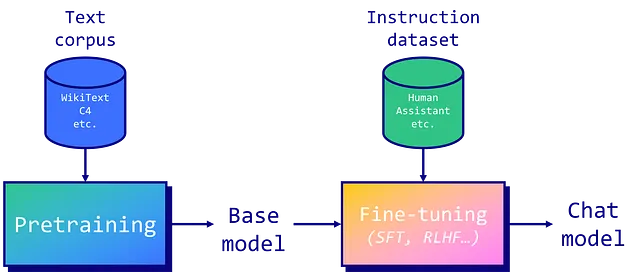
Los LLMs se pre-entrenan en un corpus extenso de texto. En el caso de Llama 2, sabemos muy poco sobre la composición del conjunto de entrenamiento, además de su longitud de 2 billones de tokens. En comparación, BERT (2018) fue “sólo” entrenado en el BookCorpus (800M palabras) y la Wikipedia en inglés (2,500M palabras). Por experiencia, este es un proceso muy costoso y largo con muchos problemas de hardware. Si quieres saber más al respecto, recomiendo leer el diario de Meta sobre el preentrenamiento del modelo OPT-175B.
- Muybridge Derby Dando vida a las fotografías de locomoción animal con IA
- Conoce a Brain2Music Un método de IA para reconstruir música a partir de la actividad cerebral capturada mediante Resonancia Magnética Funcional (fMRI).
- Nuevo curso técnico de inmersión profunda Fundamentos de IA generativa en AWS
Cuando el preentrenamiento está completo, los modelos auto-regresivos como Llama 2 pueden predecir el próximo token en una secuencia. Sin embargo, esto no los convierte en…
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¡Fantástico! Artista 3D se sumerge en trabajos oceánicos impulsados por inteligencia artificial esta semana ‘En el Estudio de NVIDIA
- NVIDIA DGX Cloud ahora disponible para impulsar el entrenamiento de IA generativa
- Regs necesarias para la IA de alto riesgo, dice ACM Es el Viejo Oeste
- La Huella de Carbono de la Inteligencia Artificial
- La modelación en 3D se basa en la inteligencia artificial
- Algoritmo para la detección y movimiento robótico
- Las Pruebas Asistidas por Computadora Abordan el Flujo de Fluidos






