Ajusta de forma interactiva Falcon-40B y otros LLMs en los cuadernos de Amazon SageMaker Studio utilizando QLoRA.
Ajusta Falcon-40B y otros LLMs en cuadernos de Amazon SageMaker Studio de forma interactiva utilizando QLoRA.
Ajustar modelos de lenguaje grandes (LLMs) permite ajustar modelos fundamentales de código abierto para lograr un mejor rendimiento en tareas específicas de tu dominio. En esta publicación, discutiremos las ventajas de utilizar cuadernos de Amazon SageMaker para ajustar modelos de código abierto de última generación. Utilizamos la biblioteca de ajuste fino eficiente en parámetros (PEFT, por sus siglas en inglés) de Hugging Face y técnicas de cuantización a través de bitsandbytes para admitir el ajuste fino interactivo de modelos extremadamente grandes utilizando una sola instancia de cuaderno. Específicamente, mostramos cómo ajustar fino el modelo Falcon-40B utilizando una sola instancia ml.g5.12xlarge (4 GPU A10G), pero la misma estrategia funciona para ajustar incluso modelos más grandes en instancias de cuaderno p4d/p4de.
Típicamente, las representaciones de precisión completa de estos modelos muy grandes no caben en la memoria de una o incluso varias GPU. Para admitir un entorno interactivo de cuaderno para ajustar fino y ejecutar inferencias en modelos de este tamaño, utilizamos una nueva técnica conocida como LLMs cuantizados con adaptadores de rango bajo (QLoRA). QLoRA es un enfoque eficiente de ajuste fino que reduce el uso de memoria de los LLMs manteniendo un rendimiento sólido. Hugging Face y los autores del artículo mencionado han publicado una entrada de blog detallada que cubre los fundamentos e integraciones con las bibliotecas Transformers y PEFT.
Uso de cuadernos para ajustar fino LLMs
SageMaker viene con dos opciones para crear cuadernos completamente administrados para explorar datos y crear modelos de aprendizaje automático (ML, por sus siglas en inglés). La primera opción es un inicio rápido, cuadernos colaborativos accesibles dentro de Amazon SageMaker Studio, un entorno de desarrollo integrado (IDE, por sus siglas en inglés) completamente integrado para ML. Puedes lanzar rápidamente cuadernos en SageMaker Studio, aumentar o disminuir los recursos de cálculo subyacentes sin interrumpir tu trabajo e incluso editar y colaborar en tus cuadernos en tiempo real. Además de crear cuadernos, puedes realizar todos los pasos de desarrollo de ML para construir, entrenar, depurar, rastrear, implementar y monitorear tus modelos en una única interfaz en SageMaker Studio. La segunda opción es una instancia de cuaderno de SageMaker, una instancia de cálculo de ML completamente administrada que ejecuta cuadernos en la nube, lo que te ofrece un mayor control sobre las configuraciones de tu cuaderno.
Para el resto de esta publicación, utilizamos cuadernos de SageMaker Studio porque queremos aprovechar el seguimiento de experimentos gestionado de SageMaker Studio con el soporte de Hugging Face Transformer para TensorBoard. Sin embargo, los mismos conceptos mostrados en el código de ejemplo funcionarán en instancias de cuaderno utilizando el kernel conda_pytorch_p310. Vale la pena mencionar que el volumen de Amazon Elastic File System (Amazon EFS) de SageMaker Studio significa que no necesitas provisionar un tamaño de volumen de Amazon Elastic Block Store (Amazon EBS) predefinido, lo cual es útil dada el gran tamaño de los pesos del modelo en LLMs.
- Difusión estable Intuición básica detrás de la IA generativa
- Construyendo Modelos de Lenguaje Una Guía de Implementación Paso a Paso de BERT
- Generar música a partir de texto utilizando Google MusicLM
El uso de cuadernos respaldados por grandes instancias de GPU permite la creación rápida de prototipos y la depuración sin lanzamientos de contenedores en frío. Sin embargo, también significa que debes apagar tus instancias de cuaderno cuando hayas terminado de usarlas para evitar costos adicionales. Otras opciones como Amazon SageMaker JumpStart y los contenedores de Hugging Face de SageMaker se pueden utilizar para el ajuste fino, y te recomendamos que consultes las siguientes publicaciones sobre los métodos mencionados anteriormente para elegir la mejor opción para ti y tu equipo:
- Ajuste fino de adaptación de dominio de modelos fundamentales en Amazon SageMaker JumpStart en datos financieros
- Entrena un modelo de lenguaje grande en una sola GPU de Amazon SageMaker con Hugging Face y LoRA
Prerrequisitos
Si esta es la primera vez que trabajas con SageMaker Studio, primero debes crear un dominio de SageMaker. También utilizamos una instancia de TensorBoard administrada para el seguimiento de experimentos, aunque esto es opcional para este tutorial.
Además, es posible que necesites solicitar un aumento de la cuota de servicio para las aplicaciones de Gateway de kernel de Studio de SageMaker correspondientes. Para ajustar fino Falcon-40B, utilizamos una instancia ml.g5.12xlarge.
Para solicitar un aumento de la cuota de servicio, en la consola de AWS Service Quotas, ve a AWS services, Amazon SageMaker y selecciona Studio KernelGateway Apps running on ml.g5.12xlarge instances. 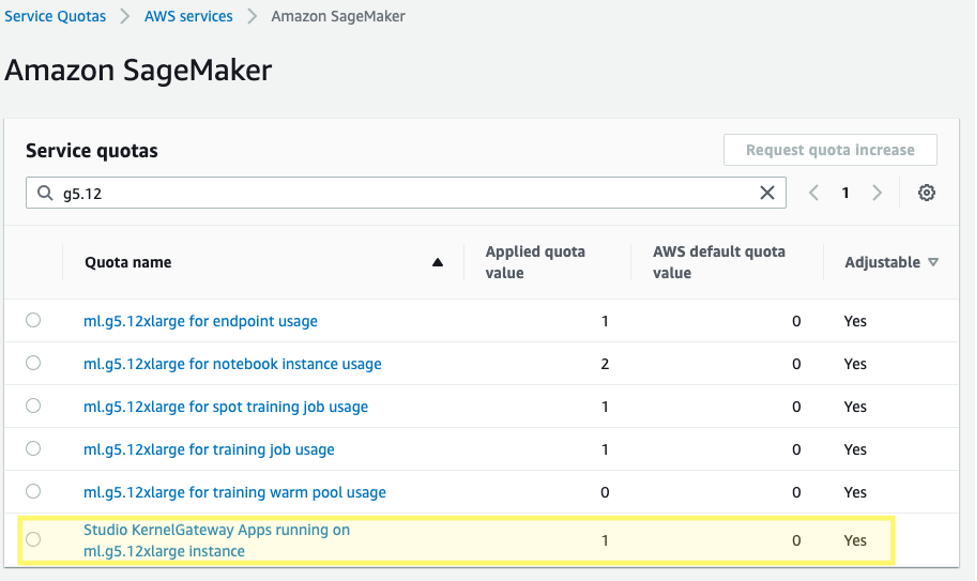
Empezar
El ejemplo de código para esta publicación se puede encontrar en el siguiente repositorio de GitHub. Para comenzar, elegimos la imagen Data Science 3.0 y el kernel Python 3 de SageMaker Studio para tener un entorno de Python 3.10 reciente para instalar nuestros paquetes.

Instalamos PyTorch y las bibliotecas Hugging Face y bitsandbytes necesarias:
%pip install -q -U torch==2.0.1 bitsandbytes==0.39.1
%pip install -q -U datasets py7zr einops tensorboardX
%pip install -q -U git+https://github.com/huggingface/transformers.git@850cf4af0ce281d2c3e7ebfc12e0bc24a9c40714
%pip install -q -U git+https://github.com/huggingface/peft.git@e2b8e3260d3eeb736edf21a2424e89fe3ecf429d
%pip install -q -U git+https://github.com/huggingface/accelerate.git@b76409ba05e6fa7dfc59d50eee1734672126fdbaA continuación, configuramos la ruta del entorno CUDA utilizando la CUDA instalada que fue una dependencia de la instalación de PyTorch. Este es un paso necesario para que la biblioteca bitsandbytes encuentre y cargue correctamente el objeto binario compartido CUDA correcto.
# Agregar tiempo de ejecución de CUDA instalado al camino para bitsandbytes
import os
import nvidia
cuda_install_dir = '/'.join(nvidia.__file__.split('/')[:-1]) + '/cuda_runtime/lib/'
os.environ['LD_LIBRARY_PATH'] = cuda_install_dirCargar el modelo fundamental pre-entrenado
Utilizamos bitsandbytes para cuantizar el modelo Falcon-40B en una precisión de 4 bits para poder cargar el modelo en memoria en 4 GPUs A10G utilizando el paralelismo de canalización ingenua de Hugging Face Accelerate. Como se describe en la publicación de Hugging Face mencionada anteriormente , la sintonización de QLoRA se muestra como comparable a los métodos de ajuste fino de 16 bits en una amplia gama de experimentos porque los pesos del modelo se almacenan como NormalFloat de 4 bits, pero se descuantizan al bfloat16 de cálculo en los pases hacia adelante y hacia atrás según sea necesario.
model_id = "tiiuae/falcon-40b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)Cuando cargamos los pesos pre-entrenados, especificamos device_map="auto" para que Hugging Face Accelerate determine automáticamente en qué GPU colocar cada capa del modelo. Este proceso se conoce como paralelismo de modelos.
# Falcon requiere permitir la ejecución de código remoto. Esto se debe a que el modelo utiliza una nueva arquitectura que aún no forma parte de Transformers.
# El código es proporcionado por los autores del modelo en el repositorio.
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, quantization_config=bnb_config, device_map="auto")Con la biblioteca PEFT de Hugging Face, puedes congelar la mayor parte de los pesos del modelo original y reemplazar o extender las capas del modelo mediante el entrenamiento de un conjunto adicional mucho más pequeño de parámetros. Esto hace que el entrenamiento sea mucho menos costoso en términos de cálculo requerido. Configuramos los módulos Falcon que queremos ajustar finamente como target_modules en la configuración de LoRA:
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=[
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h",
],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
# Salida: parámetros entrenables: 55541760 || todos los parámetros: 20974518272 || entrenables%: 0.2648058910327664Observa que solo estamos ajustando finamente el 0,26% de los parámetros del modelo, lo que hace que esto sea factible en un tiempo razonable.
Cargar un conjunto de datos
Utilizamos el conjunto de datos samsum para nuestro ajuste fino. Samsum es una colección de 16,000 conversaciones similares a mensajes con resúmenes etiquetados. El siguiente es un ejemplo del conjunto de datos:
{
"id": "13818513",
"summary": "Amanda horneó galletas y le llevará algunas a Jerry mañana.",
"dialogue": "Amanda: Horneé galletas. ¿Quieres algunas?\r\nJerry: ¡Claro!\r\nAmanda: Te las llevaré mañana :-)"
}En la práctica, querrás utilizar un conjunto de datos que tenga conocimientos específicos para la tarea en la que esperas ajustar tu modelo. El proceso de construir dicho conjunto de datos puede acelerarse utilizando Amazon SageMaker Ground Truth Plus , como se describe en Comentarios humanos de alta calidad para tus aplicaciones de IA generativa de Amazon SageMaker Ground Truth Plus .
Afinar el modelo
Antes de afinar, definimos los hiperparámetros que queremos utilizar y entrenamos el modelo. También podemos registrar nuestras métricas en TensorBoard definiendo el parámetro logging_dir y solicitando a Hugging Face transformer que report_to="tensorboard" :
bucket = ”<TU-BUCKET-S3>”
log_bucket = f"s3://{bucket}/falcon-40b-qlora-finetune"
import transformers
# Establecemos num_train_epochs=1 simplemente para realizar una demostración
trainer = transformers.Trainer(
model=model,
train_dataset=lm_train_dataset,
eval_dataset=lm_test_dataset,
args=transformers.TrainingArguments(
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_dir=log_bucket,
logging_steps=2,
num_train_epochs=1,
learning_rate=2e-4,
bf16=True,
save_strategy = "no",
output_dir="outputs",
report_to="tensorboard",
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)Monitorear el ajuste fino
Con la configuración anterior, podemos monitorear nuestro ajuste fino en tiempo real. Para monitorear el uso de la GPU en tiempo real, podemos ejecutar nvidia-smi directamente desde el contenedor del kernel. Para iniciar una terminal en ejecución en el contenedor de la imagen, simplemente elige el ícono de la terminal en la parte superior de tu cuaderno.

Desde aquí, podemos utilizar el comando Linux watch para ejecutar repetidamente nvidia-smi cada medio segundo:
watch -n 0.5 nvidia-smi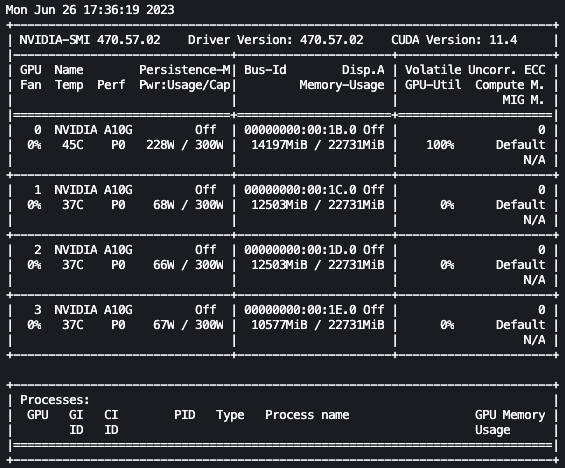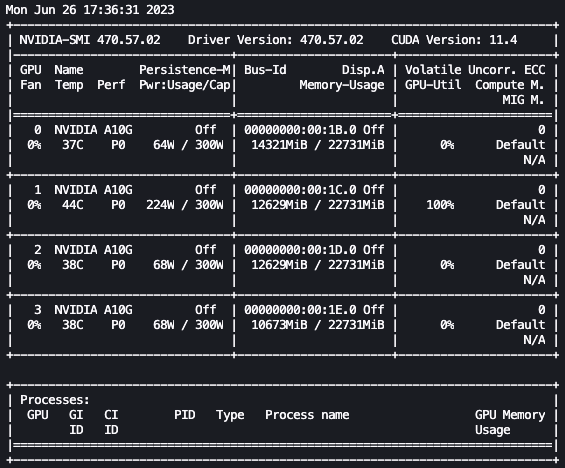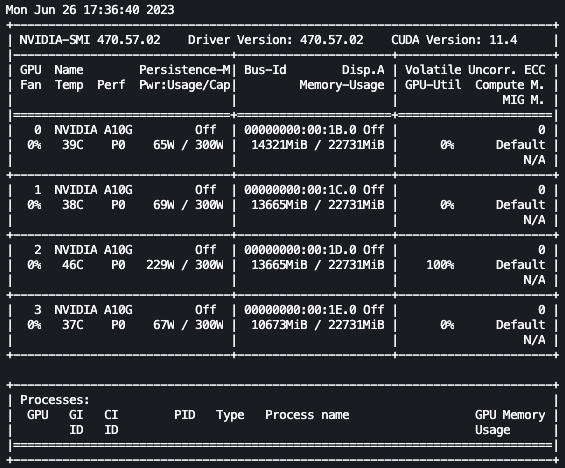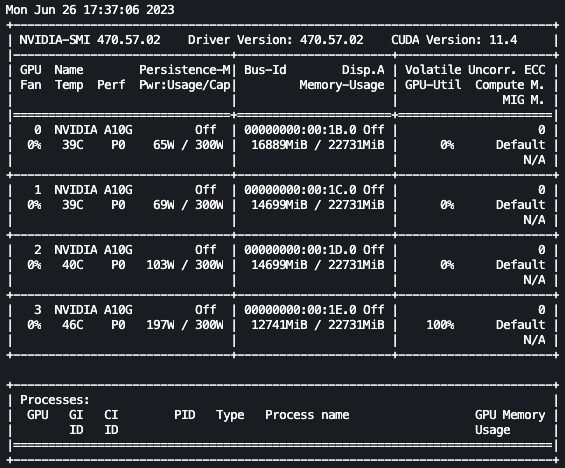
En la animación anterior, podemos ver que los pesos del modelo se distribuyen en las 4 GPUs y el cálculo se distribuye entre ellas a medida que se procesan las capas de manera serial.
Para monitorear las métricas de entrenamiento, utilizamos los registros de TensorBoard que escribimos en el bucket especificado de Amazon Simple Storage Service (Amazon S3). Podemos iniciar TensorBoard de nuestro dominio de SageMaker Studio desde la consola de AWS SageMaker:
Después de cargar, puedes especificar el bucket S3 al que le instruiste al Hugging Face transformer que registre para ver las métricas de entrenamiento y evaluación.
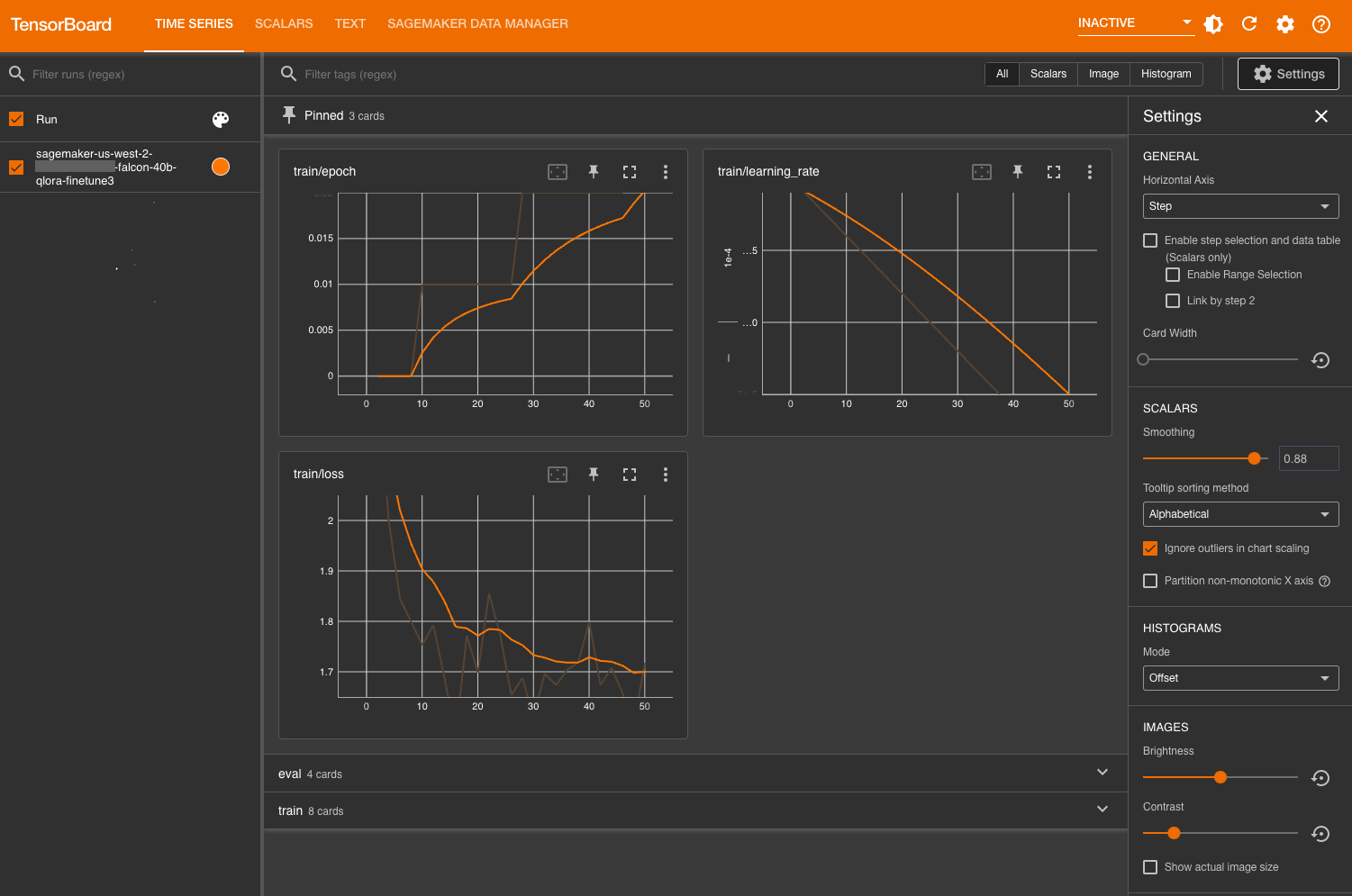
Evaluar el modelo
Después de que nuestro modelo haya terminado de entrenar, podemos realizar evaluaciones sistemáticas o simplemente generar respuestas:
tokens_for_summary = 30
output_tokens = input_ids.shape[1] + tokens_for_summary
outputs = model.generate(inputs=input_ids, do_sample=True, max_length=output_tokens)
gen_text = tokenizer.batch_decode(outputs)[0]
print(gen_text)
# Resultado de muestra:
# Resumir el diálogo del chat:
# Richie: Pogba
# Clay: Pogboom
# Richie: ¡qué golazo!
# Clay: me puse de pie en el momento en que volvió a cortar el balón con su pie derecho
# Richie: yo también, amigo
# Clay: espero que su forma física dure
# Richie: esta temporada está más maduro
# Clay: sí, José confía en él
# Richie: todos confían en él
# Clay: sí, realmente merecía marcar después de sus primeros 60 minutos
# Richie: recompensa
# Clay: sí, amigo
# Richie: genial entonces
# Clay: genial
# ---
# Resumen:
# Richie y Clay han discutido el gol marcado por Paul Pogba. Su forma física esta temporada ha mejorado y ambos esperan que esto dure mucho tiempoDespués de que estés satisfecho con el rendimiento del modelo, puedes guardar el modelo:
trainer.save_model("ruta_para_guardar")También puedes optar por alojarlo en un punto de enlace dedicado de SageMaker.
Limpieza
Completa los siguientes pasos para limpiar tus recursos:
-
Apaga las instancias de SageMaker Studio para evitar incurrir en costos adicionales.
-
Apaga tu aplicación de TensorBoard.
-
Limpia tu directorio EFS eliminando el directorio de caché de Hugging Face:
rm -R ~/.cache/huggingface/hub
Conclusión
Las notebooks de SageMaker te permiten afinar modelos de lenguaje de manera rápida y eficiente en un entorno interactivo. En esta publicación, mostramos cómo puedes utilizar Hugging Face PEFT con bitsandbtyes para afinar modelos Falcon-40B usando QLoRA en las notebooks de SageMaker Studio. Pruébalo y déjanos tus comentarios en la sección de comentarios.
También te animamos a aprender más sobre las capacidades de IA generativa de Amazon explorando SageMaker JumpStart, los modelos de Amazon Titan y Amazon Bedrock.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- LangFlow | Interfaz de usuario para LangChain para desarrollar aplicaciones con LLMs
- Conoce a ChatGLM2-6B la versión de segunda generación del modelo de chat de código abierto bilingüe (chino-inglés) ChatGLM-6B.
- Una Introducción a la Ingeniería de Prompt
- MosaicML acaba de lanzar su MPT-30B bajo la licencia Apache 2.0.
- ¿Qué es Machine Learning como Servicio? Beneficios y principales plataformas de MLaaS.
- Las GPUs NVIDIA H100 establecen el estándar para la IA generativa en el primer benchmark MLPerf.
- La carrera para evitar el peor escenario para el aprendizaje automático





