Agrupación desatada Entendiendo el agrupamiento K-Means
Agrupación desatada K-Means

Mientras analizamos los datos, lo que tenemos en mente es encontrar patrones ocultos y extraer ideas significativas. Vamos a adentrarnos en la nueva categoría de aprendizaje basado en ML, es decir, el aprendizaje no supervisado, en el cual uno de los algoritmos poderosos para resolver las tareas de agrupamiento es el algoritmo de agrupamiento K-Means que revoluciona la comprensión de los datos.
K-Means se ha convertido en un algoritmo útil en aplicaciones de aprendizaje automático y minería de datos. En este artículo, profundizaremos en el funcionamiento de K-Means, su implementación utilizando Python y exploraremos sus principios, aplicaciones, etc. Así que comencemos el viaje para desbloquear los patrones secretos y aprovechar el potencial del algoritmo de agrupamiento K-Means.
- OpenAI insinúa la liberación del modelo GPT de código abierto
- Crea un agente de IA con ChatGPT
- Soñar primero, aprender después DECKARD es un enfoque de IA que utiliza LLMs para entrenar agentes de aprendizaje por refuerzo (RL)
¿Qué es el algoritmo K-Means?
El algoritmo K-Means se utiliza para resolver problemas de agrupamiento que pertenecen a la clase de aprendizaje no supervisado. Con la ayuda de este algoritmo, podemos agrupar el número de observaciones en K grupos.
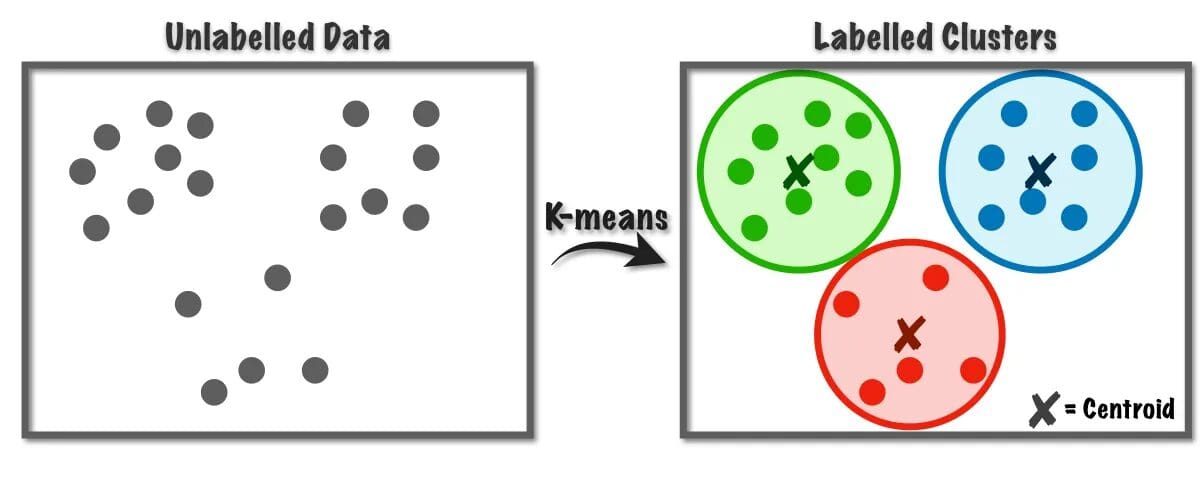
Este algoritmo utiliza internamente la cuantificación vectorial, a través de la cual podemos asignar cada observación en el conjunto de datos al grupo con la distancia mínima, que es el prototipo del algoritmo de agrupamiento. Este algoritmo de agrupamiento se utiliza comúnmente en la minería de datos y el aprendizaje automático para la partición de datos en K grupos basados en métricas de similitud. Por lo tanto, en este algoritmo, tenemos que minimizar la suma de los cuadrados de las distancias entre las observaciones y sus centroides correspondientes, lo que finalmente resulta en grupos distintos y homogéneos.
Aplicaciones del agrupamiento K-Means
Aquí hay algunas de las aplicaciones estándar de este algoritmo. El algoritmo K-Means es una técnica comúnmente utilizada en casos de uso industrial para resolver problemas relacionados con el agrupamiento.
- Segmentación de clientes: El agrupamiento K-Means puede segmentar diferentes clientes según sus intereses. Se puede aplicar en banca, telecomunicaciones, comercio electrónico, deportes, publicidad, ventas, etc.
- Agrupación de documentos: En esta técnica, agrupamos documentos similares de un conjunto de documentos, lo que resulta en documentos similares en los mismos grupos.
- Motores de recomendación: A veces, el agrupamiento K-Means se puede utilizar para crear sistemas de recomendación. Por ejemplo, quieres recomendar canciones a tus amigos. Puedes analizar las canciones que le gustan a esa persona y luego utilizar el agrupamiento para encontrar canciones similares y recomendar las más parecidas.
Hay muchas más aplicaciones que seguramente ya has pensado, las cuales probablemente puedes compartir en la sección de comentarios de este artículo.
Implementación del Agrupamiento K-Means utilizando Python
En esta sección, comenzaremos a implementar el algoritmo K-Means en uno de los conjuntos de datos utilizando Python, principalmente utilizado en proyectos de Ciencia de Datos.
1. Importar bibliotecas y dependencias necesarias
Primero, importemos las bibliotecas de Python que utilizaremos para implementar el algoritmo K-Means, incluyendo NumPy, Pandas, Seaborn, Matplotlib, etc.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
2. Cargar y analizar el conjunto de datos
En este paso, cargaremos el conjunto de datos de estudiantes almacenándolo en el dataframe de Pandas. Para descargar el conjunto de datos, puedes consultar el enlace aquí.
La tubería completa del problema se muestra a continuación:

df = pd.read_csv('student_clustering.csv')
print("La forma de los datos es",df.shape)
df.head()
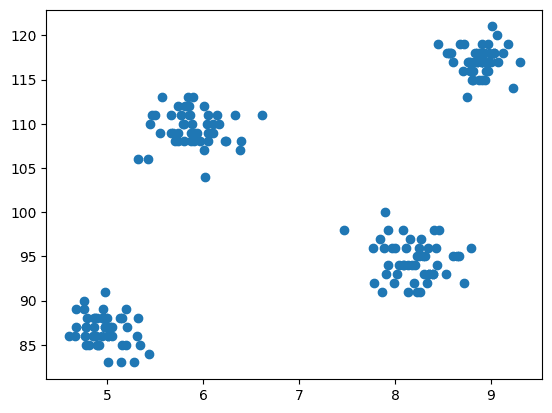
3. Gráfico de dispersión del conjunto de datos
Ahora viene el paso de modelado, que consiste en visualizar los datos, por lo que usamos matplotlib para dibujar el diagrama de dispersión y verificar cómo funciona el algoritmo de agrupamiento y crear diferentes clústeres.
# Diagrama de dispersión del conjunto de datos
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
Resultado:
4. Importar el K-Means de la Clase de Clúster de Scikit-learn
Ahora, como tenemos que implementar el agrupamiento K-Means, primero importamos la clase de clúster y luego tenemos KMeans como el módulo de esa clase.
from sklearn.cluster import KMeans
5. Encontrar el Valor Óptimo de K usando el Método del Codo
En este paso, encontraremos el valor óptimo de K, uno de los hiperparámetros, mientras implementamos el algoritmo. El valor de K indica cuántos clústeres debemos crear para nuestro conjunto de datos. Encontrar este valor intuitivamente no es posible, por lo que para encontrar el valor óptimo, vamos a crear un gráfico entre WCSS (suma de los cuadrados dentro de los clústeres) y diferentes valores de K, y debemos elegir ese K que nos dé el valor mínimo de WCSS.
# crear una lista vacía para almacenar los residuos
wcss = []
for i in range(1,11):
# crear un objeto de la clase K-Means
km = KMeans(n_clusters=i)
# pasar el dataframe para ajustar el algoritmo
km.fit_predict(df)
# agregar el valor de inercia a la lista wcss
wcss.append(km.inertia_)
Ahora, veamos el gráfico del codo para encontrar el valor óptimo de K.
# Gráfico de WCSS vs. K para verificar el valor óptimo de K
plt.plot(range(1,11),wcss)
Resultado:
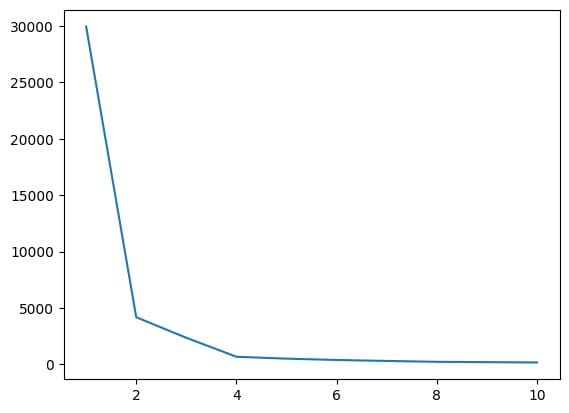
Desde el gráfico del codo anterior, podemos ver que en K=4 hay una disminución en el valor de WCSS, lo que significa que si usamos el valor óptimo como 4, en ese caso, el agrupamiento nos dará un buen rendimiento.
6. Ajustar el Algoritmo K-Means con el valor óptimo de K
Hemos encontrado el valor óptimo de K. Ahora, hagamos el modelado donde crearemos una matriz X que almacena el conjunto de datos completo con todas las características. No es necesario separar el objetivo y el vector de características aquí, ya que es un problema no supervisado. Después de eso, crearemos un objeto de la clase KMeans con un valor K seleccionado y luego lo ajustaremos al conjunto de datos proporcionado. Finalmente, imprimimos y_means, que indica los promedios de los diferentes clústeres formados.
X = df.iloc[:,:].values # se utiliza el conjunto de datos completo para construir el modelo
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means
7. Verificar la Asignación de Clúster de cada Categoría
Verifiquemos a qué clúster pertenecen todos los puntos del conjunto de datos.
X[y_means == 3,1]
Hasta ahora, para la inicialización del centroide, hemos utilizado la estrategia K-Means++, ahora, inicialicemos los centroides aleatorios en lugar de K-Means++ y comparemos los resultados siguiendo el mismo proceso.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
Verificar cuántos valores coinciden.
sum(y_means == y_means_new)
8. Visualización de los Clusters
Para visualizar cada cluster, los representamos en los ejes y les asignamos diferentes colores a través de los cuales podemos ver fácilmente los 4 clusters formados.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red')
plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green')
plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
Salida:

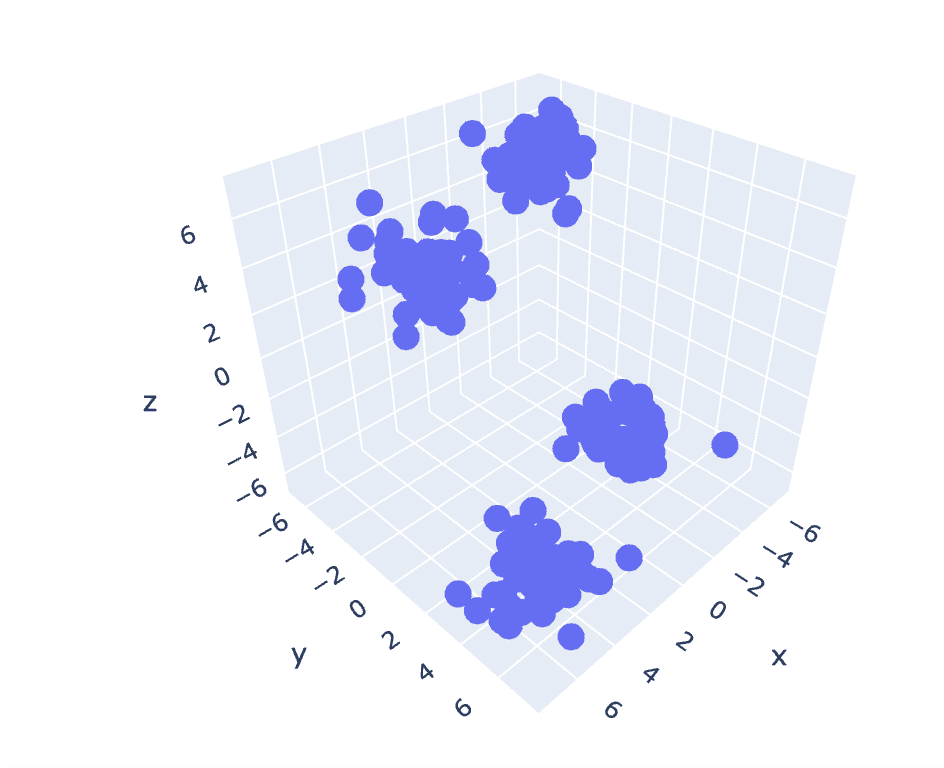
9. K-Means en Datos de 3D
Dado que el conjunto de datos anterior tiene 2 columnas, tenemos un problema 2D. Ahora, utilizaremos el mismo conjunto de pasos para un problema 3D y trataremos de analizar la reproducibilidad del código para datos de n dimensiones.
# Crear un conjunto de datos sintético de sklearn
from sklearn.datasets import make_blobs # hacer un conjunto de datos sintético
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Gráfico de dispersión del conjunto de datos
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
Salida:
wcss = []
for i in range(1,21):
km = KMeans(n_clusters=i)
km.fit_predict(X)
wcss.append(km.inertia_)
plt.plot(range(1,21),wcss)
Salida:
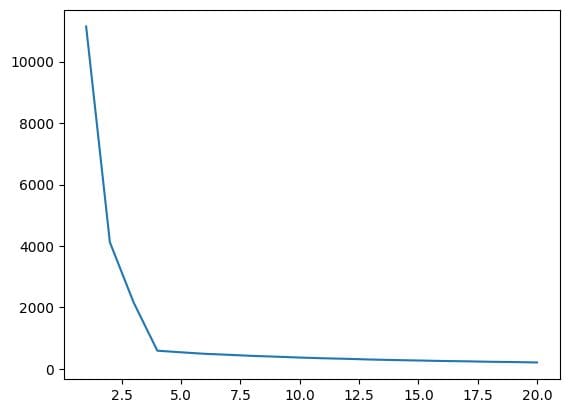 Fig.7 Gráfico del Codo | Imagen del Autor
Fig.7 Gráfico del Codo | Imagen del Autor
# Ajustar el algoritmo de K-Means con el valor óptimo de K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analizar los diferentes clusters formados
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred
fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
Salida:
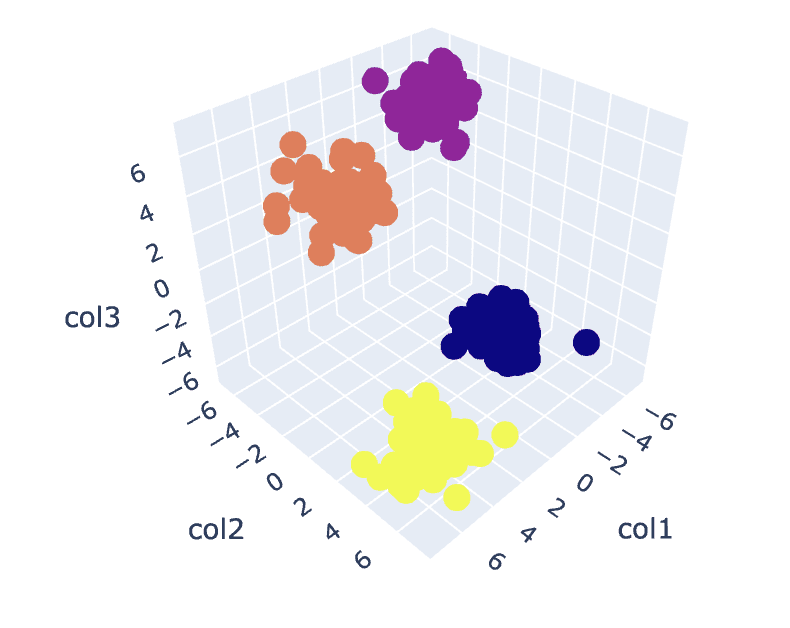 Fig.8. Visualización de Clusters | Imagen del Autor
Fig.8. Visualización de Clusters | Imagen del Autor
Puedes encontrar el código completo aquí – Colab Notebook
Conclusión
Esto completa nuestra discusión. Hemos discutido el funcionamiento, la implementación y las aplicaciones del algoritmo K-Means. En conclusión, implementar las tareas de agrupamiento es un algoritmo ampliamente utilizado de la clase de aprendizaje no supervisado que proporciona un enfoque simple e intuitivo para agrupar las observaciones de un conjunto de datos. La principal fortaleza de este algoritmo es dividir las observaciones en múltiples conjuntos basados en las métricas de similitud seleccionadas con la ayuda del usuario que implementa el algoritmo.
Sin embargo, basado en la selección de centroides en el primer paso, nuestro algoritmo se comporta de manera diferente y converge a óptimos locales o globales. Por lo tanto, seleccionar el número de grupos para implementar el algoritmo, preprocesar los datos, manejar valores atípicos, etc., es crucial para obtener buenos resultados. Pero si observamos el otro lado de este algoritmo más allá de las limitaciones, K-Means es una técnica útil para el análisis exploratorio de datos y el reconocimiento de patrones en diversos campos. Aryan Garg es un estudiante de Ingeniería Eléctrica de B.Tech., actualmente en el último año de su licenciatura. Su interés se encuentra en el campo del Desarrollo Web y el Aprendizaje Automático. Ha seguido este interés y está ansioso por trabajar más en estas direcciones.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una Visión General de los Autoencoders Variacionales
- Empleado de Shopify revela despidos impulsados por IA y crisis en el servicio al cliente
- Cómo los LLM basados en Transformer extraen conocimiento de sus parámetros
- AWS reafirma su compromiso con la IA generativa responsable
- ¿Son útiles las leyendas sintéticas para el entrenamiento multimodal? Este artículo de IA demuestra la efectividad de las leyendas sintéticas en mejorar la calidad de las leyendas para el entrenamiento multimodal.
- Cómo hacer un Chatbot personalizado GPT-4
- Dominando las GPUs Una guía para principiantes sobre DataFrames acelerados por GPU en Python






