Construyendo agentes interactivos en mundos de videojuegos
'Agentes interactivos en videojuegos'
Introducción a un marco de trabajo para crear agentes de IA que pueden entender instrucciones humanas y realizar acciones en entornos de final abierto
El comportamiento humano es notablemente complejo. Incluso una simple solicitud como “Pon la pelota cerca de la caja” todavía requiere una comprensión profunda de la intención situada y el lenguaje. El significado de una palabra como ‘cerca’ puede ser difícil de precisar: colocar la pelota dentro de la caja técnicamente podría ser lo más cercano, pero es probable que el hablante quiera que la pelota se coloque al lado de la caja. Para que una persona actúe correctamente en respuesta a la solicitud, debe ser capaz de comprender y evaluar la situación y el contexto circundante.
La mayoría de los investigadores de inteligencia artificial (IA) creen ahora que es imposible escribir código informático que pueda capturar las sutilezas de las interacciones situadas. En cambio, los investigadores modernos de aprendizaje automático (ML) se han centrado en aprender sobre estos tipos de interacciones a partir de datos. Para explorar estos enfoques de aprendizaje y construir rápidamente agentes que puedan comprender instrucciones humanas y realizar acciones de forma segura en condiciones de final abierto, creamos un marco de trabajo de investigación dentro de un entorno de videojuego.
Hoy, publicamos un artículo y una colección de videos que muestran nuestros primeros pasos en la construcción de IA para videojuegos que pueden entender conceptos humanos difusos y, por lo tanto, pueden comenzar a interactuar con las personas en sus propios términos.
Gran parte del progreso reciente en el entrenamiento de IA para videojuegos se basa en optimizar la puntuación de un juego. Se entrenaron potentes agentes de IA para StarCraft y Dota utilizando las victorias/derrotas claras calculadas por el código informático. En lugar de optimizar una puntuación de juego, pedimos a las personas que inventen tareas y juzguen su progreso ellas mismas.
- Dominando Stratego, el clásico juego de información imperfecta
- AI para el juego de mesa Diplomacy
- Programación competitiva con AlphaCode
Utilizando este enfoque, desarrollamos un paradigma de investigación que nos permite mejorar el comportamiento del agente a través de la interacción fundamentada y de final abierto con los humanos. Aunque aún está en sus primeras etapas, este paradigma crea agentes que pueden escuchar, hablar, hacer preguntas, navegar, buscar y recuperar, manipular objetos y realizar muchas otras actividades en tiempo real.
Esta compilación muestra los comportamientos de los agentes siguiendo tareas planteadas por los participantes humanos:

Aprendizaje en “la casa de juguete”
Nuestro marco de trabajo comienza con personas interactuando con otras personas en el mundo del videojuego. Utilizando el aprendizaje por imitación, dotamos a los agentes de un conjunto amplio pero no refinado de comportamientos. Esta “prioridad de comportamiento” es crucial para permitir interacciones que puedan ser juzgadas por los humanos. Sin esta fase inicial de imitación, los agentes son completamente aleatorios y prácticamente imposibles de interactuar. La evaluación humana adicional del comportamiento del agente y la optimización de estos juicios mediante el aprendizaje por refuerzo (RL) produce agentes mejores, que luego pueden mejorarse nuevamente.
Primero construimos un mundo de videojuegos simple basado en el concepto de una “casa de juegos” para niños. Este entorno proporcionaba un lugar seguro para que los humanos y los agentes interactuaran y facilitaba la recolección rápida de grandes volúmenes de datos de interacción. La casa contaba con una variedad de habitaciones, muebles y objetos configurados en nuevas disposiciones para cada interacción. También creamos una interfaz para la interacción.
Tanto los humanos como los agentes tienen un avatar en el juego que les permite moverse dentro – y manipular – el entorno. También pueden chatear entre ellos en tiempo real y colaborar en actividades, como llevar objetos y entregárselos mutuamente, construir una torre de bloques o limpiar una habitación juntos. Los participantes humanos establecen los contextos para las interacciones navegando por el mundo, estableciendo metas y haciendo preguntas a los agentes. En total, el proyecto recopiló más de 25 años de interacciones en tiempo real entre agentes y cientos de participantes (humanos).
Observando los comportamientos que surgen
Los agentes que entrenamos son capaces de una amplia gama de tareas, algunas de las cuales no fueron anticipadas por los investigadores que los construyeron. Por ejemplo, descubrimos que estos agentes pueden construir filas de objetos usando dos colores alternados o recuperar un objeto de una casa que es similar a otro objeto que el usuario está sosteniendo.
Estas sorpresas surgen porque el lenguaje permite un conjunto casi infinito de tareas y preguntas a través de la composición de significados simples. Además, como investigadores, no especificamos los detalles del comportamiento del agente. En su lugar, los cientos de humanos que participan en las interacciones idearon tareas y preguntas durante el curso de estas interacciones.
Construyendo el marco para crear estos agentes
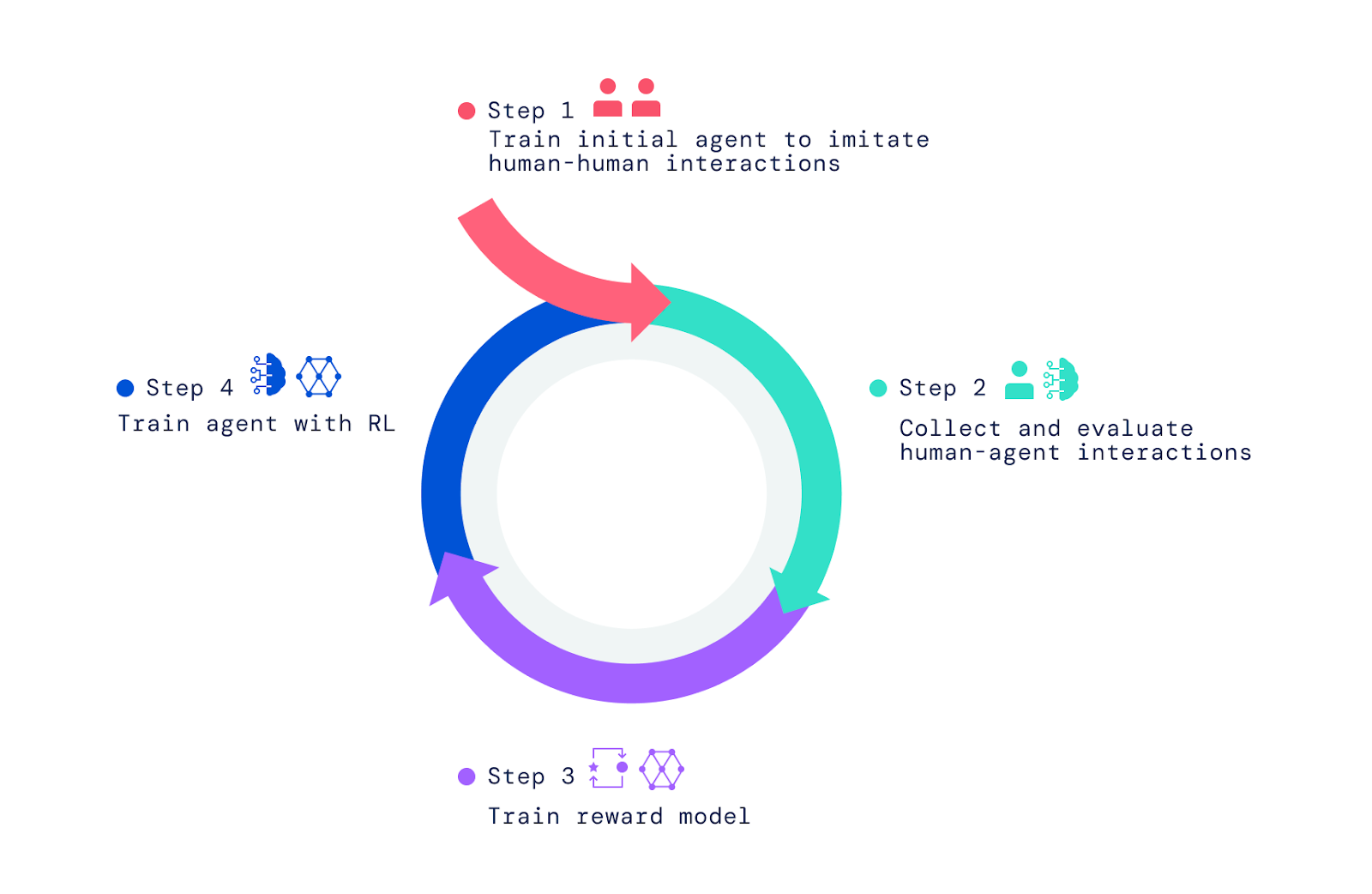
Para crear nuestros agentes de inteligencia artificial, aplicamos tres pasos. Comenzamos entrenando a los agentes para que imiten los elementos básicos de las interacciones humanas simples en las que una persona le pide a otra que haga algo o responda una pregunta. Nos referimos a esta fase como la creación de una base de comportamiento que permite a los agentes tener interacciones significativas con un humano con alta frecuencia. Sin esta fase imitativa, los agentes se mueven al azar y hablan sin sentido. Son casi imposibles de interactuar de manera razonable y darles retroalimentación es aún más difícil. Esta fase se abordó en dos de nuestros artículos anteriores, Imitating Interactive Intelligence y Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning, que exploraron la construcción de agentes basados en imitación.
Superar el aprendizaje por imitación
Aunque el aprendizaje por imitación conduce a interacciones interesantes, trata cada momento de interacción como igualmente importante. Para aprender un comportamiento eficiente y dirigido a objetivos, un agente necesita perseguir un objetivo y dominar movimientos y decisiones particulares en momentos clave. Por ejemplo, los agentes basados en imitación no toman atajos de manera confiable ni realizan tareas con mayor destreza que un jugador humano promedio.
Aquí mostramos un agente basado en aprendizaje por imitación y un agente basado en RL siguiendo la misma instrucción humana:
Para dotar a nuestros agentes de un sentido de propósito, superando lo que es posible a través de la imitación, confiamos en RL, que utiliza el ensayo y error combinado con una medida de rendimiento para la mejora iterativa. A medida que nuestros agentes intentaban diferentes acciones, aquellas que mejoraban el rendimiento eran reforzadas, mientras que aquellas que disminuían el rendimiento eran penalizadas.
En juegos como Atari, Dota, Go y StarCraft, la puntuación proporciona una medida de rendimiento a mejorar. En lugar de usar una puntuación, pedimos a los humanos que evaluaran situaciones y proporcionaran retroalimentación, lo que ayudó a nuestros agentes a aprender un modelo de recompensa.
Entrenando el modelo de recompensa y optimizando agentes
Para entrenar un modelo de recompensa, pedimos a los humanos que juzgaran si observaban eventos que indicaban un progreso notable hacia el objetivo actual instruido o errores notables. Luego establecimos una correspondencia entre estos eventos positivos y negativos y las preferencias positivas y negativas. Dado que ocurren a lo largo del tiempo, llamamos a estos juicios “inter-temporales”. Entrenamos una red neuronal para predecir estas preferencias humanas y obtuvimos como resultado un modelo de recompensa (o utilidad / puntuación) que refleja la retroalimentación humana.
Una vez que entrenamos el modelo de recompensa utilizando las preferencias humanas, lo usamos para optimizar a los agentes. Colocamos a nuestros agentes en el simulador y los dirigimos para responder preguntas y seguir instrucciones. A medida que actuaban y hablaban en el entorno, nuestro modelo de recompensa entrenado evaluaba su comportamiento y utilizábamos un algoritmo de RL para optimizar el rendimiento del agente.
Entonces, ¿de dónde provienen las instrucciones de tarea y las preguntas? Exploramos dos enfoques para esto. Primero, reciclamos las tareas y preguntas planteadas en nuestro conjunto de datos humano. Segundo, entrenamos a los agentes para imitar cómo los humanos establecen tareas y plantean preguntas, como se muestra en este video, donde dos agentes, uno entrenado para imitar a los humanos estableciendo tareas y planteando preguntas (azul) y otro entrenado para seguir instrucciones y responder preguntas (amarillo), interactúan entre sí:
Evaluación y iteración para continuar mejorando agentes
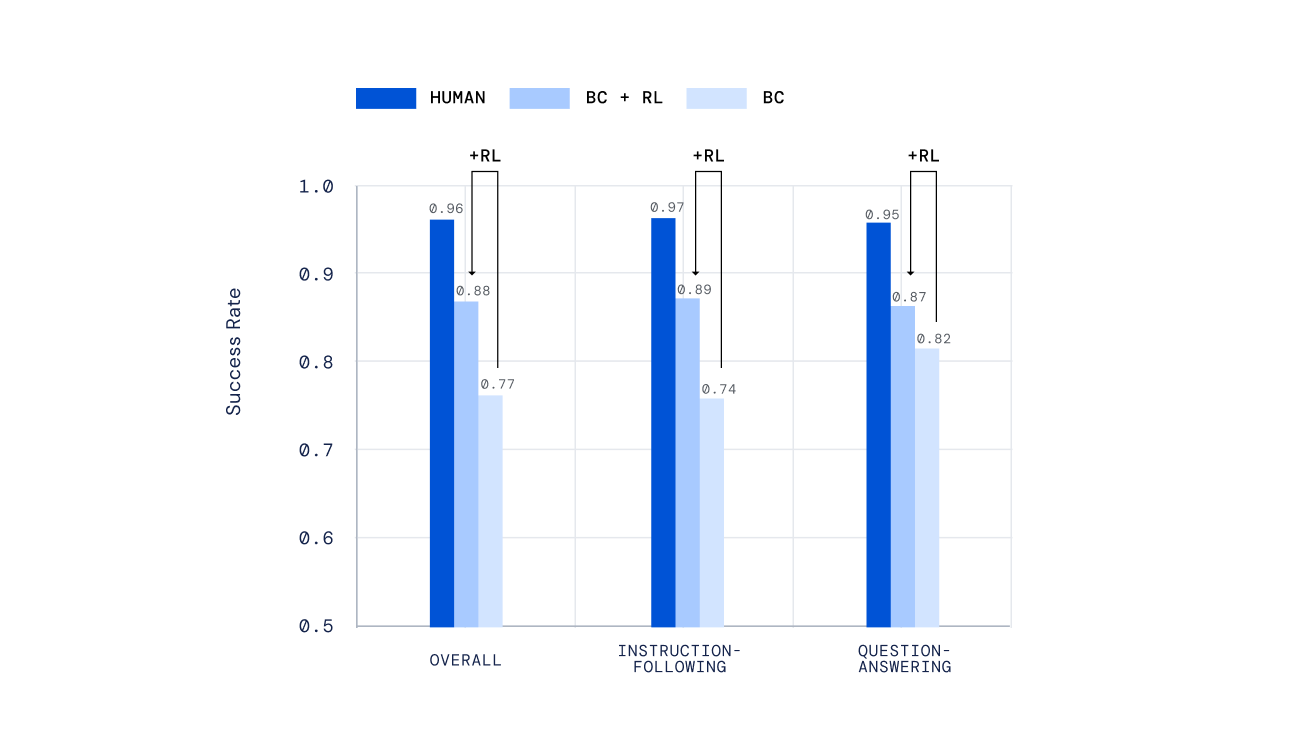
Utilizamos una variedad de mecanismos independientes para evaluar nuestros agentes, desde pruebas hechas a mano hasta un nuevo mecanismo para la puntuación humana offline de tareas abiertas creado por personas, desarrollado en nuestro trabajo anterior Evaluando agentes interactivos multimodales . Es importante destacar que pedimos a las personas interactuar con nuestros agentes en tiempo real y juzgar su desempeño. Nuestros agentes entrenados mediante RL se desempeñaron mucho mejor que aquellos entrenados solo mediante aprendizaje por imitación.
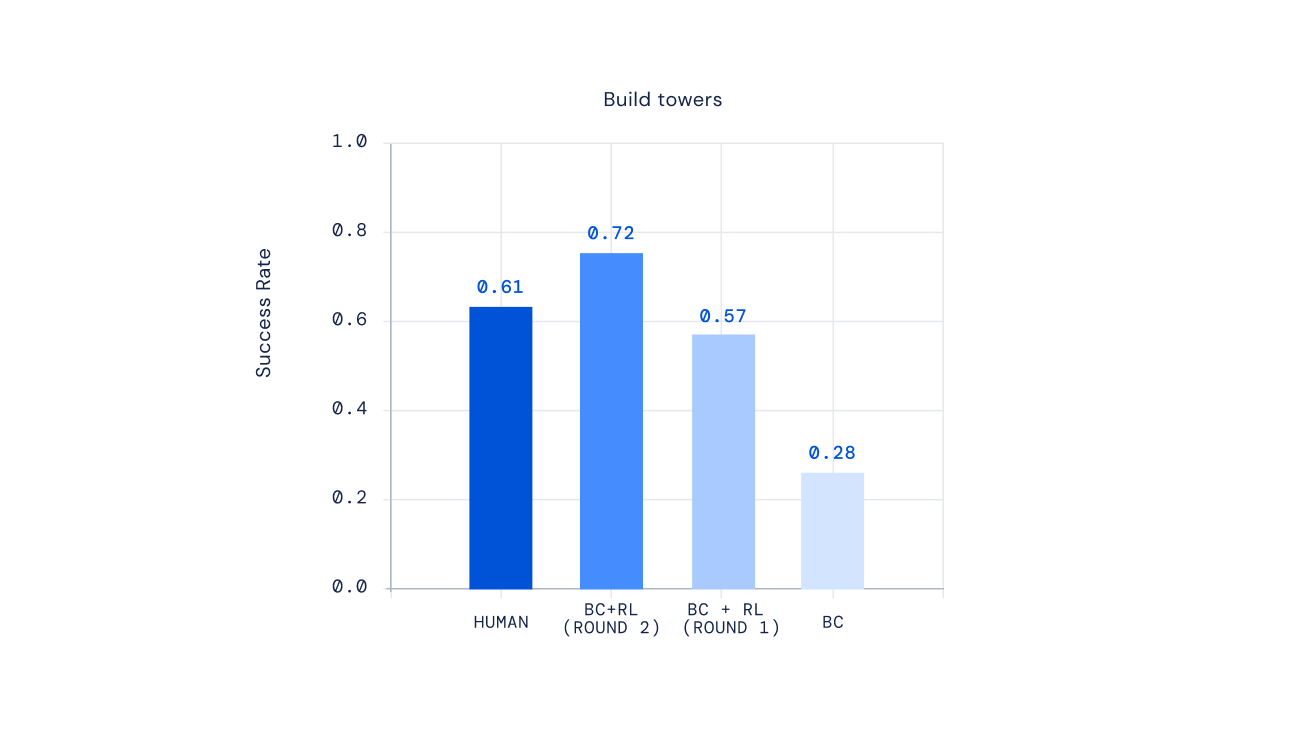
Finalmente, experimentos recientes muestran que podemos iterar el proceso de RL para mejorar repetidamente el comportamiento del agente. Una vez que un agente se entrena mediante RL, pedimos a las personas interactuar con este nuevo agente, anotar su comportamiento, actualizar nuestro modelo de recompensa y luego realizar otra iteración de RL. El resultado de este enfoque fueron agentes cada vez más competentes. Para algunos tipos de instrucciones complejas, incluso pudimos crear agentes que superaron en promedio a los jugadores humanos.
El futuro de la formación de IA para preferencias humanas situadas
La idea de entrenar IA utilizando preferencias humanas como recompensa ha existido durante mucho tiempo. En Deep reinforcement learning from human preferences , los investigadores pioneros enfoques recientes para alinear agentes basados en redes neuronales con preferencias humanas. Trabajos recientes para desarrollar agentes de diálogo por turnos exploraron ideas similares para entrenar asistentes con RL a partir de retroalimentación humana . Nuestra investigación ha adaptado y ampliado estas ideas para construir IA flexibles que pueden dominar un amplio espectro de interacciones multimodales, encarnadas y en tiempo real con personas.
Esperamos que nuestro marco algún día conduzca a la creación de IA de juegos capaces de responder a nuestros significados expresados de manera natural, en lugar de depender de planes de comportamiento escritos a mano. Nuestro marco también podría ser útil para construir asistentes digitales y robóticos con los que las personas puedan interactuar todos los días. Esperamos explorar la posibilidad de aplicar elementos de este marco para crear una IA segura que sea realmente útil.
¿Emocionado por aprender más? Echa un vistazo a nuestro último artículo . Se agradecen los comentarios y la retroalimentación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Cómo podemos incorporar valores humanos en la IA?
- La última investigación de DeepMind en ICLR 2023
- Conoce DragonDiffusion un método de edición de imágenes de granulación fina que permite la manipulación estilo arrastrar en modelos de difusión.
- ¿Qué tan arriesgado es tu proyecto de LLM de código abierto? Una nueva investigación explica los factores de riesgo asociados con los LLM de código abierto.
- AI Ayuda al Gobierno en Prohibir las Conexiones Móviles Falsas
- OpenAI presenta Super Alignment Abriendo el camino para una IA segura y alineada
- Conoce a KITE Un marco de inteligencia artificial para la manipulación semántica utilizando puntos clave como representación para el enlace visual y la inferencia precisa de acciones.






