Imagen Editor y EditBench Avanzando y evaluando el relleno de imágenes guiado por texto.
Advancing and evaluating text-guided image filling in Image Editor and EditBench.
Publicado por Su Wang y Ceslee Montgomery, Ingenieros de Investigación, Investigación de Google
En los últimos años, la investigación en generación de texto a imagen ha experimentado una explosión de avances (notablemente, Imagen, Parti, DALL-E 2, etc.) que han permeado naturalmente en temas relacionados. En particular, la edición de imágenes guiada por texto (TGIE) es una tarea práctica que implica la edición de visuales generados y fotografiados en lugar de volver a crearlos por completo. La edición rápida, automatizada y controlable es una solución conveniente cuando recrear visuales sería consumiría mucho tiempo o sería inviable (por ejemplo, ajustar objetos en fotos de vacaciones o perfeccionar detalles finos en un lindo cachorro generado desde cero). Además, TGIE representa una oportunidad sustancial para mejorar el entrenamiento de los modelos fundamentales en sí mismos. Los modelos multimodales requieren datos diversos para entrenar adecuadamente, y la edición de TGIE puede permitir la generación y recombinación de datos sintéticos de alta calidad y escalables que, quizás lo más importante, pueden proporcionar métodos para optimizar la distribución de los datos de entrenamiento a lo largo de cualquier eje dado.
En “Imagen Editor y EditBench: Avanzando y Evaluando el Inpainting de Imágenes Guiado por Texto”, que se presentará en CVPR 2023, presentamos Imagen Editor, una solución de vanguardia para la tarea de inpainting enmascarado, es decir, cuando un usuario proporciona instrucciones de texto junto con una superposición o “máscara” (generalmente generada dentro de una interfaz de tipo de dibujo) que indica el área de la imagen que le gustaría modificar. También presentamos EditBench, un método que evalúa la calidad de los modelos de edición de imágenes. EditBench va más allá de los métodos gruesos comúnmente utilizados de “¿esta imagen coincide con este texto?” y se enfoca en varios tipos de atributos, objetos y escenas para una comprensión más fina del rendimiento del modelo. En particular, pone un fuerte énfasis en la fidelidad de la alineación de texto e imagen sin perder de vista la calidad de la imagen.
 |
| Dado una imagen, una máscara definida por el usuario y una indicación de texto, Imagen Editor realiza ediciones localizadas en las áreas designadas. El modelo incorpora significativamente la intención del usuario y realiza ediciones fotorrealistas. |
Imagen Editor
Imagen Editor es un modelo de difusión afinado en Imagen para la edición. Se dirige a representaciones mejoradas de entradas lingüísticas, control fino y salidas de alta fidelidad. Imagen Editor toma tres entradas del usuario: 1) la imagen a editar, 2) una máscara binaria para especificar la región de edición y 3) una indicación de texto, las tres entradas guían las muestras de salida.
- Generación Controlable de Imágenes Médicas con ControlNets
- ¡Está vivo! Construye tus primeros robots con Python y algunos componentes baratos y básicos.
- AWS Inferentia2 se basa en AWS Inferentia1 ofreciendo un rendimiento 4 veces mayor y una latencia 10 veces menor.
Imagen Editor depende de tres técnicas principales para el inpainting de imágenes guiado por texto de alta calidad. En primer lugar, a diferencia de los modelos de inpainting anteriores (por ejemplo, Palette, Context Attention, Gated Convolution) que aplican máscaras de caja y trazos aleatorios, Imagen Editor emplea una política de enmascaramiento de detector de objetos con un módulo de detector de objetos que produce máscaras de objetos durante el entrenamiento. Las máscaras de objetos se basan en los objetos detectados en lugar de parches aleatorios y permiten una alineación más principios entre las indicaciones de texto de edición y las regiones enmascaradas. Empíricamente, el método ayuda al modelo a evitar el problema predominante de que la indicación de texto sea ignorada cuando las regiones enmascaradas son pequeñas o solo cubren parcialmente un objeto (por ejemplo, CogView2).
 |
| Las máscaras aleatorias (izquierda) capturan con frecuencia el fondo o intersectan los límites del objeto, definiendo regiones que pueden ser razonablemente inpaintadas solo a partir del contexto de la imagen. Las máscaras de objetos (derecha) son más difíciles de inpaintar solo a partir del contexto de la imagen, lo que anima a los modelos a depender más de las entradas de texto durante el entrenamiento. |
Luego, durante el entrenamiento y la inferencia, Imagen Editor mejora la edición de alta resolución al condicionar la concatenación de la imagen de entrada y la máscara (similar a SR3, Palette y GLIDE), a resolución completa (1024×1024 en este trabajo), canal por canal. Para el modelo de difusión base de 64×64 y los modelos de súper resolución de 64×64→256×256, aplicamos una convolución de submuestreo parametrizada (por ejemplo, convolución con un paso), que encontramos empíricamente que es crítica para una alta fidelidad.
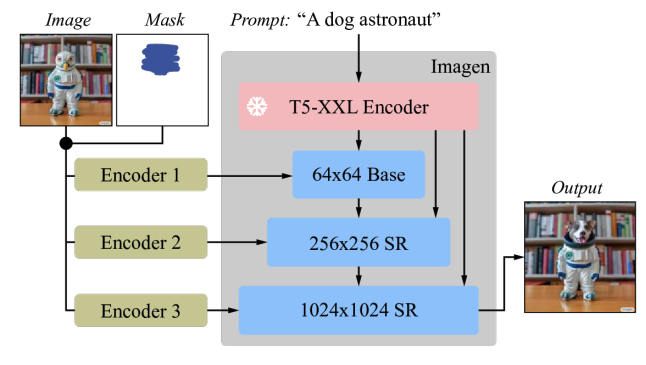 |
| Imagen está afinado para la edición de imágenes. Todos los modelos de difusión, es decir, el modelo base y los modelos de súper resolución (SR), están condicionados a imágenes de alta resolución de 1024×1024 y entradas de máscara. Para este fin, se introducen nuevos codificadores de imagen convolucionales. |
Finalmente, en la inferencia aplicamos guía libre de clasificador (CFG) para sesgar las muestras a una condición particular, en este caso, las indicaciones de texto. CFG interpola entre las predicciones del modelo condicionadas por texto y las no condicionadas para asegurar una fuerte alineación entre la imagen generada y la indicación de texto de entrada para el rellenado de imágenes guiado por texto. Seguimos Imagen Video y usamos pesos de guía altos con oscilación de guía (un cronograma de guía que oscila dentro de un rango de pesos de guía). En el modelo base (la etapa 1 de difusión de 64x), donde asegurar una fuerte alineación con el texto es más crítico, usamos un cronograma de peso de guía que oscila entre 1 y 30. Observamos que los pesos de guía altos combinados con la guía oscilante resultan en el mejor equilibrio entre la fidelidad de la muestra y la alineación texto-imagen.
EditBench
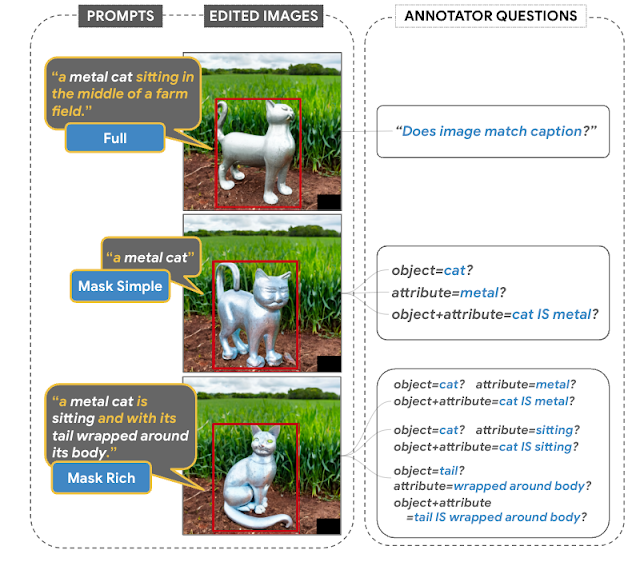
El conjunto de datos EditBench para la evaluación de relleno de imágenes guiado por texto contiene 240 imágenes, con 120 imágenes generadas y 120 naturales. Las imágenes generadas son sintetizadas por Parti y las imágenes naturales se extraen de los conjuntos de datos Visual Genome y Open Images. EditBench captura una amplia variedad de idiomas, tipos de imagen y niveles de especificidad de la indicación de texto (es decir, subtítulos simples, ricos y completos). Cada ejemplo consta de (1) una imagen de entrada enmascarada, (2) una indicación de texto de entrada y (3) una imagen de alta calidad de salida utilizada como referencia para las métricas automáticas. Para proporcionar información sobre las fortalezas y debilidades relativas de diferentes modelos, las indicaciones de texto de EditBench están diseñadas para probar detalles muy finos a lo largo de tres categorías: (1) atributos (por ejemplo, material, color, forma, tamaño, cantidad); (2) tipos de objetos (por ejemplo, común, raro, renderizado de texto); y (3) escenas (por ejemplo, interiores, exteriores, realistas o pinturas). Para entender cómo diferentes especificaciones de indicaciones afectan el rendimiento del modelo, proporcionamos tres tipos de indicaciones de texto: una descripción de un solo atributo (Mask Simple) o una descripción de múltiples atributos del objeto enmascarado (Mask Rich), o una descripción completa de la imagen (Full Image). Mask Rich, en particular, sondea la capacidad de los modelos para manejar la vinculación y la inclusión de atributos complejos.
 |
| La imagen completa se usa como referencia para el relleno exitoso. La máscara cubre el objeto objetivo con una forma libre y no sugestiva. Evaluamos las indicaciones de texto Mask Simple, Mask Rich y Full Image, consistentes con los modelos convencionales de texto a imagen. |
Debido a las debilidades intrínsecas en las métricas de evaluación automática existentes (CLIPScore y CLIP-R-Precision) para TGIE, consideramos la evaluación humana como el estándar de oro para EditBench. En la sección a continuación, demostramos cómo se aplica EditBench a la evaluación de modelos.
Evaluación
Evaluamos el modelo Imagen Editor, con enmascaramiento de objetos (IM) y con enmascaramiento aleatorio (IM-RM), contra modelos comparables, Stable Diffusion (SD) y DALL-E 2 (DL2). Imagen Editor supera a estos modelos por márgenes sustanciales en todas las categorías de evaluación de EditBench.
Para las indicaciones de imagen completa, la evaluación humana de una sola imagen proporciona respuestas binarias para confirmar si la imagen coincide con la leyenda. Para las indicaciones de Máscara Simple, la evaluación humana de una sola imagen confirma si el objeto y el atributo se representan adecuadamente y se enlazan correctamente (por ejemplo, para un gato rojo, un gato blanco sobre una mesa roja sería un enlace incorrecto). La evaluación humana lado a lado utiliza solo las indicaciones de Máscara Rica para comparaciones lado a lado entre IM y cada uno de los otros tres modelos (IM-RM, DL2 y SD), e indica qué imagen coincide mejor con la leyenda para la alineación de texto e imagen, y cuál es la imagen más realista.
 |
| Evaluación humana. Las indicaciones de imagen completa elicitan la impresión general de los anotadores sobre la alineación de texto e imagen; las indicaciones de Máscara Simple y Máscara Rica verifican la inclusión correcta de atributos, objetos y enlaces de atributos. |
Para la evaluación humana de una sola imagen, IM recibe las puntuaciones más altas en todos los aspectos (10-13% más alto que el modelo de mejor rendimiento en segundo lugar). Para el resto, el orden de rendimiento es IM-RM > DL2 > SD (con una diferencia del 3-6%), excepto para Máscara Simple, donde IM-RM cae entre un 4-8%. Como hay relativamente más contenido semántico en Full y Máscara Rica, conjeturamos que IM-RM e IM se benefician del codificador de texto T5 XXL de mejor rendimiento.
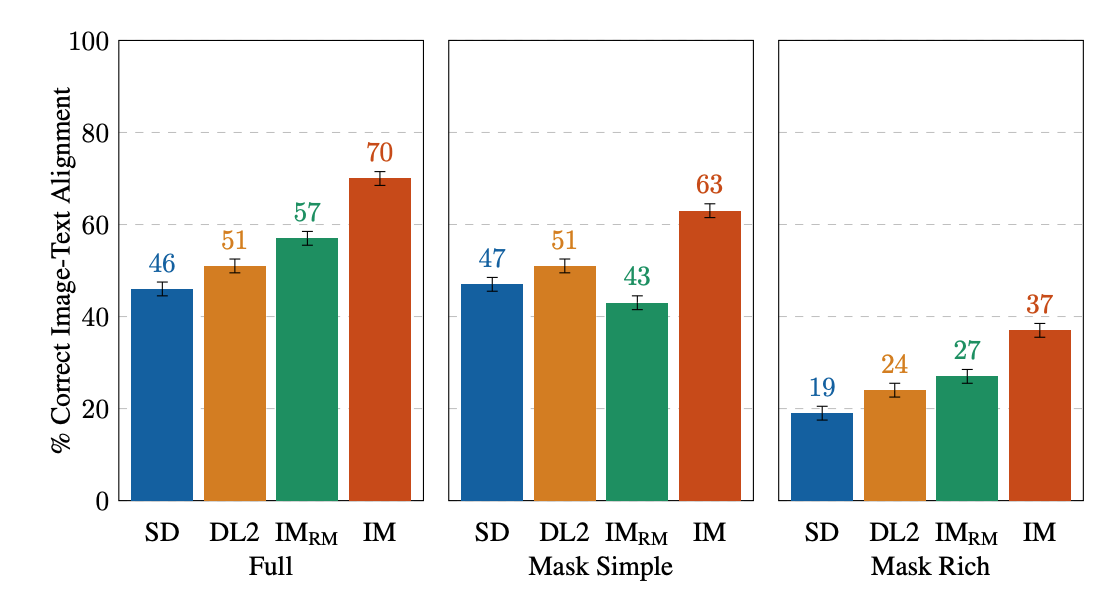 |
| Evaluaciones humanas de una sola imagen de inpainting guiado por texto en EditBench por tipo de indicación. Para las indicaciones de Máscara Simple y Máscara Rica, la alineación de texto e imagen es correcta si la imagen editada incluye con precisión cada atributo y objeto especificado en la indicación, incluido el enlace de atributos correcto. Tenga en cuenta que debido a los diferentes diseños de evaluación, indicaciones completas vs. solo indicaciones de máscara, los resultados son menos directamente comparables. |
EditBench se centra en la anotación detallada, por lo que evaluamos los modelos para tipos de objetos y atributos. Para los tipos de objetos, IM lidera en todas las categorías, con un rendimiento 10-11% mejor que el modelo de mejor rendimiento en segundo lugar en lo común, raro y en la representación de texto.
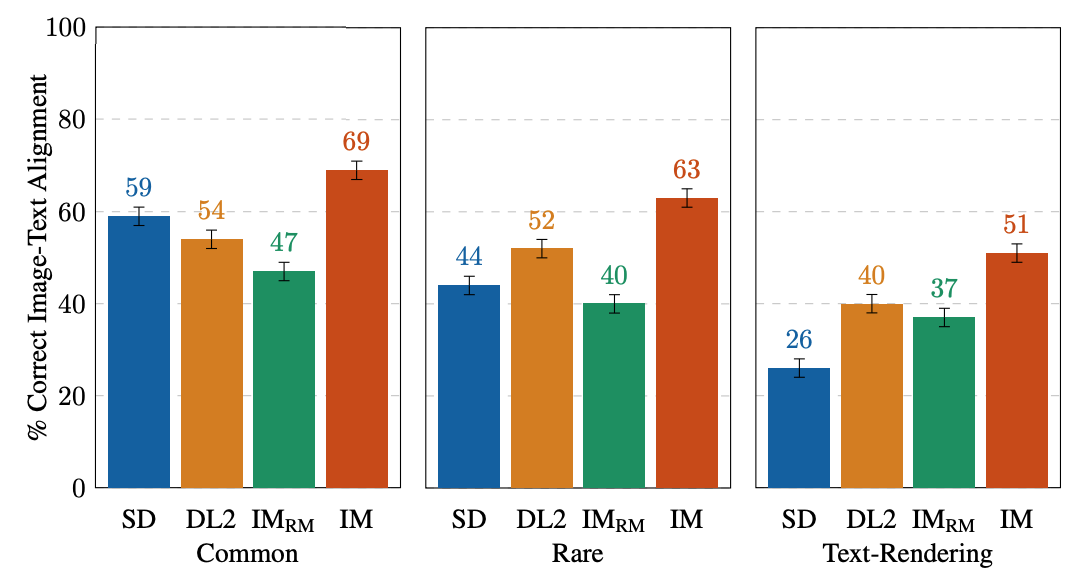 |
| Evaluaciones humanas de una sola imagen en EditBench Máscara Simple por tipo de objeto. Como cohorte, los modelos son mejores en la representación de objetos que en la de texto. |
Para los tipos de atributos, IM tiene una calificación mucho más alta (13-16%) que el segundo modelo con mejor rendimiento, excepto en el recuento, donde DL2 está apenas 1% detrás.
 |
| Evaluaciones humanas de imagen única en EditBench Mask Simple por tipo de atributo. El enmascaramiento de objetos mejora la adherencia a los atributos de la solicitud en general (IM vs. IM-RM). |
En comparación uno a uno con otros modelos, IM lidera en la alineación de texto con un margen sustancial, siendo preferido por los anotadores en comparación con SD, DL2 e IM-RM.
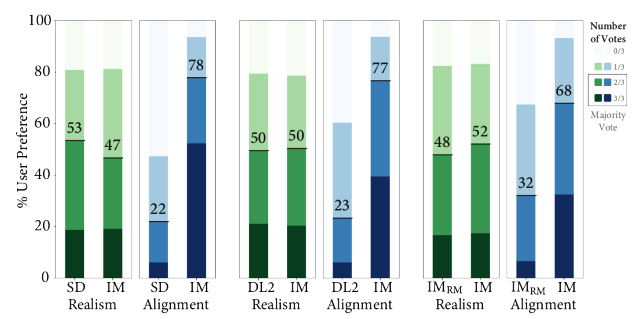 |
| Evaluación humana lado a lado de la realismo de la imagen y la alineación texto-imagen en EditBench Mask Rich prompts. Para la alineación texto-imagen, Imagen Editor es preferido en todas las comparaciones. |
Finalmente, ilustramos una comparativa representativa lado a lado para todos los modelos. Consulte el documento para obtener más ejemplos.
 |
| Ejemplos de modelos de salida para Mask Simple vs. Mask Rich prompts. El enmascaramiento de objetos mejora la adherencia detallada de Imagen Editor a la solicitud en comparación con el mismo modelo entrenado con enmascaramiento aleatorio. |
Conclusión
Presentamos Imagen Editor y EditBench, haciendo avances significativos en la inpainting de imágenes guiada por texto y su evaluación. Imagen Editor es un inpainting de imágenes guiado por texto afinado a partir de Imagen. EditBench es una evaluación sistemática integral para la inpainting de imágenes guiada por texto, evaluando el rendimiento en múltiples dimensiones: atributos, objetos y escenas. Tenga en cuenta que debido a preocupaciones relacionadas con la IA responsable, no estamos lanzando Imagen Editor al público. EditBench, por otro lado, se lanza en su totalidad en beneficio de la comunidad de investigación.
Agradecimientos
Gracias a Gunjan Baid, Nicole Brichtova, Sara Mahdavi, Kathy Meier-Hellstern, Zarana Parekh, Anusha Ramesh, Tris Warkentin, Austin Waters y Vijay Vasudevan por su generoso apoyo. Agradecemos a Igor Karpov, Isabel Kraus-Liang, Raghava Ram Pamidigantam, Mahesh Maddinala y todos los anotadores humanos anónimos por su coordinación para completar las tareas de evaluación humana. Estamos agradecidos con Huiwen Chang, Austin Tarango y Douglas Eck por proporcionar comentarios sobre el documento. Gracias a Erica Moreira y Victor Gomes por su ayuda en la coordinación de recursos. Finalmente, gracias a los autores de DALL-E 2 por darnos permiso para usar sus salidas de modelo con fines de investigación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Generador de subtítulos de inteligencia artificial (para contenido de formato corto)
- Los 5 Mejores Plugins de SEO de ChatGPT
- Herramienta gratuita de fotografía de productos de inteligencia artificial.
- Los efectos de ChatGPT en las escuelas y por qué está siendo prohibido.
- Explorando los Beneficios y Desventajas de Integrar ChatGPT en el Cuidado de la Salud
- Arte generado por IA las implicaciones éticas y los debates
- Crear un panel de análisis de ratios de series de tiempo.






