Técnicas avanzadas de selección de características para modelos de aprendizaje automático
Advanced feature selection techniques for machine learning models.
Dominando la Selección de Características Una Exploración de Técnicas Avanzadas para Modelos de Aprendizaje Automático Supervisado y No Supervisado.

El aprendizaje automático es, sin duda, la estrella brillante de la nueva era. Forma la base de varias tecnologías importantes que se han convertido en parte integral de nuestras vidas diarias, como el reconocimiento facial (respaldado por Redes Neuronales Convolucionales o CNN), el reconocimiento de voz (aprovechando CNN y Redes Neuronales Recurrentes o RNN) y los chatbots cada vez más populares como ChatGPT (impulsado por Aprendizaje por Refuerzo a partir de la Retroalimentación Humana, RLHF).
Hoy en día existen numerosos métodos para mejorar el rendimiento de un modelo de aprendizaje automático. Estos métodos pueden dar a su proyecto una ventaja competitiva al ofrecer un rendimiento superior.
- AI Modelos de Lenguaje y Visión de Gran Escala
- Escala tus cargas de trabajo de aprendizaje automático en Amazon ECS impulsado por instancias AWS Trainium.
- Entrena un Modelo de Lenguaje Grande en una sola GPU de Amazon SageMaker con Hugging Face y LoRA.
En esta discusión, profundizaremos en el ámbito de las técnicas de selección de características. Pero antes de continuar, aclaremos: ¿qué es exactamente la selección de características?
¿Qué es la selección de características?
La selección de características es el proceso de elegir las mejores características para su modelo. Este proceso puede diferir de una técnica a otra, pero el objetivo principal es descubrir qué características tienen más impacto en su modelo.
¿Por qué deberíamos hacer la selección de características?
Porque a veces, tener demasiadas características puede perjudicar su modelo de aprendizaje automático. ¿Cómo?
Puede haber muchas razones diferentes. Por ejemplo, estas características pueden estar relacionadas entre sí, lo que puede causar multicolinealidad y arruinar el rendimiento de su modelo.
Otro problema potencial está relacionado con la potencia computacional. La presencia de demasiadas características requiere más potencia computacional para ejecutar la tarea simultáneamente, lo que podría requerir más recursos y, en consecuencia, mayores costos.
Ciertamente, puede haber otras razones también. Pero estos ejemplos deberían darle una idea general de los problemas potenciales. Sin embargo, hay un aspecto más importante que entender antes de adentrarnos más en este tema.
¿Qué método de selección de características será mejor para mi modelo?
Sí, esa es una gran pregunta y debe responderse antes de comenzar el proyecto. Pero no es fácil dar una respuesta genérica.
La elección del modelo de selección de características depende del tipo de datos que tenga y del objetivo de su proyecto.
Por ejemplo, los métodos basados en filtros como la prueba de chi-cuadrado o la ganancia de información mutua se utilizan típicamente para la selección de características en datos categóricos. Los métodos basados en wrappers como la selección hacia adelante o hacia atrás son adecuados para datos numéricos.
Sin embargo, es bueno saber que muchos métodos de selección de características pueden manejar tanto datos categóricos como numéricos.
Por ejemplo, la regresión Lasso, los árboles de decisión y los bosques aleatorios pueden manejar ambos tipos de datos bastante bien.
En términos de selección de características supervisadas y no supervisadas, los métodos supervisados como la eliminación recursiva de características o los árboles de decisión son buenos para datos etiquetados. Los métodos no supervisados como el análisis de componentes principales (PCA) o el análisis de componentes independientes (ICA) se utilizan para datos no etiquetados.
En última instancia, la elección del método de selección de características debe basarse en las características específicas de sus datos y los objetivos de su proyecto.
Eche un vistazo a la visión general de los temas que discutiremos en el artículo. Familiarícese con ella y comencemos con las técnicas de selección de características supervisadas. 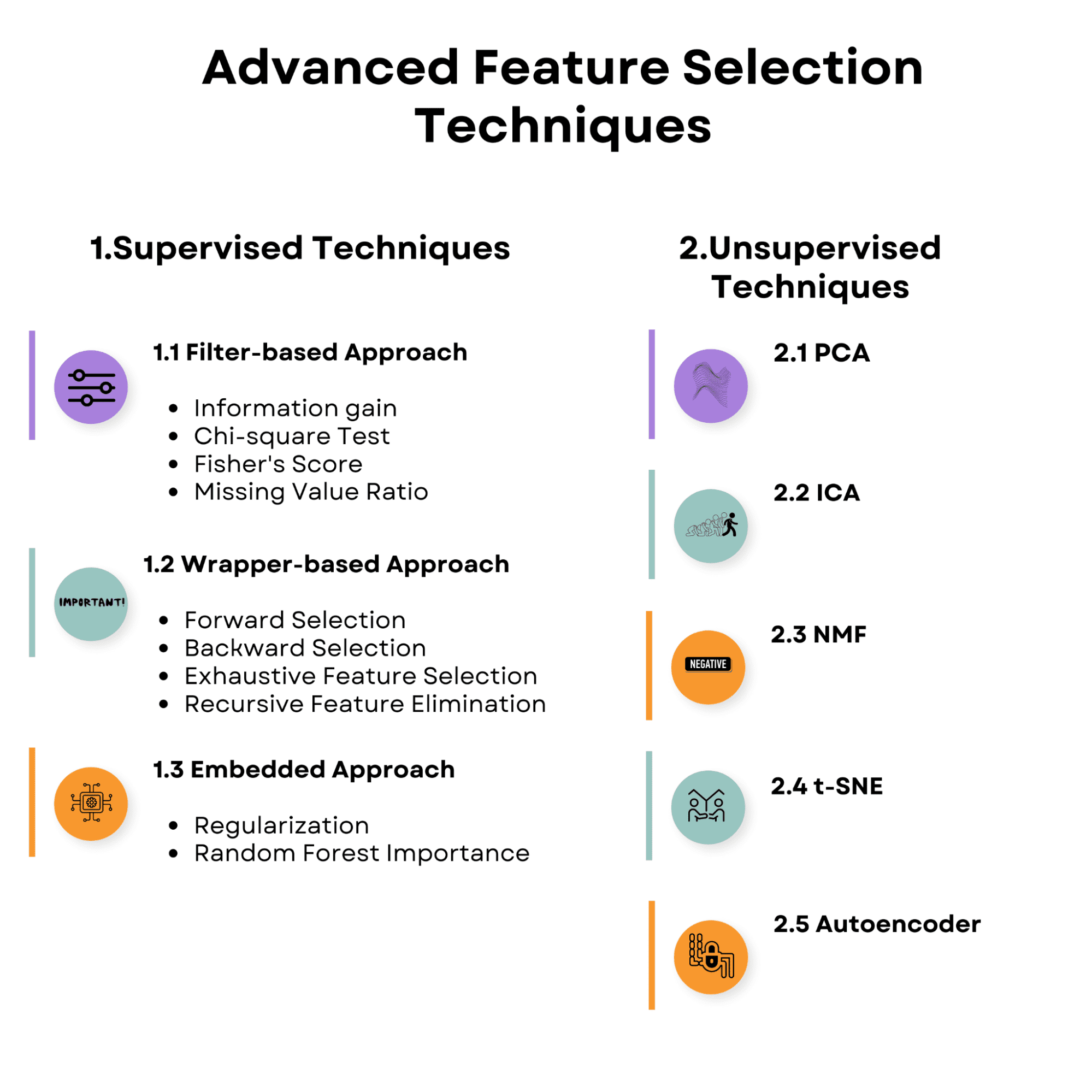
1. Técnicas de selección de características supervisadas
Las estrategias de selección de características en el aprendizaje supervisado tienen como objetivo descubrir las características más relevantes para predecir la variable objetivo utilizando la relación entre las características de entrada y la variable objetivo. Estas estrategias pueden ayudar a mejorar el rendimiento del modelo, reducir el sobreajuste y reducir el costo computacional del entrenamiento del modelo.
Aquí está la visión general de las técnicas de selección de características supervisadas de las que hablaremos.
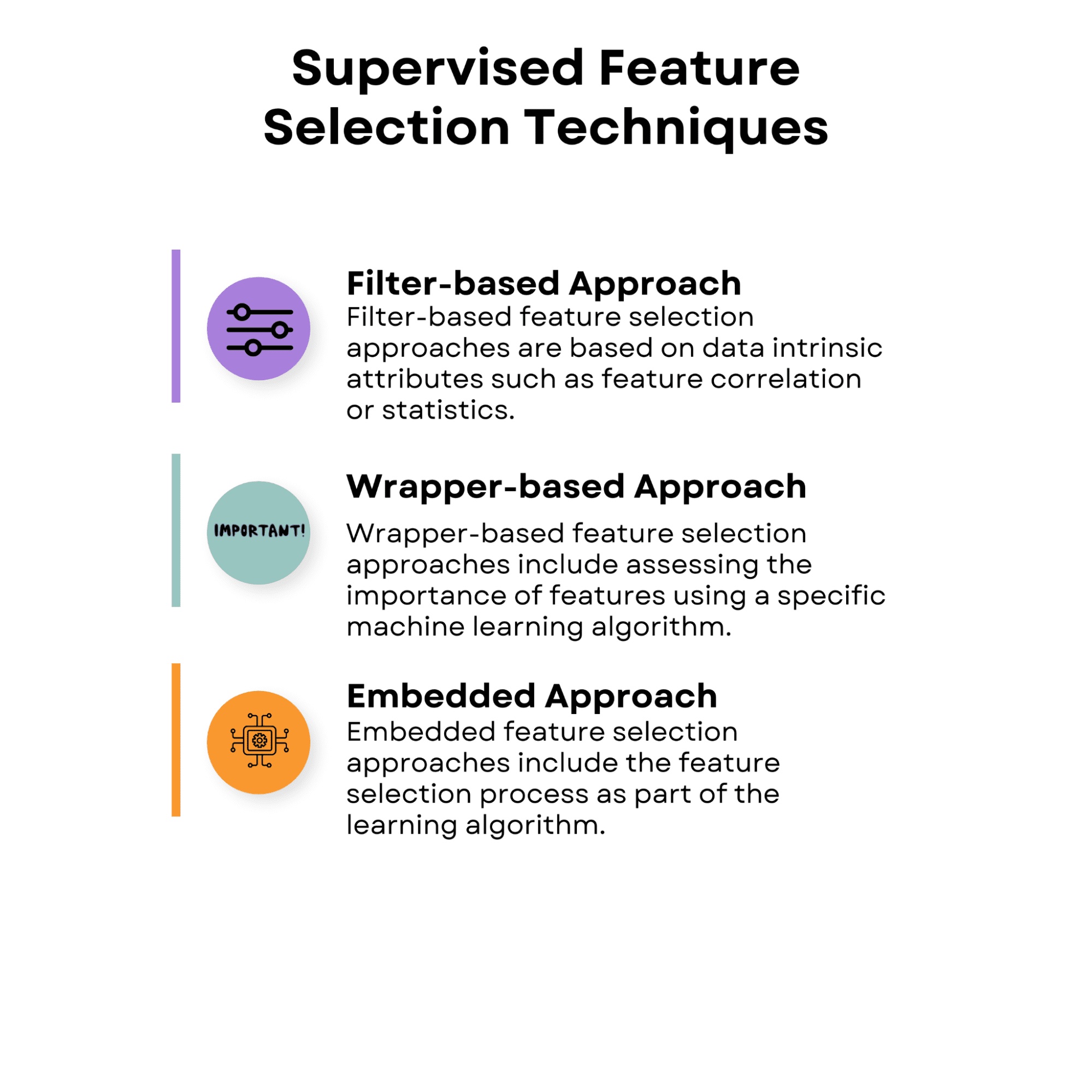
1.1 Enfoque basado en filtros
Los enfoques de selección de características basados en filtros se basan en atributos intrínsecos de los datos, como la correlación de características o las estadísticas. Estos enfoques evalúan el valor de cada característica por separado o en pares sin tener en cuenta el rendimiento de un algoritmo de aprendizaje particular.
Los enfoques basados en filtros son computacionalmente eficientes y se pueden utilizar con una variedad de algoritmos de aprendizaje. Sin embargo, debido a que no tienen en cuenta la interacción entre las características y el método de aprendizaje, es posible que no siempre capturen el subconjunto de características ideal para un determinado algoritmo.
Echa un vistazo a la descripción general de los enfoques basados en filtros y luego discutiremos cada uno.

Ganancia de Información
Ganancia de Información es una estadística que mide la reducción en la entropía (incertidumbre) para una característica específica al dividir los datos según esa característica. Se utiliza a menudo en algoritmos de árboles de decisión y también tiene características útiles. Cuanto mayor sea la ganancia de información de una característica, más útil será para la toma de decisiones.
Ahora, apliquemos la ganancia de información utilizando un conjunto de datos preconstruido de diabetes.
El conjunto de datos de diabetes contiene características fisiológicas relacionadas con la predicción de la progresión de la diabetes.
- edad: Edad en años
- sexo: Género (1 = masculino, 0 = femenino)
- BMI: Índice de masa corporal, calculado como el peso en kilogramos dividido por el cuadrado de la altura en metros
- bp: Presión arterial promedio (mm Hg)
- s1, s2, s3, s4, s5, s6: Mediciones de suero sanguíneo de seis productos químicos sanguíneos diferentes (incluyendo glucosa)
El siguiente código muestra cómo aplicar el método Ganancia de Información. Este código utiliza el conjunto de datos de diabetes de la biblioteca sklearn como ejemplo.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# Cargar el conjunto de datos de diabetes
data = load_diabetes()
# Dividir el conjunto de datos en características y objetivo
X = data.data
y = data.targetEl objetivo principal de este código es calcular puntuaciones de importancia de características basadas en Ganancia de Información, lo que ayuda a identificar las características más relevantes para el modelo predictivo. Al determinar estas puntuaciones, se pueden tomar decisiones informadas sobre qué características incluir o excluir de su análisis, lo que finalmente conduce a una mejora del rendimiento del modelo, una reducción del sobreajuste y tiempos de entrenamiento más rápidos.
Para lograr esto, este código calcula puntuaciones de Ganancia de Información para cada característica en el conjunto de datos y las almacena en un diccionario.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# Cargar el conjunto de datos de diabetes
data = load_diabetes()
# Dividir el conjunto de datos en características y objetivo
X = data.data
y = data.target
# Aplicar Ganancia de Información
ig = mutual_info_regression(X, y)
# Crear un diccionario de puntuaciones de importancia de características
feature_scores = {}
for i in range(len(data.feature_names)):
feature_scores[data.feature_names[i]] = ig[i]Luego, las características se ordenan en orden descendente según sus puntuaciones.
# Ordenar las características por puntuación de importancia en orden descendente
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True)
# Imprimir las puntuaciones de importancia de características y las características ordenadas
for feature, score in sorted_features:
print('Característica:', feature, 'Puntuación:', score)Visualizaremos las puntuaciones de importancia de características ordenadas como un gráfico de barras horizontal, lo que le permitirá comparar fácilmente la relevancia de diferentes características para la tarea dada.
Esta visualización es particularmente útil al decidir qué características retener o descartar al construir un modelo de aprendizaje automático.
# Graficar un gráfico de barras horizontal de las puntuaciones de importancia de características
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Las etiquetas se leen de arriba hacia abajo
ax.set_xlabel("Puntuación de importancia")
ax.set_title("Puntuaciones de importancia de características (Ganancia de Información)")
# Agregar puntuaciones de importancia como etiquetas en el gráfico de barras horizontal
for i, v in enumerate([score for feature, score in sorted_features]):
ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()Veamos todo el código.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# Cargar el conjunto de datos de diabetes
data = load_diabetes()
# Dividir el conjunto de datos en características y objetivo
X = data.data
y = data.target
# Aplicar Ganancia de Información
ig = mutual_info_regression(X, y)
# Crear un diccionario de puntuaciones de importancia de características
feature_scores = {}
for i in range(len(data.feature_names)):
feature_scores[data.feature_names[i]] = ig[i]
# Ordenar las características por puntuación de importancia en orden descendente
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True)
# Imprimir las puntuaciones de importancia de características y las características ordenadas
for feature, score in sorted_features:
print("Característica:", feature, "Puntuación:", score)
# Graficar un gráfico de barras horizontal de las puntuaciones de importancia de características
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Las etiquetas se leen de arriba hacia abajo
ax.set_xlabel("Puntuación de importancia")
ax.set_title("Puntuaciones de importancia de características (Ganancia de Información)")
# Agregar puntuaciones de importancia como etiquetas en el gráfico de barras horizontal
for i, v in enumerate([score for feature, score in sorted_features]):
ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()Aquí está la salida. 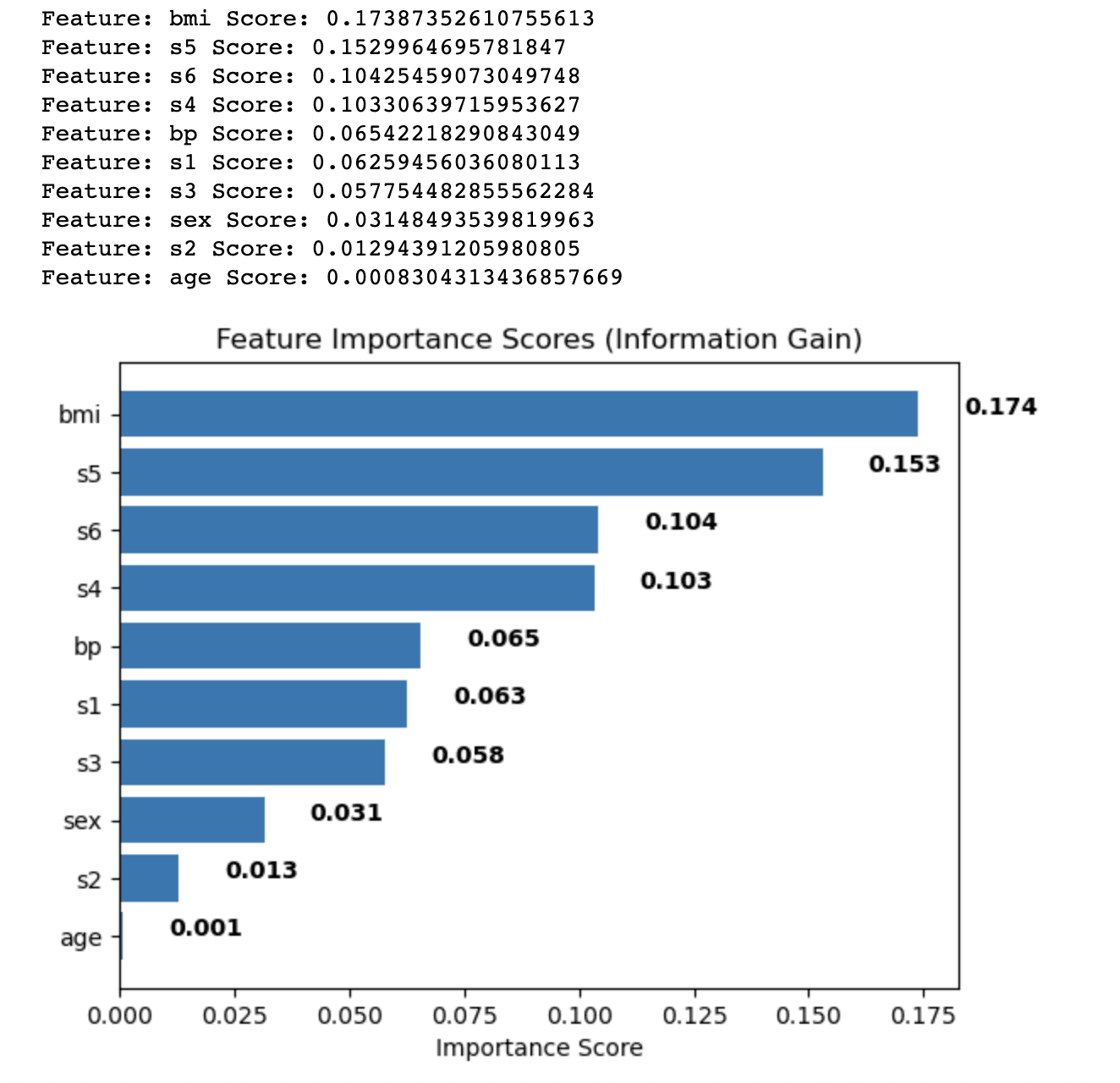
La salida muestra los puntajes de importancia de las características calculados utilizando el método de Ganancia de Información para cada característica en el conjunto de datos de diabetes. Las características se ordenan en orden descendente en función de sus puntajes, que indican su importancia relativa en la predicción de la variable objetivo.
Los resultados son los siguientes:
- El índice de masa corporal (bmi) tiene el puntaje de importancia más alto (0.174), lo que indica que tiene la influencia más significativa en la variable objetivo en el conjunto de datos de diabetes.
- La medición del suero 5 (s5) sigue con una puntuación de 0.153, convirtiéndola en la segunda característica más importante.
- Las mediciones del suero 6 (s6), la medición del suero 4 (s4) y la presión arterial (bp) tienen puntajes de importancia moderados, que van desde 0.104 a 0.065.
- Las características restantes, como las mediciones de suero 1, 2 y 3 (s1, s2, s3), sexo y edad, tienen puntajes de importancia relativamente más bajos, lo que indica que contribuyen menos al poder predictivo del modelo.
Al analizar estos puntajes de importancia de las características, puede decidir qué características incluir o excluir de su análisis para mejorar el rendimiento de su modelo de aprendizaje automático. En este caso, podría considerar retener características con puntajes de importancia más altos, como bmi y s5, mientras que potencialmente elimina o investiga más a fondo características con puntajes más bajos, como edad y s2.
Prueba de Chi-cuadrado
La prueba de Chi-cuadrado es una prueba estadística utilizada para evaluar la relación entre dos variables categóricas. Se utiliza en la selección de características para analizar la relación entre una característica categórica y la variable objetivo. Un puntaje de Chi-cuadrado mayor muestra una relación más fuerte entre la característica y el objetivo, lo que indica que la característica es más importante para el trabajo de clasificación.
Aunque la prueba de Chi-cuadrado es un método de selección de características comúnmente utilizado, se utiliza típicamente para datos categóricos, donde las características y las variables objetivo son discretas.
Puntuación de Fisher
El cociente discriminante de Fisher, comúnmente conocido como Puntuación de Fisher, es un enfoque de selección de características que clasifica las características en función de su capacidad para diferenciar varias clases en un conjunto de datos. Puede utilizarse para características continuas en un problema de clasificación.
La puntuación de Fisher se calcula como la relación entre la varianza entre clases y la varianza dentro de clases. Una puntuación de Fisher más alta implica que la característica es más discriminativa y valiosa para la clasificación.
Para utilizar la Puntuación de Fisher para la selección de características, calcule una puntuación para cada característica continua y clasifíquelas según sus puntuaciones. El modelo considera que las características con una puntuación de Fisher más alta son más importantes.
Ratio de Valores Faltantes
El Ratio de Valores Faltantes es un método de selección de características sencillo que toma decisiones en función del número de valores faltantes en una característica.
Las características que tienen una proporción significativa de valores faltantes pueden ser poco informativas y pueden afectar el rendimiento del modelo. Puede filtrar características con demasiados valores faltantes especificando un umbral para el ratio de valores faltantes aceptable.
Para utilizar el Ratio de Valores Faltantes para la selección de características, siga estos pasos:
- Calcule el ratio de valores faltantes para cada característica dividiendo el número de valores faltantes por el número total de instancias en el conjunto de datos.
- Establezca un umbral para el ratio de valores faltantes aceptable (por ejemplo, 0,8, lo que significa que una característica debe tener como máximo el 80% de sus valores faltantes para ser considerada).
- Filtre las características que tienen un ratio de valores faltantes por encima del umbral.
1.2 Enfoque basado en envoltura
Los enfoques de selección de características basados en envoltura incluyen la evaluación de la importancia de las características utilizando un algoritmo de aprendizaje automático específico. Buscan el mejor subconjunto de características experimentando con diversas combinaciones de características y evaluando su rendimiento con el método seleccionado.
Debido a la enorme cantidad de subconjuntos de características disponibles, los enfoques basados en envoltura pueden ser computacionalmente costosos, especialmente cuando se trabaja con conjuntos de datos de alta dimensionalidad.
Sin embargo, a menudo superan a los enfoques basados en filtro porque consideran la relación entre las características y el algoritmo de aprendizaje.
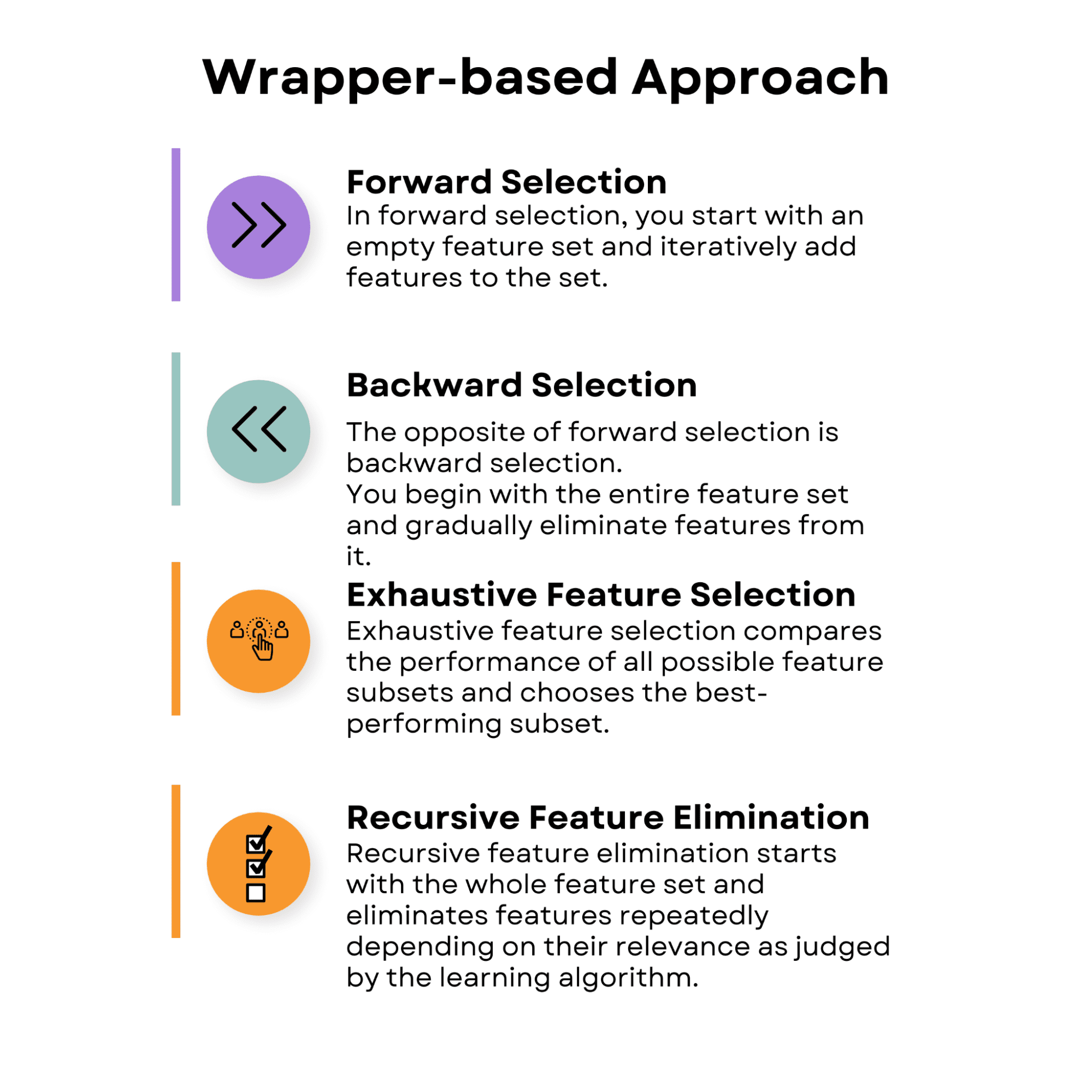
Selección hacia adelante
En la selección hacia adelante, se comienza con un conjunto de características vacío y se agregan características al conjunto de manera iterativa. En cada paso, se evalúa el rendimiento del modelo con el conjunto de características actual y la característica adicional. La característica que resulta en la mejor mejora de rendimiento se agrega al conjunto.
El proceso continúa hasta que no se observa una mejora significativa en el rendimiento, o se alcanza un número predeterminado de características. El siguiente código demuestra la aplicación de la selección hacia adelante, una técnica de selección de características supervisada basada en envoltura. El ejemplo utiliza el conjunto de datos de cáncer de mama de la biblioteca sklearn. El conjunto de datos de cáncer de mama, también conocido como el conjunto de datos de diagnóstico de cáncer de mama de Wisconsin (WDBC), es un conjunto de datos preconstruido comúnmente utilizado para la clasificación. Aquí, el objetivo principal es construir modelos predictivos para diagnosticar el cáncer de mama como maligno (canceroso) o benigno (no canceroso). Para nuestro modelo, seleccionaremos diferentes números de características para ver cómo cambia el rendimiento, pero primero, carguemos las bibliotecas, el conjunto de datos y las variables.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# Cargar el conjunto de datos de cáncer de mama
datos = load_breast_cancer()
# Dividir el conjunto de datos en características y objetivo
X = datos.data
y = datos.targetEl objetivo del código es identificar un subconjunto óptimo de características para un modelo de regresión logística utilizando la selección hacia adelante. Esta técnica comienza con un conjunto vacío de características y agrega iterativamente las características que mejoran el rendimiento del modelo en función de una métrica de evaluación especificada. En este caso, la métrica utilizada es la precisión. La siguiente parte del código emplea SequentialFeatureSelector de la biblioteca mlxtend para realizar selección hacia adelante. Se configura con un modelo de regresión logística, el número deseado de características y validación cruzada de 5 veces. El objeto de selección hacia adelante se ajusta al conjunto de datos de entrenamiento y se imprimen las características seleccionadas.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# Cargar el conjunto de datos de cáncer de mama
datos = load_breast_cancer()
# Dividir el conjunto de datos en características y objetivo
X = datos.data
y = datos.target
# Dividir el conjunto de datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Definir el modelo de regresión logística
modelo = LogisticRegression()
# Definir el objeto de selección hacia adelante
sfs = SFS(modelo,
k_features=5,
forward=True,
floating=False,
scoring='accuracy',
cv=5)
# Realizar selección hacia adelante en el conjunto de datos de entrenamiento
sfs.fit(X_train, y_train)Además, necesitamos evaluar el rendimiento de las características seleccionadas en el conjunto de prueba y visualizar el rendimiento del modelo con diferentes subconjuntos de características en un gráfico de líneas. El gráfico mostrará la precisión validada cruzada como una función del número de características, proporcionando información sobre el compromiso entre la complejidad del modelo y el rendimiento predictivo. Al analizar la salida y el gráfico, puede determinar el número óptimo de características para incluir en su modelo, mejorando en última instancia su rendimiento y reduciendo el sobreajuste.
# Imprimir las características seleccionadas
print('Características seleccionadas:', sfs.k_feature_names_)
# Evaluar el rendimiento de las características seleccionadas en el conjunto de prueba
precision = sfs.k_score_
print('Precisión:', precision)
# Graficar el rendimiento del modelo con diferentes subconjuntos de características
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df['avg_score'] = sfs_df['avg_score'].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind='line', y='avg_score', ax=ax)
ax.set_xlabel('Número de características')
ax.set_ylabel('Precisión')
ax.set_title('Rendimiento de la selección hacia adelante')
plt.show()Aquí está todo el código.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# Cargar el conjunto de datos de cáncer de mama
datos = load_breast_cancer()
# Dividir el conjunto de datos en características y objetivo
X = datos.data
y = datos.target
# Dividir el conjunto de datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Definir el modelo de regresión logística
modelo = LogisticRegression()
# Definir el objeto de selección hacia adelante
sfs = SFS(modelo, k_features=5, forward=True, floating=False, scoring="accuracy", cv=5)
# Realizar selección hacia adelante en el conjunto de datos de entrenamiento
sfs.fit(X_train, y_train)
# Imprimir las características seleccionadas
print("Características seleccionadas:", sfs.k_feature_names_)
# Evaluar el rendimiento de las características seleccionadas en el conjunto de prueba
precision = sfs.k_score_
print("Precisión:", precision)
# Graficar el rendimiento del modelo con diferentes subconjuntos de características
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df["avg_score"] = sfs_df["avg_score"].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind="line", y="avg_score", ax=ax)
ax.set_xlabel("Número de características")
ax.set_ylabel("Precisión")
ax.set_title("Rendimiento de la selección hacia adelante")
plt.show()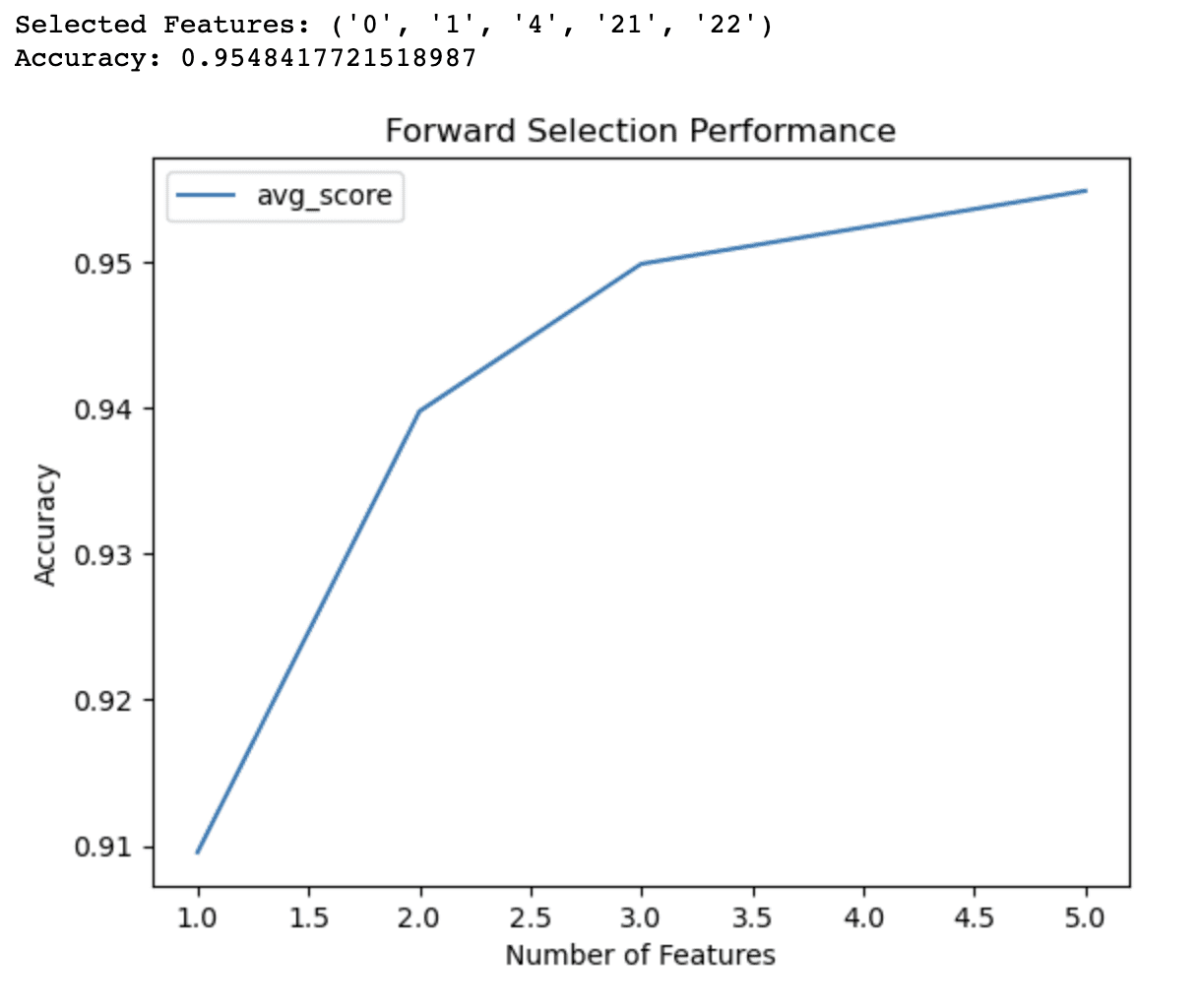
La salida del código de selección hacia adelante demuestra que el algoritmo ha identificado un subconjunto de 5 características que producen la mejor precisión (0,9548) para el modelo de regresión logística en el conjunto de datos del cáncer de mama. Estas características seleccionadas son identificadas por sus índices: 0, 1, 4, 21 y 22.
El gráfico de línea proporciona información adicional sobre el rendimiento del modelo con diferentes números de características. Muestra que:
- Con solo 1 característica, el modelo logra una precisión de alrededor del 91%.
- Agregando una segunda característica, la precisión aumenta al 94%.
- Con 3 características, la precisión mejora aún más a un 95%.
- Incluir 4 características eleva la precisión ligeramente por encima del 95%.
Más allá de las 4 características, las mejoras en la precisión se vuelven menos significativas. Esta información puede ayudarlo a tomar decisiones informadas sobre los compromisos entre la complejidad del modelo y el rendimiento predictivo. Basándose en estos resultados, podría decidir utilizar solo 3 o 4 características en su modelo para equilibrar precisión y simplicidad.
Selección hacia atrás
Lo opuesto a la selección hacia adelante es la selección hacia atrás. Comienzas con todo el conjunto de características y gradualmente eliminas características de él.
En cada fase, mides el rendimiento del modelo con el conjunto de características actuales menos la característica a eliminar.
Se elimina la característica que causa la menor cantidad de reducción de rendimiento del conjunto.
El procedimiento se repite hasta que no haya un aumento sustancial en el rendimiento o se alcance un número preestablecido de características.
La selección hacia atrás y hacia adelante se clasifican como una selección de características secuenciales; puede aprender más aquí.
Selección exhaustiva de características
La selección exhaustiva de características compara el rendimiento de todos los posibles subconjuntos de características y elige el subconjunto con el mejor rendimiento. Este enfoque es computacionalmente exigente, especialmente para conjuntos de datos grandes, pero garantiza el mejor subconjunto de características.
Eliminación recursiva de características
La eliminación recursiva de características comienza con todo el conjunto de características y elimina características repetidamente dependiendo de su relevancia según el algoritmo de aprendizaje. Se elimina la característica menos importante en cada paso y se vuelve a entrenar el modelo. El método se repite hasta que se logra un número predeterminado de características.
1.3 Enfoque incorporado
Los enfoques de selección de características incorporados incluyen el proceso de selección de características como parte del algoritmo de aprendizaje.
Esto implica que durante la fase de entrenamiento, el algoritmo de aprendizaje no solo optimiza los parámetros del modelo, sino que también elige las características más importantes. Los métodos incorporados pueden ser más efectivos que los métodos de envoltura ya que no requieren un procedimiento de selección de características externo.
 Imagen por autor
Imagen por autor
Regularización
La regularización es un método que agrega un término de penalización a la función de pérdida para evitar el sobreajuste en los modelos de aprendizaje automático.
Los métodos de regularización, como el lazo (regularización L1) y la cresta (regularización L2), se pueden utilizar junto con la selección de características para disminuir los coeficientes de las características menos significativas hacia cero, eligiendo así un subconjunto de características más relevantes.
Importancia de Random Forest
Random Forest es un enfoque de aprendizaje de conjuntos que combina las predicciones de varios árboles de decisión. Random Forest calcula una puntuación de significancia de características para cada característica como parte del proceso de construcción de árboles, que se puede utilizar para ordenar las características según su relevancia. El modelo considera que las características con calificaciones de significancia más altas son más significativas.
Si desea obtener más información sobre Random Forest, aquí hay un artículo “Algoritmo de árbol de decisiones y bosque aleatorio”, que también explica el algoritmo de árbol de decisiones.
El siguiente ejemplo utiliza el conjunto de datos Covertype, que incluye información sobre diferentes tipos de cobertura forestal.
El objetivo del conjunto de datos Covertype es predecir el tipo de cobertura forestal (la especie de árbol dominante) dentro del Bosque Nacional Roosevelt del norte de Colorado.
El objetivo principal del siguiente código es determinar la importancia de las características utilizando un clasificador de bosque aleatorio. Al evaluar la contribución de cada característica al rendimiento de clasificación general, este método ayuda a identificar las características más relevantes para construir un modelo predictivo.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Cargar el conjunto de datos Covertype
datos = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None)
# Asignar nombres de columna
cols = ["Elevación", "Aspecto", "Inclinación", "Distancia horizontal al agua",
"Distancia vertical al agua", "Distancia horizontal a las carreteras",
"Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm",
"Distancia horizontal a los puntos de fuego"] + ["Área salvaje_"+str(i) for i in range(1,5)] + ["Tipo de suelo_"+str(i) for i in range(1,41)] + ["Tipo de cobertura"]
datos.columns = colsLuego, creamos un objeto RandomForestClassifier y lo ajustamos a los datos de entrenamiento. Luego extrae las importancias de las características del modelo entrenado y las ordena en orden descendente. Se seleccionan las 10 características principales en función de sus puntajes de importancia y se muestran en un ranking.
# Dividir el conjunto de datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Crear un objeto clasificador de bosques aleatorios
rfc = RandomForestClassifier(n_estimators=100, random_state=42)
# Ajustar el modelo a los datos de entrenamiento
rfc.fit(X_train, y_train)
# Obtener las importancias de las características del modelo entrenado
importances = rfc.feature_importances_
# Ordenar las importancias de las características en orden descendente
indices = np.argsort(importances)[::-1]
# Seleccionar las 10 características principales
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices]
# Imprimir las 10 mejores clasificaciones de características
print("Top 10 clasificaciones de características:")
for f in range(num_features): # Use num_features instead of 10
print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")Además, el código visualiza las 10 características principales utilizando un gráfico de barras horizontales.
# Graficar las 10 características principales en un gráfico de barras horizontales
plt.barh(range(num_features), top_importances, align='center')
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Importancia de la característica")
plt.ylabel("Característica")
plt.show()Esta visualización permite una fácil comparación de los puntajes de importancia y ayuda a tomar decisiones informadas sobre qué características incluir o excluir de su análisis.
Al examinar la salida y el gráfico, puede seleccionar las características más relevantes para su modelo predictivo, lo que puede ayudar a mejorar su rendimiento, reducir el sobreajuste y acelerar los tiempos de entrenamiento.
Aquí está el código completo.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Cargar el conjunto de datos Covertype
data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz",
header=None,
)
# Asignar nombres de columnas
cols = (
[
"Elevación",
"Aspecto",
"Inclinación",
"Distancia_Horizontal_Hidrología",
"Distancia_Vertical_Hidrología",
"Distancia_Horizontal_Carreteras",
"Hillshade_9am",
"Hillshade_Noon",
"Hillshade_3pm",
"Distancia_Horizontal_Puntos_Fuego",
]
+ ["Área_Silvestre_" + str(i) for i in range(1, 5)]
+ ["Tipo_Suelo_" + str(i) for i in range(1, 41)]
+ ["Tipo_Cobertura"]
)
data.columns = cols
# Dividir el conjunto de datos en características y objetivo
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# Dividir el conjunto de datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Crear un objeto clasificador de bosques aleatorios
rfc = RandomForestClassifier(n_estimators=100, random_state=42)
# Ajustar el modelo a los datos de entrenamiento
rfc.fit(X_train, y_train)
# Obtener las importancias de las características del modelo entrenado
importances = rfc.feature_importances_
# Ordenar las importancias de las características en orden descendente
indices = np.argsort(importances)[::-1]
# Seleccionar las 10 características principales
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices]
# Imprimir las 10 mejores clasificaciones de características
print("Top 10 clasificaciones de características:")
for f in range(num_features): # Use num_features instead of 10
print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
# Graficar las 10 características principales en un gráfico de barras horizontales
plt.barh(range(num_features), top_importances, align="center")
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Importancia de la característica")
plt.ylabel("Característica")
plt.show()Aquí está la salida.
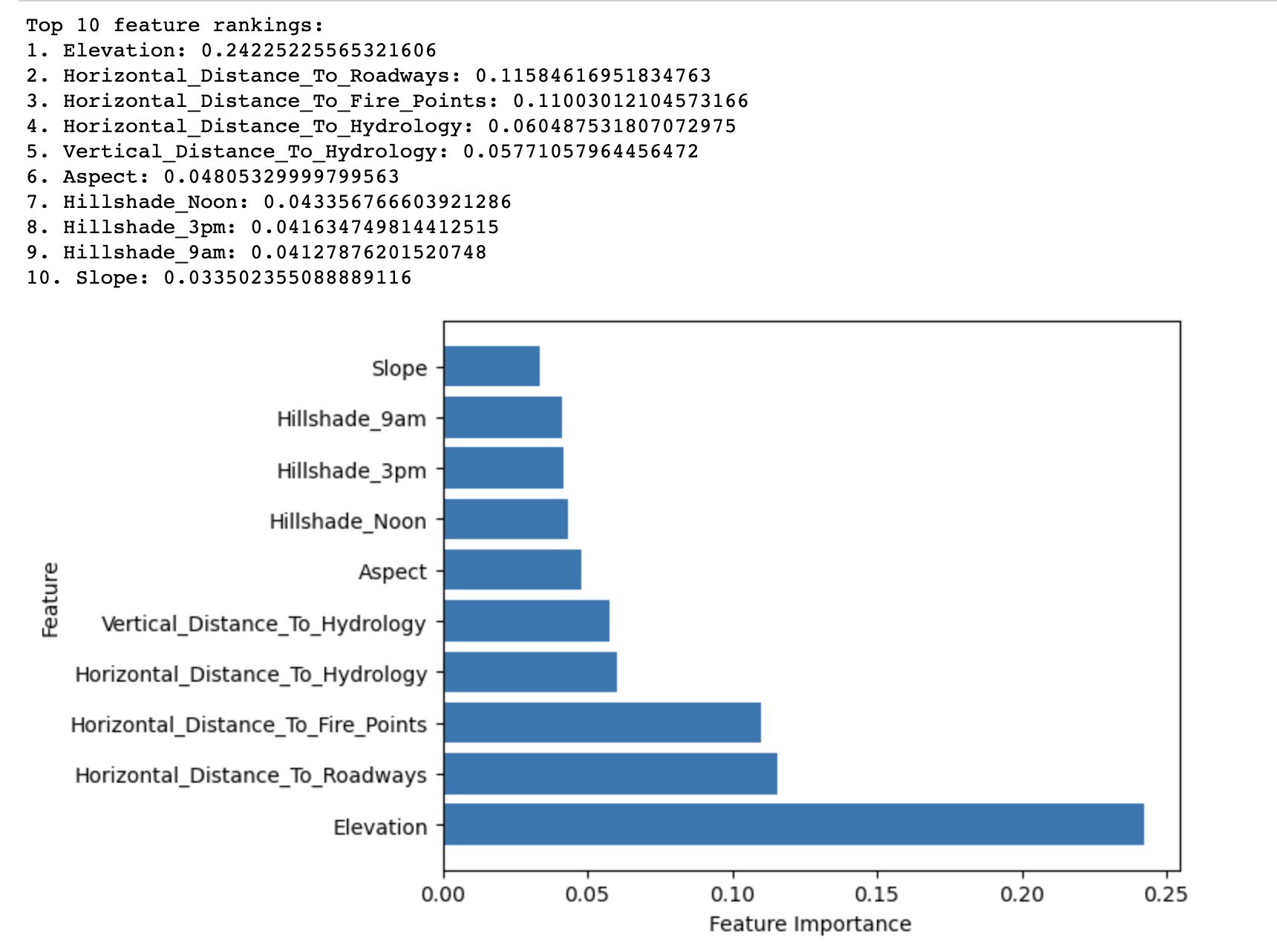
La salida del método de Importancia de Random Forest muestra las 10 características principales clasificadas por su importancia en la predicción del tipo de cobertura forestal en el conjunto de datos Covertype.
Revela que la elevación tiene la puntuación de importancia más alta (0.2423) entre todas las características en la predicción del tipo de cobertura forestal. Esto sugiere que la elevación juega un papel crítico en la determinación de las especies de árboles dominantes en el Bosque Nacional Roosevelt.
Otras características con puntuaciones de importancia relativamente altas incluyen Horizontal_Distance_To_Roadways (0.1158) y Horizontal_Distance_To_Fire_Points (0.1100). Esto indica que la proximidad a las carreteras y los puntos de ignición de incendios también afecta significativamente los tipos de cobertura forestal.
Las características restantes en la lista de las 10 principales tienen puntuaciones de importancia relativamente más bajas, pero aún contribuyen al rendimiento predictivo general del modelo. Estas características se relacionan principalmente con factores hidrológicos, pendiente, aspecto e índices de sombra de colina.
En resumen, los resultados destacan los factores más importantes que afectan la distribución de los tipos de cobertura forestal en el Bosque Nacional Roosevelt, lo que se puede utilizar para construir un modelo predictivo más efectivo y eficiente para la clasificación del tipo de cobertura forestal.
2. Técnicas de selección de características no supervisadas
Cuando no hay una variable objetivo disponible, se pueden utilizar enfoques de selección de características no supervisados para reducir la dimensionalidad del conjunto de datos manteniendo su estructura subyacente. Estos métodos a menudo incluyen cambiar el espacio de características inicial en un nuevo espacio de dimensionalidad inferior en el que las características cambiadas capturan la mayoría de la variación en los datos.
 Imagen de Autor
Imagen de Autor
2.1 Análisis de componentes principales (PCA)
PCA es un método de reducción de dimensionalidad lineal que convierte el espacio de características original en un nuevo espacio ortogonal definido por componentes principales. Estos componentes son combinaciones lineales de las características originales elegidas para capturar el nivel más alto de varianza en los datos.
PCA se puede usar para seleccionar los principales k componentes principales que representan la mayoría de la variación, reduciendo así la dimensionalidad del conjunto de datos.
Para mostrar cómo funciona esto en la práctica, trabajaremos con el conjunto de datos Wine. Este es un conjunto de datos ampliamente utilizado para tareas de clasificación y selección de características en aprendizaje automático y consta de 178 muestras, cada una representando un vino diferente originario de tres cultivos diferentes en la misma región de Italia.
El objetivo de trabajar con el conjunto de datos Wine suele ser construir un modelo predictivo que pueda clasificar con precisión una muestra de vino en uno de los tres cultivares en función de sus propiedades químicas.
El siguiente código demuestra la aplicación del Análisis de Componentes Principales (PCA), una técnica de selección de características no supervisada, en el conjunto de datos Wine.
Estos componentes (componentes principales) capturan la mayor varianza en los datos al minimizar la pérdida de información.
El código comienza cargando el conjunto de datos Wine, que consta de 13 características que describen las propiedades químicas de diferentes muestras de vino.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Cargar el conjunto de datos Wine
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_namesLuego, estas características se estandarizan utilizando StandardScaler para asegurarse de que PCA no se vea afectado por las diferentes escalas de las características de entrada.
# Estandarizar las características
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)A continuación, se realiza PCA en los datos estandarizados utilizando la clase PCA del módulo sklearn.decomposition.
# Realizar PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)Se calcula la proporción de la varianza total en los datos que explica la relación de varianza explicada para cada componente principal.
# Calcular la relación de varianza explicada
explained_variance_ratio = pca.explained_variance_ratio_Finalmente, se generan dos gráficos para visualizar la relación de varianza explicada y la varianza explicada acumulada por los componentes principales.
El primer gráfico muestra la relación de varianza explicada para cada componente principal individual, mientras que el segundo gráfico ilustra cómo aumenta la varianza explicada acumulada a medida que se incluyen más componentes principales.
Estos gráficos ayudan a determinar el número óptimo de componentes principales a utilizar en el modelo, equilibrando el compromiso entre la reducción de la dimensionalidad y la retención de la información.
# Crear una cuadrícula de subtramas 2x1
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# Graficar la relación de varianza explicada en la primera subtrama
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel('Componente Principal')
ax1.set_ylabel('Relación de Varianza Explicada')
ax1.set_title('Relación de Varianza Explicada por Componente Principal')
# Calcular la varianza explicada acumulada
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
# Graficar la varianza explicada acumulada en la segunda subtrama
ax2.plot(range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker='o')
ax2.set_xlabel('Número de Componentes Principales')
ax2.set_ylabel('Variance Explicada Acumulada')
ax2.set_title('Variance Explicada Acumulada por Componentes Principales')
# Mostrar la figura
plt.tight_layout()
plt.show()Vamos a ver todo el código.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Cargar el dataset Wine
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
# Estandarizar las características
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Realizar PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# Calcular la proporción de varianza explicada
explained_variance_ratio = pca.explained_variance_ratio_
# Crear una cuadrícula de subtramas 2x1
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# Graficar la proporción de varianza explicada en la primera subtrama
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel("Componente Principal")
ax1.set_ylabel("Proporción de Varianza Explicada")
ax1.set_title("Proporción de Varianza Explicada por Componente Principal")
# Calcular la varianza explicada acumulada
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
# Graficar la varianza explicada acumulada en la segunda subtrama
ax2.plot(
range(1, len(cumulative_explained_variance) + 1),
cumulative_explained_variance,
marker="o",
)
ax2.set_xlabel("Número de Componentes Principales")
ax2.set_ylabel("Varianza Explicada Acumulada")
ax2.set_title("Varianza Explicada Acumulada por Componentes Principales")
# Mostrar la figura
plt.tight_layout()
plt.show()Aquí está la salida.
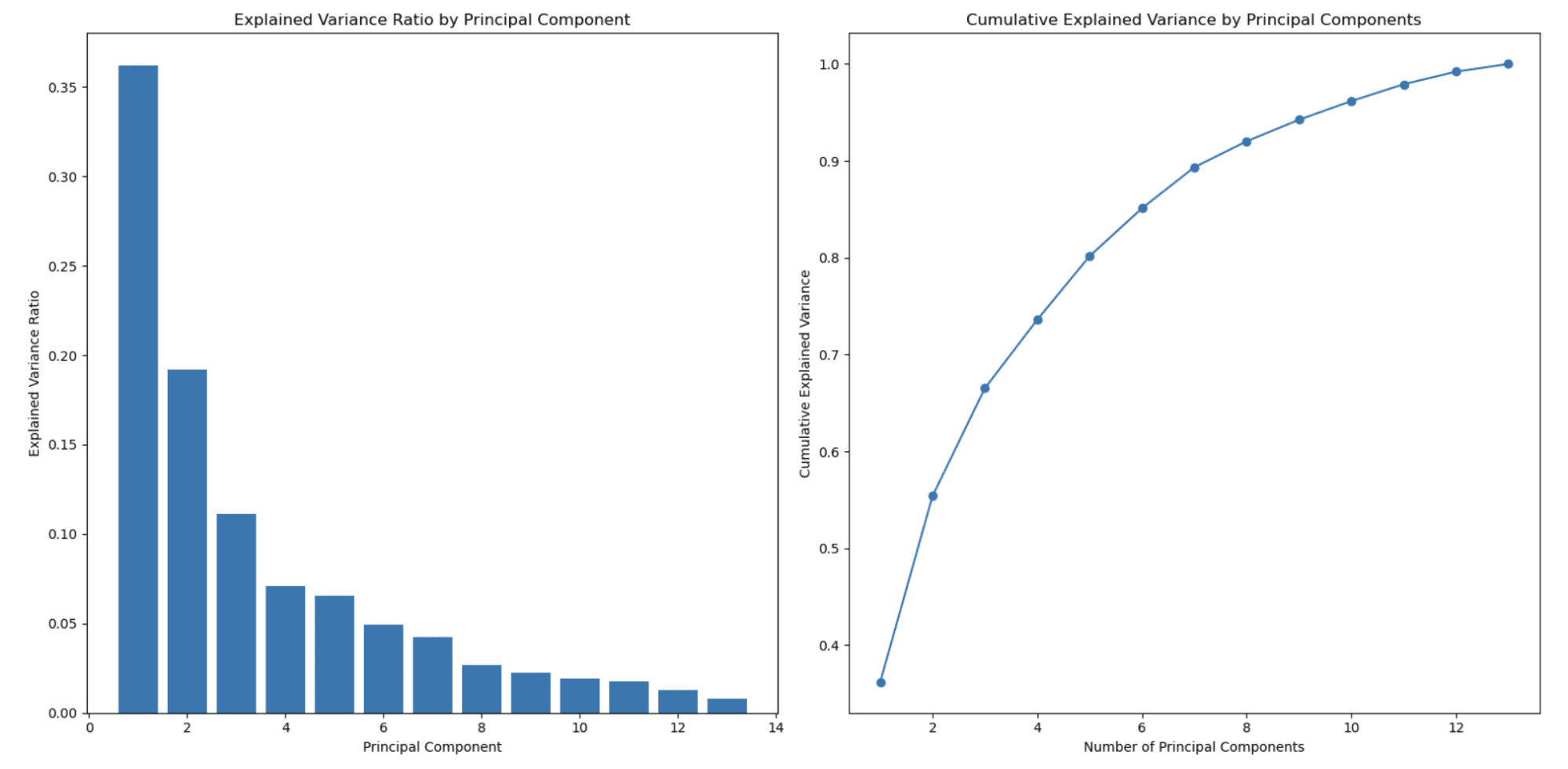
El gráfico a la izquierda muestra que la proporción de varianza explicada disminuye a medida que aumenta el número de componentes principales. Este es un comportamiento típico observado en PCA debido a que los componentes principales se ordenan por la cantidad de varianza que explican.
El primer componente principal (característica) captura la varianza más alta, el segundo componente principal captura la segunda cantidad más alta, y así sucesivamente. Como resultado, la proporción de varianza explicada disminuye con cada componente principal subsiguiente.
Esta es una de las principales razones por las que se utiliza PCA para la reducción de dimensionalidad.
El segundo gráfico a la derecha muestra la varianza explicada acumulada y ayuda a determinar cuántos componentes principales (características) seleccionar para representar el porcentaje de sus datos. El eje x representa el número de componentes principales y el eje y muestra la varianza explicada acumulada. A medida que se mueve a lo largo del eje x, se puede ver cuánta de la varianza total se retiene al incluir tantos componentes principales.
En este ejemplo, se puede ver que la selección de alrededor de 3 o 4 componentes principales ya captura más del 80% de la varianza total, y alrededor de 8 componentes principales capturan más del 90% de la varianza total.
Se puede elegir el número de componentes principales en función del compromiso deseado entre la reducción de dimensionalidad y la varianza que se quiere retener.
En este ejemplo, usamos Sci-kit para aprender a aplicar PCA, y aquí puede encontrar el documento oficial.
2.2 Análisis de Componentes Independientes (ICA)
ICA es un método para dividir una señal multidimensional en sus componentes.
En el contexto de la selección de características, ICA se puede utilizar para convertir el espacio de características original en un nuevo espacio caracterizado por componentes estadísticamente independientes. Puede disminuir la dimensionalidad del conjunto de datos manteniendo la estructura subyacente seleccionando los k componentes independientes principales.
2.3 Factorización de Matrices No Negativas (NMF)
La factorización de matrices no negativas (NMF) es un enfoque de reducción de dimensionalidad que aproxima una matriz de datos no negativa como el producto de dos matrices no negativas de menor dimensión.
NMF se puede utilizar en el contexto de la selección de características para extraer un nuevo conjunto de características básicas que capturen la estructura importante de los datos originales. Puede minimizar la dimensionalidad del conjunto de datos manteniendo la limitación de no negatividad seleccionando las k características básicas principales.
2.4 Incrustación de Vecinos Estocásticos Distribuidos en t (t-SNE)
t-SNE es un método de reducción de dimensionalidad no lineal que intenta preservar la estructura del conjunto de datos mediante la reducción de la diferencia entre las distribuciones de probabilidad de pares en ubicaciones de alta y baja dimensión.
t-SNE se puede aplicar en la selección de características para proyectar el espacio de características original en un espacio de menor dimensión que mantenga la estructura de los datos, lo que permite una mejor visualización y evaluación.
Puedes encontrar más información sobre los algoritmos de aprendizaje no supervisado y t-SNE aquí “Algoritmos de aprendizaje no supervisado”.
2.5 Autoencoder
Un autoencoder, un tipo de red neuronal artificial, aprende a codificar los datos de entrada en una representación de menor dimensión y luego a decodificarlos de vuelta a la versión original. La representación de menor dimensión del autoencoder se puede usar para producir otro conjunto de características que capturan la estructura subyacente de los datos originales.
Últimas palabras
En conclusión, la selección de características es vital en el aprendizaje automático. Ayuda a reducir la dimensionalidad de los datos, minimizar el riesgo de sobreajuste y mejorar el rendimiento general del modelo. La elección del método adecuado de selección de características depende del problema específico, el conjunto de datos y los requisitos de modelado.
Este artículo cubrió una amplia gama de técnicas de selección de características, incluidos métodos supervisados y no supervisados.
Las técnicas supervisadas, como los enfoques basados en filtros, basados en envolturas y embebidos, utilizan la relación entre las características y la variable objetivo para identificar las características más importantes.
Las técnicas no supervisadas, como PCA, ICA, NMF, t-SNE y autoencoders, se centran en la estructura intrínseca de los datos para reducir la dimensionalidad sin considerar la variable objetivo.
Cuando selecciones el método adecuado de selección de características para tu modelo, es vital considerar las características de tus datos, las suposiciones subyacentes de cada técnica y la complejidad computacional involucrada.
Al seleccionar y aplicar cuidadosamente la técnica adecuada de selección de características, puedes mejorar significativamente el rendimiento, lo que lleva a mejores ideas y toma de decisiones. Nate Rosidi es un científico de datos y estratega de productos. También es profesor adjunto que enseña análisis y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevistas reales de las principales empresas. Conéctate con él en Twitter: StrataScratch o LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






