Cómo agregar conocimiento específico del dominio a un LLM basado en sus datos
Adding domain-specific knowledge to a data-based LLM
Convierte tu LLM en un experto en el campo
Introducción
En los últimos meses, los Modelos de Lenguaje de Gran Escala (LLMs, por sus siglas en inglés) han cambiado profundamente la forma en que trabajamos e interactuamos con la tecnología, y se han demostrado ser herramientas útiles en varios ámbitos, sirviendo como asistentes de escritura, generadores de código e incluso colaboradores creativos. Su capacidad para comprender el contexto, generar texto similar al humano y realizar una amplia gama de tareas relacionadas con el lenguaje los ha impulsado al frente de la investigación en inteligencia artificial.
Aunque los LLMs son excelentes en la generación de texto genérico, a menudo tienen dificultades cuando se enfrentan a dominios altamente especializados que requieren un conocimiento preciso y una comprensión matizada. Cuando se utilizan para tareas específicas de un dominio, estos modelos pueden mostrar limitaciones o, en algunos casos, incluso producir respuestas erróneas o alucinatorias. Esto resalta la necesidad de incorporar conocimiento de dominio en los LLMs, permitiéndoles navegar mejor por el jerga compleja específica de la industria, mostrar una comprensión más matizada del contexto y limitar el riesgo de producir información falsa.
En este artículo, exploraremos una de varias estrategias y técnicas para infundir conocimiento de dominio en los LLMs, permitiéndoles desempeñarse al máximo dentro de contextos profesionales específicos mediante la incorporación de fragmentos de documentación en un LLM como contexto al inyectar la consulta.
Este método funciona con cualquier tipo de documentación y solo utiliza tecnologías seguras de código abierto que se ejecutarán localmente en tu computadora, sin necesidad de acceder a Internet. Gracias a esto, pude utilizarlo en datos personales y confidenciales a los que no deseaba que los sitios web de terceros tuvieran acceso.
- Pregunta y respuesta visual modular a través de generación de código
- La velocidad de diseño toma la delantera Trek Bicycle compite en el Tour de Francia con bicicletas desarrolladas utilizando las GPUs de NVIDIA
- Las imágenes de la cámara del salpicadero revelan dónde está desplegada la policía.
Principio
Veamos cómo funciona:
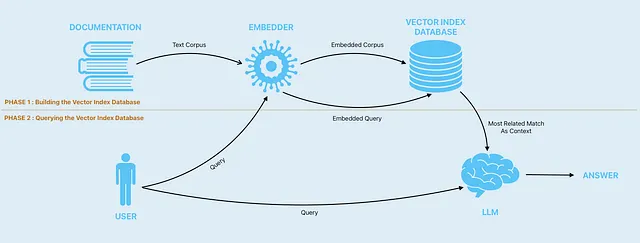
El primer paso es tomar nuestra documentación y construir una base de datos de índices vectoriales basada en nuestra documentación. Las bases de datos vectoriales son un tipo de base de datos diseñada para almacenar y consultar vectores de alta dimensión de manera eficiente. Estas bases de datos permiten una búsqueda de similitud y semántica rápida al tiempo que permiten a los usuarios encontrar vectores que…
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- El Ejército de los Estados Unidos pone a prueba la Inteligencia Artificial Generativa
- ¿Qué tan seguro es el aire de tu oficina? Hay una forma de averiguarlo
- Operaciones de Machine Learning (MLOps) con Azure Machine Learning
- Del Texto más allá de las Palabras
- Visualizando la Validación Cruzada de Sklearn K-Fold, Mezcla y División, y División de Series Temporales
- Abordando el sesgo en los sistemas de reconocimiento facial Un enfoque novedoso
- Aquí están las herramientas de IA que uso junto con mis habilidades para ganar $10,000 al mes – Sin tonterías






