Accediendo a tus datos personales
Acceso a datos personales
Los datos extensos y a menudo sorprendentes que las empresas tienen sobre ti, listos y esperando para ser analizados

Las leyes de privacidad de datos están apareciendo en países de todo el mundo y están creando una oportunidad única para que aprendas cómo los demás te ven y, al mismo tiempo, obtengas información sobre ti mismo. La mayoría de las leyes son similares al Reglamento General de Protección de Datos de la Unión Europea, comúnmente conocido como “GDPR”. Incluye disposiciones que requieren que las organizaciones te informen sobre el tipo de datos personales que almacenan sobre ti, por qué los almacenan, cómo los utilizan y durante cuánto tiempo los almacenan.
Pero las leyes también incluyen un requisito a menudo pasado por alto conocido como portabilidad de datos. La portabilidad de datos requiere que las organizaciones te den una copia legible por máquina de los datos que actualmente están almacenando sobre ti a pedido tuyo. En el GDPR, este derecho está definido en el Artículo 15, “Derecho de acceso del interesado a los datos”. Los datos que las organizaciones tienen a menudo incluyen un conjunto variado de características y están limpios, lo que los hace ideales para varias tareas de análisis, modelado y visualización de datos.
En este artículo, comparto mi experiencia de solicitar mis datos a algunas de las empresas con las que interactúo habitualmente. Incluyo consejos para solicitar tus datos, así como ideas para usar tus datos en ciencia de datos y para obtener información personal.
¿Crees que tienes un buen conocimiento de tus gustos musicales? Yo pensaba que tenía gustos musicales amplios y variados. Sin embargo, según Apple, soy más bien un amante del rock duro.
- ¿Te sientes arriesgado al entrenar tu modelo de lenguaje con datos restringidos? Conoce a SILO Un nuevo modelo de lenguaje que gestiona los compromisos entre riesgo y rendimiento durante la inferencia.
- Desmitificando el Aprendizaje Profundo Una Introducción de un Estudiante a las Redes Neuronales
- El caso en contra de la regulación de la IA no tiene sentido
¿Quieres mejorar tus habilidades de mapeo de datos geográficos? Estas fuentes de datos proporcionan una cantidad espectacular de datos geocodificados con los que trabajar.
¿Te gustaría poner a prueba tus habilidades de modelado de series temporales? Hay múltiples conjuntos de datos que incluyen observaciones de series temporales detalladas.
¿La mejor noticia de todas? Estos son tus datos. No se necesita licencia ni permisos.
Asegúrate el cinturón de seguridad: la variedad de datos que recibirás es amplia. Los tipos de análisis y modelado que puedes hacer son complejos. Y las ideas que obtendrás sobre ti mismo y cómo te ven los demás son fascinantes.
Para centrarnos en las ideas obtenidas a partir de los datos y en aras de la brevedad, no incluyo código en este artículo. A todo el mundo le gusta el código, así que aquí tienes un enlace a un repositorio con varios cuadernos que utilicé para analizar mis datos.
Obteniendo los Datos
Si haces una lista de las organizaciones que tienen datos sobre ti, rápidamente te darás cuenta de que la lista es larga. Empresas de redes sociales, minoristas en línea, operadores de telefonía celular, proveedores de servicios de internet, servicios de automatización y seguridad del hogar y proveedores de entretenimiento en streaming son solo algunas de las categorías de organizaciones que almacenan datos sobre ti. Solicitar tus datos a todos estos grupos puede llevar bastante tiempo.
Para que mi análisis sea manejable, limité mis solicitudes de datos a Facebook, Google, Microsoft, Apple, Amazon y mi operador celular, Verizon. Aquí tienes una tabla que resume mi experiencia con el proceso de solicitud y respuesta de los datos:

Y aquí están los enlaces que utilicé para solicitar mis datos junto con información sobre cualquier documentación de datos proporcionada por los proveedores:
Utilizo un Apple Watch para realizar un seguimiento de los datos de salud y estado físico. Esos datos se acceden por separado de todos los demás datos de Apple que solicitas desde el sitio web general de Apple. Debido a esto, muestro dos entradas de Apple separadas en las tablas anteriores y discuto los datos de Apple en dos temas a continuación.
La cantidad y el tipo de datos que recibes dependerán de cómo interactúes con una empresa en particular. Por ejemplo, utilizo las redes sociales con poca frecuencia. Por lo tanto, no es sorprendente la cantidad bastante modesta de datos que recibí de Facebook. En contraste, utilizo mucho los productos y servicios de Apple. Obtuve una amplia gama y gran volumen de datos de Apple.
Ten en cuenta que si tienes múltiples identidades con una empresa, deberás solicitar los datos para cada identidad. Por ejemplo, si Google te conoce por una dirección de correo electrónico para tu cuenta de Google Play y una dirección de correo electrónico diferente para tu cuenta de Gmail, deberás hacer una solicitud de datos para cada dirección con el fin de obtener una imagen completa de los datos que Google almacena sobre ti.
En la tabla anterior, muestro los enlaces que utilicé para solicitar datos de mis empresas objetivo. Los enlaces son actuales en el momento de la publicación de este artículo, pero pueden cambiar con el tiempo. En general, puedes encontrar instrucciones para solicitar tus datos en los enlaces “Privacidad”, “Derechos de privacidad” o similares en la página de inicio de una empresa. Esos enlaces suelen aparecer en la parte inferior de la página de inicio.

Por lo general, debes leer la documentación que describe tus derechos de privacidad y buscar el tema “Acceder a tus datos”, “Exportar tus datos”, “Portabilidad de datos” o similar para obtener un enlace a la página real para solicitar tus datos.
Finalmente, el proceso para solicitar tus datos, la rapidez de la respuesta y la calidad de la documentación que recibes explicando los datos varían mucho de una empresa a otra. Sé paciente y persevera. Serás recompensado con una gran cantidad de datos y conocimientos en poco tiempo.
Mis conocimientos sobre datos
Aquí se presenta una revisión de los archivos de datos que recibí de cada empresa junto con algunas observaciones después de analizar los archivos más interesantes. También señalo algunas oportunidades para realizar análisis y modelización de datos más profundos con los datos de estas empresas.
Mi descarga de Facebook incluía 51 archivos .json, excluyendo los numerosos archivos .json que contenían hilos de mensajes individuales de mi cuenta de Facebook Messenger. Facebook proporciona una documentación de alto nivel para sus archivos en el sitio web de descarga.
Los datos sobre mi actividad de inicio de sesión en Facebook, los dispositivos que utilicé para iniciar sesión, la ubicación geográfica estimada de mis inicios de sesión y datos similares sobre las actividades de mi cuenta aparecen en varios archivos. Nada en estos archivos es particularmente interesante, aunque diré que los datos de ubicación parecían sorprendentemente precisos, dado que a menudo se inferían de mi dirección IP en el momento de la actividad registrada.
Los datos realmente interesantes comenzaron a aparecer en un archivo que rastreaba mi actividad fuera de Facebook en aplicaciones y sitios web. Puedo ver cómo los datos en ese archivo, junto con los datos que Facebook ya tiene de mi perfil de Facebook, pintan un panorama demográfico que resulta en que sea seleccionado como objetivo por anunciantes específicos de Facebook. El archivo fuera de Facebook comienza a darte una idea de cómo funciona el proceso de perfilado y publicidad en Facebook.
Echemos un vistazo al archivo. Se llama:
“/apps_and_websites_off_of_facebook/your_off-facebook_activity.json”
Contiene 1860 registros de acciones que realicé en 441 sitios web diferentes no relacionados con Facebook en los últimos dos años. Aquí tienes una muestra editada de los sitios web y los tipos de acciones que registra:
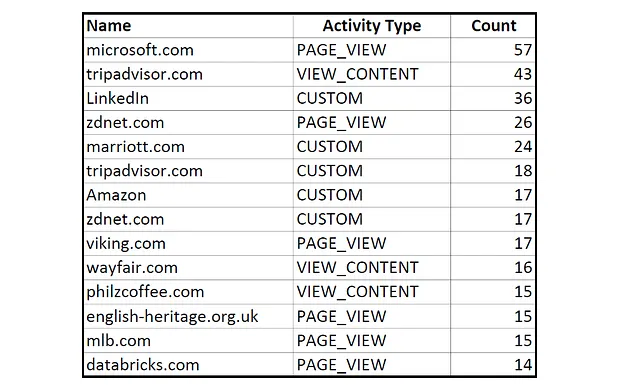
Varios sitios relacionados con la tecnología y los viajes encabezan mi lista de actividad fuera de Facebook. Ahora veamos mi perfil demográfico.
El archivo llamado:
“ads_information/other_categories_used_to_reach_you.json”
contiene una lista de categorías demográficas que Facebook me ha asignado, supongo, en función de los datos de mi perfil de Facebook, mis amigos de Facebook, mi actividad en Facebook y mi actividad fuera de Facebook en aplicaciones y sitios web. Aquí tienes una muestra editada de las categorías demográficas:

La mayoría de las categorías anteriores se basan en mi perfil, mi patrón de uso del dispositivo y mis amigos. Las categorías “Viajeros frecuentes” y “Viajeros internacionales frecuentes” provienen, supongo, de mi actividad web fuera de Facebook. Hasta ahora, todo esto está claro.
Finalmente, hay un archivo llamado:
“ads_information/advertisers_using_your_activity_or_information.json”
El título del archivo “anunciantes_que_usan_tu_actividad_o_información” me lleva a creer que Facebook pone mis datos a disposición de sus anunciantes, quienes a su vez los utilizan para dirigirse a mí con anuncios a través de Facebook. Este archivo, entonces, enumera a aquellos anunciantes que me mostraron un anuncio, o que al menos consideraron hacerlo, basándose en mis datos.
El archivo contenía 1,366 anunciantes diferentes. Aquí hay una pequeña muestra de esos anunciantes:
Tabla por el autor
Aparecen en la lista sitios de viajes, minoristas, empresas de tecnología, centros de fitness, empresas de reparación de automóviles, aseguradoras de salud, empresas de medios (que representan a los anunciantes) y otras empresas. Es una amplia variedad de organizaciones, pero en muchos casos puedo ver cómo se relacionan conmigo, mis preferencias y mis hábitos.
Otros archivos en la descarga de Facebook incluyen el historial de búsqueda de Facebook, las marcas de tiempo de búsqueda y los datos de cookies del navegador.
La facilidad de exportación de Google se llama ingeniosamente “Takeout”. La página web de Takeout muestra todos los diversos servicios de Google para los cuales puedes solicitar tus datos (gmail, YouTube, búsqueda, Nest, etc.). También muestra los archivos disponibles para cada servicio y el formato de exportación de cada archivo (json, HTML o csv). La mayor parte del tiempo, Google no te da la opción de elegir el formato de exportación para archivos individuales.
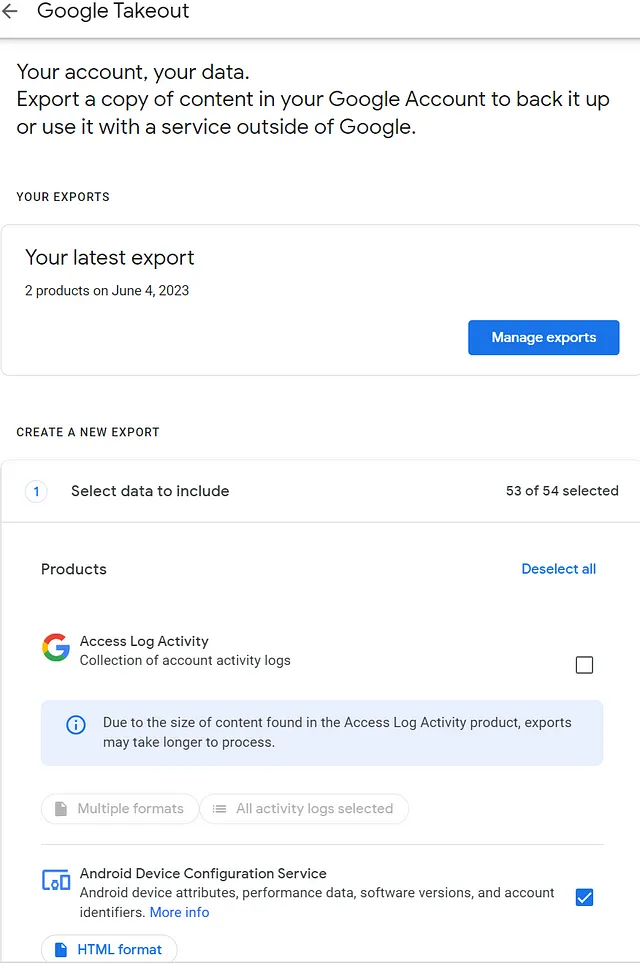
Google hace un buen trabajo al proporcionar una descripción general del propósito de cada archivo. Sin embargo, no hay documentación para los campos individuales.
Recibí 94 archivos en mi extracción. Al igual que en Facebook, había los archivos administrativos normales relacionados con la información del dispositivo, los atributos de la cuenta, las preferencias y el historial de datos de inicio de sesión/acceso.
Un archivo interesante es el titulado “…/Ads/MyActivity.json”. Contiene un historial de anuncios que se me presentaron como resultado de búsquedas.
Algunas entradas en el archivo Ads/MyActivity tienen URL que contienen un dominio clickserve, por ejemplo:

Según el sitio web de anuncios 360 de Google, estos son anuncios de una campaña publicitaria realizada por uno de los anunciantes de Google, que se me mostraron como resultado de alguna actividad de clic que realicé. El archivo no proporciona información sobre qué acción realicé que provocó que se me mostrara el anuncio.
La columna “título” en el archivo distingue entre sitios “Visitados” y temas “Buscados”. Los registros “Visitados” tienen todos “De Google Ads” en la columna “detalles” (ver ejemplo anterior), lo que me lleva a creer que Google me mostró un anuncio como respuesta a haber visitado un sitio en particular.
Los registros “Buscados” muestran sitios que visité directamente (macys.com, yelp.com, etc.). La columna “detalles” muestra esos sitios mientras que la columna “título” aparentemente muestra lo que busqué en esos sitios separados. Por ejemplo,


Otro archivo interesante que encontré se llama ‘…/Mi Actividad/Descubrir/MiActividad.json’. Es un historial de las sugerencias de temas que Google me presentó a través de su función “Descubrir” en la aplicación de Google (anteriormente conocida como la función “Feed” de Google, más información sobre Descubrir aquí). Los temas de Descubrir se seleccionan en función de tu actividad en la web y en las aplicaciones, suponiendo que le des permiso a Google para utilizar tu actividad para guiar los temas de Descubrir.
A pesar de que no permito que Descubrir utilice mi actividad en la web y en las aplicaciones, Descubrir aún me presentó algunas sugerencias de temas relevantes para mí. Aquí tienes una muestra editada de los temas presentados con más frecuencia durante varios días:
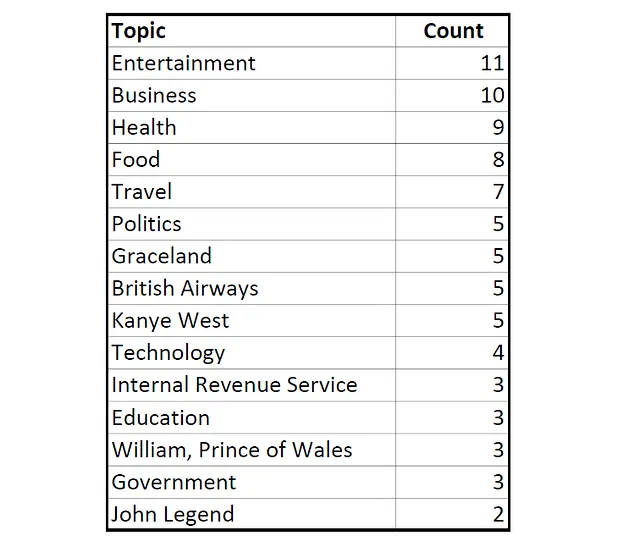
Vemos aquí los temas recurrentes de tecnología y viajes, junto con un nuevo tema que también veremos en los archivos de Apple: ¡música!
Google incluye en su descarga varios archivos que rastrean el historial de actividad en los productos y servicios de Google. Por ejemplo, recibí el historial de mis visitas a los sitios developers.google.com y cloud.google.com para recursos de capacitación y documentación. No se obtuvieron ideas convincentes a partir de estos datos, pero me recordó los temas que quería revisar y estudiar más a fondo.
Otros datos históricos en el extracto incluían búsquedas y acciones realizadas dentro de mi cuenta de Gmail; solicitudes de búsqueda de imágenes; lugares buscados, direcciones solicitadas y mapas vistos a través de la aplicación Google Maps; búsquedas realizadas de videos en la web (fuera de YouTube); búsquedas realizadas y historial de reproducciones en YouTube; y contactos que guardo con Google, presumiblemente en Gmail.
A diferencia de Facebook, Google no proporciona ninguna información sobre un perfil demográfico que Google haya creado para mí.
Ten en cuenta que puedes ver tus datos de actividad de Google en todos sus productos y aplicaciones visitando myactivity.google.com:

Aunque no puedes exportar los datos desde este sitio, puedes navegar por los datos, lo que te permite tener una idea del tipo de datos que puedes querer exportar a través del sitio Google Takeout.
Microsoft
Microsoft te permite exportar algunos de tus datos a través del Panel de privacidad de Microsoft. Para los servicios individuales de Microsoft que no están disponibles en el Panel de privacidad (por ejemplo, MSDN, OneDrive, Microsoft 365 o datos de Skype), puedes utilizar los enlaces en la sección “Cómo acceder y controlar tus datos personales” de la página de declaración de privacidad de Microsoft. La misma página te dirige a un formulario web que puedes enviar si estás buscando datos que no están disponibles mediante ninguno de los métodos anteriores.
Decidí exportar todos los datos disponibles a través del Panel de privacidad. Esto incluía el historial de navegación, el historial de búsqueda, la actividad de ubicación, la música, el historial de TV y películas, y los datos de uso de aplicaciones y servicios. También solicité una exportación de mis datos de Skype. Mi exportación incluyó cuatro archivos CSV, seis archivos JSON y seis archivos JPEG.
No se incluyó documentación de archivos en la exportación y no se encontró ninguna en el sitio de Microsoft. Sin embargo, los nombres de campo en los archivos son bastante intuitivos.
Algunas observaciones interesantes de los archivos de Microsoft:
El archivo ‘…\Microsoft\BúsquedasYConsultas.csv’ contiene datos de las búsquedas que realicé en los últimos 18 meses, incluyendo los términos de búsqueda y, aparentemente, el sitio al que hice clic, si corresponde, en los resultados de búsqueda. Parece que los datos son solo de las búsquedas que hice a través de Bing o Windows Search.
Según los datos, parece que solo hice clic en un enlace en los resultados de búsqueda el 40% de las veces (347 de 870 búsquedas realizadas). A partir de esto, asumo que las búsquedas en las que no hice clic en un enlace eran mal formuladas, devolvían resultados fuera de tema o pude obtener la respuesta que quería simplemente leyendo las vistas previas de los enlaces en los resultados de búsqueda. No recuerdo tener que volver a hacer con frecuencia los términos de búsqueda y sé que a menudo veo la respuesta que necesito directamente en una vista previa de enlace, ya que muchas de mis búsquedas son recordatorios sobre la sintaxis de programación. De cualquier manera, me sorprendió un poco la tasa de clics del 40%. Esperaba que fuera mucho más alta.
No hay mucho interesante en los datos de Skype. Contenía el historial de los hilos de mensajes dentro de la aplicación entre yo y otros participantes de las reuniones de Skype. También se incluyeron archivos JPEG con imágenes de los participantes de algunas de mis llamadas.
Apple Fitness
Tuve que acceder a mis datos de salud y fitness de Apple por separado de los otros datos que exporté de Apple. Los datos de salud y fitness se acceden desde la aplicación Salud en el iPhone. Simplemente haga clic en su icono en la esquina superior derecha de la pantalla de la aplicación Salud. Esto lo lleva a una pantalla de perfil y luego hace clic en el enlace Exportar todos los datos de salud en la parte inferior de la pantalla:
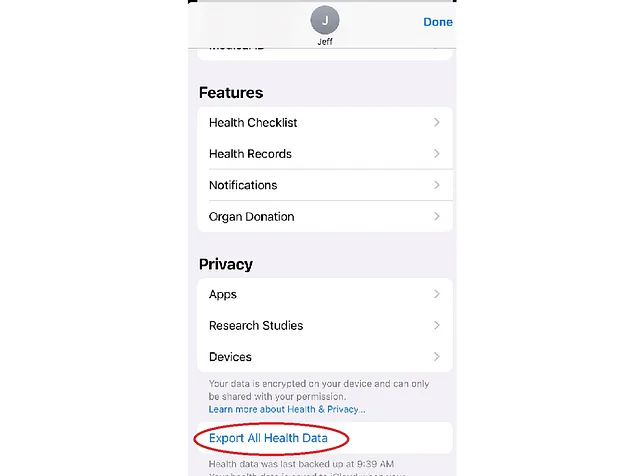
Mi exportación de salud incluía casi 500 archivos .gpx que suman 102 megabytes. Contienen información de ruta de mis entrenamientos grabados en los últimos años. Otros 48 archivos contenían 5.3 megabytes de datos de electrocardiograma de autopruebas que realicé en mi Apple Watch.
El archivo llamado ‘…/Apple/apple_health_export/export.xml’ contiene los datos realmente interesantes. Para mí, tiene 770 megabytes con 1,956,838 registros que cubren múltiples mediciones de salud y ejercicio diferentes durante aproximadamente siete años. Algunos de los tipos de actividad medidas son los siguientes:
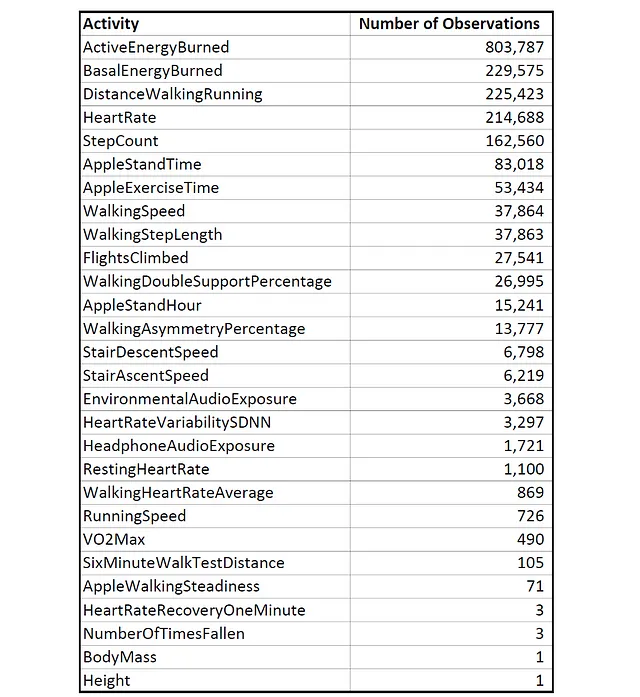
Tenga en cuenta que la frecuencia con la que Apple registra los datos varía según el tipo de actividad. Por ejemplo, la Energía Activa Quemada se registra por hora, mientras que la Velocidad de Ascenso de Escaleras se registra solo al subir escaleras, lo que explica la gran diferencia en el número de observaciones entre estos dos tipos de actividad.
Los datos registrados para cada observación incluyen la fecha/hora en la que se registró la observación, las fechas/horas de inicio y finalización de la actividad que se está midiendo y el dispositivo que registró la actividad (iPhone o Apple Watch).
En su excelente artículo “Analyse Your Health with Python and Apple Health” (Analiza tu salud con Python y Apple Health), Alejandro Rodríguez proporciona el código que utilicé para analizar el archivo xml en export.xml y crear un marco de datos de Pandas. (¡Gracias Alejandro!) Después de seleccionar un subconjunto de datos de un año y agruparlos y agregarlos por día y tipo de actividad, descubrí algunas cosas interesantes.
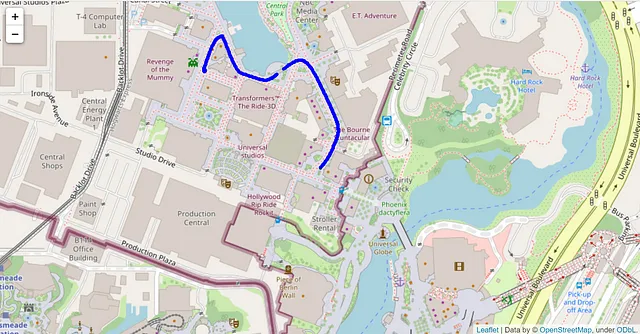
Como sospechaba, mis niveles de actividad promedio eran diferentes en los días en que viajaba en comparación con los días en que estaba en una de las ciudades que considero mi hogar (Austin o Chicago). Para ver esto, tuve que usar los datos de latitud y longitud de los archivos de ruta de ejercicio .gpx mencionados anteriormente. Eso me permitió determinar qué rutas estaban en una ciudad de origen y cuáles ocurrieron mientras viajaba. Luego fusioné esos datos de ubicación con mis datos de resumen de actividad. Luego, esto se resumió aún más por tipo de actividad y ubicación (ciudad de origen o viaje). Aquí está el patrón que se fusionó:
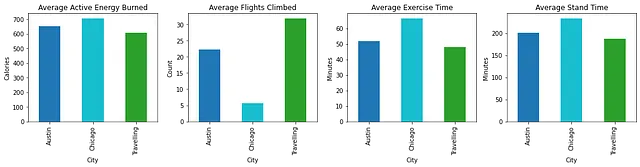
Mientras estoy en Chicago, estoy en un edificio de apartamentos con un ascensor, por lo que no fue una sorpresa la gran disminución en el número promedio de escaleras subidas. Lo que fue sorprendente fue el aumento en los niveles de actividad en Chicago en comparación con Austin. Mi rutina de ejercicio es muy similar en ambos lugares, pero hago más ejercicio en Chicago. Creo que esto se debe a que camino a más lugares en Chicago en lugar de conducir la mayor parte del tiempo. Claramente, necesito aumentar la cantidad de ejercicio que hago en Austin.
Identificar tendencias como la anterior, que no se pueden ver en los gráficos estándar de la aplicación Salud de Apple, es un gran uso de los datos de salud.
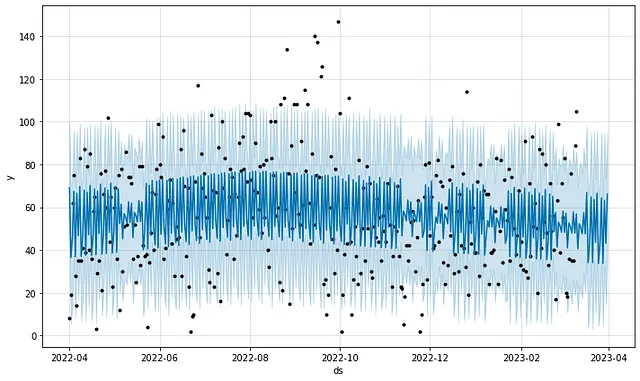
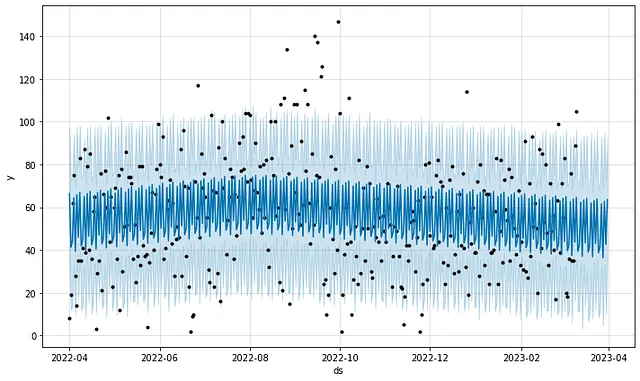
Los datos también son excelentes para modelar, ya que son muy completos y generalmente están limpios. Aquí, por ejemplo, hay un pronóstico de series de tiempo de mis minutos de ejercicio basado en un período de un año utilizando el modelo Prophet de Facebook:
Aquí está el mismo pronóstico, pero con estacionalidad anual habilitada y estacionalidad semanal agregada manualmente según mi ubicación (Austin, Chicago o viaje):
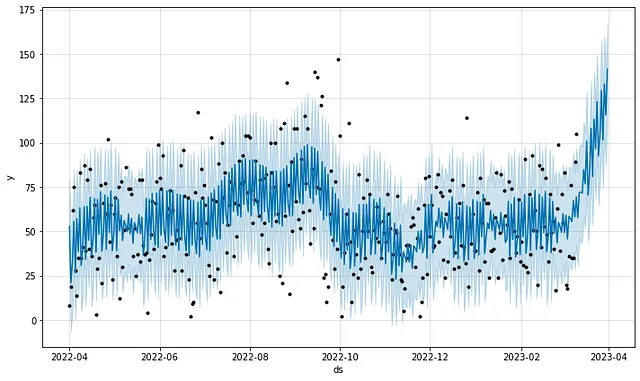
El modelo de estacionalidad semanal predeterminado anterior (primer gráfico) se ajusta peor a los datos de entrenamiento que el modelo con términos de estacionalidad personalizados agregados (segundo gráfico). Sin embargo, el modelo de estacionalidad predeterminado es mucho mejor (aunque aún no es óptimo) para predecir los valores futuros de los minutos de ejercicio. No hace falta decir que la optimización de hiperparámetros ayudaría a mejorar estos resultados.

Esto es solo una muestra del tipo de modelado que puedes experimentar utilizando tus datos de salud. ¿Quieres intentar usar datos de series de tiempo muy detallados? Mira los archivos de rutas de entrenamiento. Tienen observaciones para cada segundo de tus entrenamientos grabados con campos de latitud, longitud, elevación y velocidad.
Apple — No Aptitud/Salud
Solicita la descarga de todos tus datos de no aptitud/salud desde el sitio web principal de Apple. Para mí, eso representó 84 archivos, principalmente archivos .csv y .json junto con algunos archivos .xml. También recibí cientos de archivos .vcf, uno por cada uno de los contactos que tengo en mis dispositivos Apple. En total, descargué 68 MB de datos, excluyendo los archivos .vcf.
Apple se destaca por proporcionar documentación completa para cada uno de los archivos de datos. Incluye explicaciones de cada campo, aunque algunas definiciones son más útiles que otras. La documentación me ayudó a interpretar algunos archivos de datos que parecían intrigantes.
Al igual que con la mayoría de las exportaciones, los archivos de Apple incluían los datos administrativos normales, incluidas cosas como mis preferencias para diversas aplicaciones, información de inicio de sesión e información del dispositivo. No encontré nada notable en esos archivos.
Hay varios archivos relacionados con Apple Music, uno de los servicios a los que estoy suscrito. Archivos con títulos como:
- “…/Media_Services/Apple Music — Play History Daily Tracks.csv”;
- “…/Media_Services/Apple Music — Recently Played Tracks.csv’’; y,
- “…/Media_Services/Apple Music Play Activity.csv”
contienen información como:
- la fecha y hora en que se reprodujo una canción;
- la duración de reproducción en milisegundos;
- cómo se finalizó cada reproducción (por ejemplo, llegó al final de la pista o salté la canción);
- la cantidad de veces que se ha reproducido la canción;
- la cantidad de veces que se omitió la canción;
- el título de la canción;
- el título del álbum, si corresponde;
- el género de la canción; y,
- desde dónde se reprodujo la canción — mi biblioteca, una lista de reproducción o uno de los canales de radio de Apple.
Mis archivos contenían entre 13,900 y 20,700 registros dependiendo del propósito del archivo. Los datos cubrían casi siete años de reproducciones de canciones.
Apple recopila varios datos sobre cómo se finalizan las reproducciones de canciones, probablemente con el propósito de recomendarme otras canciones. Las razones de finalización de reproducción de canciones incluyen:
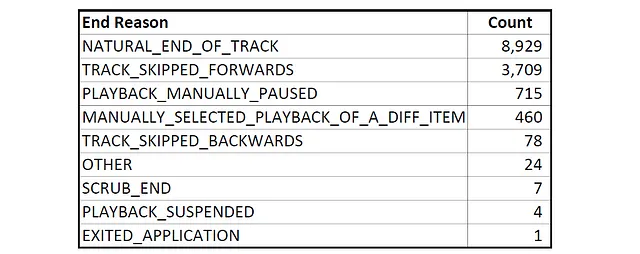
Para los análisis que muestro a continuación, me centré en las razones de finalización ‘NATURAL_END_OF_TRACK’, ‘TRACK_SKIPPED_FORWARDS’ y ‘MANUALLY_SELECTED_PLAYBACK_OF_A_DIFF_ITEM’.
A veces repito una canción que me gusta. Una pregunta que tenía era “¿Reproduzco canciones favoritas obsesivamente, una y otra vez?”. Respondí esa pregunta utilizando los datos de Apple:
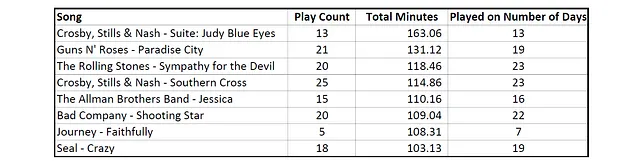
La tabla anterior resume la cantidad de veces que he reproducido algunas canciones favoritas (‘Conteo de reproducciones’) y la cantidad de días en los que he reproducido las canciones (‘Reproducido en número de días’). Parece que generalmente reproduzco una canción solo una vez al día. Además, dado que el conteo de reproducciones es menor que el conteo de días para algunas canciones, debo saltarme algunos favoritos si los he escuchado demasiadas veces recientemente o si la canción no se ajusta a mi estado de ánimo en ese momento. ¡Así que aquí no hay reproducciones obsesivas!
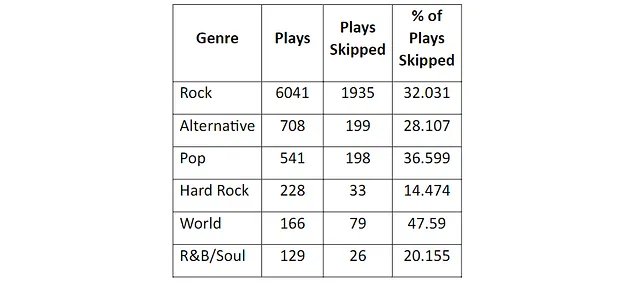
También me pregunté si tengo preferencia por ciertos tipos de canciones en diferentes días de la semana, diferentes momentos del día o incluso diferentes meses del año. Mi intuición dice que sí. Con los datos de Apple, fue fácil visualizar los géneros que reproduje en diferentes momentos. Aquí, por ejemplo, están los géneros que reproduje con más frecuencia durante cada mes del año:
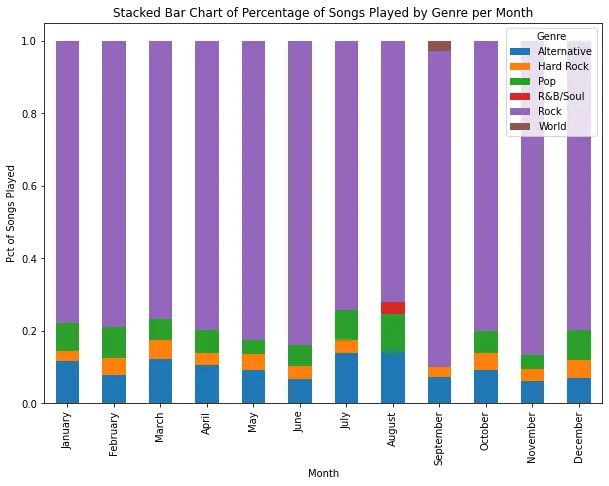
Claramente, tengo preferencia por las canciones de rock, con música alternativa y pop agregada para variar ocasionalmente. Julio y agosto parecen ser los meses en los que prefiero la variedad.
Dicho esto, me sorprendió cuánto rock parezco reproducir. Admito que me encanta. Pero también creo que tengo un gusto bastante amplio en música.
Entonces, cuestioné la precisión del género asignado a las canciones en los datos de Apple. Por un lado, 10,083 de las 22,313 reproducciones de canciones en mi archivo no tenían un género asignado. Además, parece haber mucha superposición en los géneros asignados. Por ejemplo, “R&B/Soul”, “Soul and R&B”, “Soul” y “R&B / Soul” son todos géneros asignados a diferentes canciones en mis datos. Los totales en el gráfico anterior ciertamente serían diferentes si volviera a asignar los géneros de todas las canciones utilizando un esquema de nomenclatura de género consistente.
En lugar de invertir tiempo en actualizar los géneros, decidí realizar otra prueba para determinar si las tendencias en el gráfico realmente representan mis patrones de reproducción. Dado que Apple incluye las razones por las que se detiene la reproducción de una canción en los datos, busqué ver si tiendo a saltar más canciones de rock que de otros géneros, lo que indicaría que intento reproducir otros géneros cuando se están reproduciendo demasiadas canciones de rock.
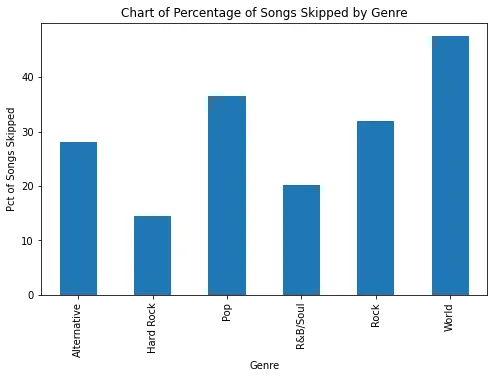
Resulta que no salto las canciones de rock significativamente más que otros géneros que escucho con frecuencia. Tendré que aceptarlo: soy un fanático incondicional del rock.
Otro archivo interesante se llama “…/Media_Services/Stores Activity/Other Activity/App Store Click Activity.csv”. Aunque no lo analizo aquí, lo recomiendo a cualquiera que quiera tener una idea del tipo de datos que un minorista puede querer rastrear para la actividad en su sitio web. Para mí, incluía más de 4,900 registros con un historial detallado de mi actividad en la tienda de aplicaciones y, aparentemente, en Apple Music. Entre los elementos incluidos en el archivo se encuentran los tipos de acciones que realicé, fechas/horas, indicador de prueba A/B, términos de búsqueda y datos presentados (“impressed” es el término utilizado).
Un último archivo potencialmente interesante para el análisis se llama \\Media_Services\\Stores Activity\\Other Activity\\Apple Music Click Activity V3.csv. Incluye la ciudad y la longitud/latitud de la dirección IP donde, supongo, estaba usando Apple Music. Para mí, el archivo tenía 10,000 registros.
Verizon
Después de una espera de más de 80 días, Verizon me notificó que podía descargar mis datos. Incluía 17 archivos csv con un total de 1.4 megabytes de datos. La mayoría de los archivos cubrían información administrativa de la cuenta (descripciones de líneas celulares, información del dispositivo, historial de facturación, historial de pedidos, etc.), el historial de notificaciones que Verizon me envió y mi historial reciente de mensajes de texto (pero sin el contenido de los mensajes). Aunque se proporcionaron archivos de Historial de Llamadas y Uso de Datos, estaban vacíos excepto por una nota que decía “Enmascarado por seguridad”.
Verizon proporcionó dos archivos de documentación. Uno contenía los nombres y descripciones generales de 34 posibles archivos que podrían incluirse en una descarga. Los archivos incluidos dependen de los servicios de Verizon que utilices. El segundo archivo de documentación contenía una descripción de 3,091 campos de datos que podrían aparecer en los archivos. Si bien las descripciones de los campos de datos son útiles, carecen de algunos detalles. Por ejemplo, muchos campos se describen como conteniendo códigos para diversos fines, sin embargo, los códigos en sí y sus significados no se describen.
Un archivo que resultó extremadamente interesante se llama “…/Verizon/General Inferences.csv”. Contiene una cantidad espectacular de información demográfica sobre mí y sobre otras personas en mi hogar. Así es como la documentación de Verizon describe el archivo:
“El archivo de Inferencias Generales proporciona información sobre suposiciones e inferencias generales para ofrecer contenido más relacionado y relevante en nuestras plataformas. Esto puede incluir información como Atributos, Preferencias u Opiniones”.
Basándome en la naturaleza de las características demográficas, asumo que la mayoría de ellas fueron adquiridas por Verizon de agregadores de datos externos y no recopiladas directamente por Verizon de mí. El número y alcance de las características demográficas superan con creces cualquier información que yo haya proporcionado directamente a Verizon.
De hecho, la documentación de Verizon habla sobre otro archivo llamado “Información General” (que no se incluye en mi descarga). La documentación dice que el archivo “General” incluye datos que provienen de fuentes de información externas. Supongo que la información en el archivo “Inferencias Generales” también proviene de esas fuentes externas. Algunos de los datos financieros en el archivo “Inferencias Generales” podrían haber provenido del informe crediticio que Verizon requiere que sus clientes proporcionen.
Se incluyeron un total de 332 características demográficas en mis datos de Inferencias Generales. Aquí hay una lista abreviada que incluye algunas de las características más sorprendentes:

Todas las características de Inferencias Generales aparentemente son utilizadas por Verizon para comercializar hacia mí y retenerme como cliente. Como puedes ver en la lista anterior, también se incluyen características sobre mi cónyuge y nuestros hijos. Puedes ver la lista completa de las 332 características aquí.
Algunas de las características que encontré realmente inusuales incluyen:

Uno se pregunta si ese tipo de elementos de datos realmente son necesarios para que Verizon me brinde servicio y, de ser así, cómo los utiliza Verizon.
Amazon
Amazon proporcionó 214 archivos que contienen 4.93 megabytes de datos. Varios de los archivos cubren:
- Preferencias de cuenta;
- Historial de pedidos;
- Historial de cumplimiento y devoluciones;
- Historial de visualización y escucha (Amazon Prime Video y Amazon Music);
- Compras y actividad de lectura en Kindle,
- y historial de búsqueda que incluye términos de búsqueda.
Si fuera cliente de Alexa o cliente de Ring, asumo que también habría recibido datos sobre mi actividad en esos servicios.
Seis archivos .txt contenían descripciones de alto nivel de algunos de los archivos de datos descargados. Varios archivos .pdf contienen documentación de los campos en los archivos descargados (por ejemplo, el archivo “Digital.PrimeVideo.Viewinghistory.Description.pdf”).
Los archivos más interesantes de Amazon se refieren a las audiencias de marketing asociadas conmigo por parte de Amazon, sus anunciantes o “terceros”. Presumo que los terceros son proveedores de datos de los cuales Amazon compra datos.
El archivo “…/Amazon/Advertising.1/Advertising.AmazonAudiences.csv” contiene las audiencias que Amazon me asignó. Aquí hay una muestra de las 21 audiencias:
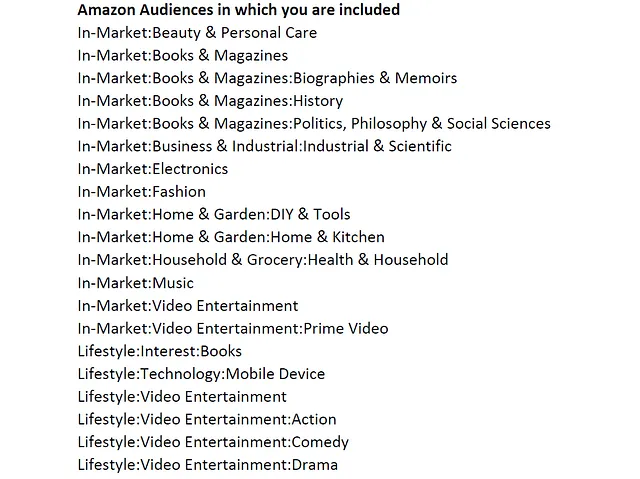
Las asignaciones de audiencia de Amazon son en su mayoría precisas cuando considero los productos que compré o busqué, ya sea para mí mismo o en nombre de otros.
El archivo “…/Amazon/Advertising.1/Advertising.AdvertiserAudiences.csv” aparentemente contiene una lista de anunciantes de Amazon que trajeron sus propias audiencias a Amazon y cuyas listas de audiencia me incluyen a mí. El archivo contiene 50 anunciantes. Aquí hay una muestra:

Hago negocios con o tengo productos de algunos de los anunciantes de la lista (por ejemplo, Delta, Intuit, Zipcar), por lo que entiendo cómo terminé en sus listas de audiencia. No tengo conexión con otros en la lista (por ejemplo, AT&T, Red Bull, Royal Bank of Canada), por lo que no estoy seguro de cómo llegué a sus listas de audiencia.
Según Amazon, el archivo
“…/Amazon/Publicidad.1/Publicidad.3PAudiencias.csv”
contiene una lista de
“Audiencias en las que estás incluido por terceros”.
Su precisión es baja. Se enumeran un total de 33 audiencias, 28 de las cuales se centran en la propiedad de automóviles. Las cuatro restantes cubren género, nivel educativo, estado civil y dependientes. Una muestra de las audiencias relacionadas con automóviles:

Aunque las asignaciones de género/nivel educativo/estado civil en el archivo son precisas, solo algunas de las asignaciones relacionadas con automóviles son correctas. La mayoría no lo son. Y, simplemente no tengo tanto interés en los automóviles como para justificar 28 de las 33 asignaciones de perfil. Afortunadamente, Amazon parece ignorar estos datos cuando me presenta recomendaciones de productos o videos.
Pensamientos finales
En este artículo, esperaba mostrarte la amplia variedad de datos que puedes obtener de las empresas con las que haces negocios. Los datos te permiten aprender lo que esas empresas piensan de ti, ¡mientras también aprendes algunas cosas sorprendentes sobre ti mismo!
Hemos visto que algunas empresas identifican correctamente mis intereses en tecnología y viajes, mientras que una empresa me ve incorrectamente como un entusiasta de los automóviles. En un momento revelador y algo inquietante, me di cuenta de que otra empresa tiene información demográfica extensa sobre mi familia.
Aprendí que necesito aumentar mi régimen de ejercicio en uno de los dos lugares que llamo hogar, aunque pensaba que mis entrenamientos eran equivalentes en ambos lugares. Descubrí que algunas empresas (Facebook, Google) no tienen una visión sólida de mi perfil. Sin embargo, la imagen demográfica que Verizon tiene de mí es sorprendentemente precisa.
Los datos que te proporcionan las diversas empresas son una fuente rica de material bruto para experimentación. Es un dato que se presta para análisis profundos, modelado y actividades de visualización. Por ejemplo, se dispone de coordenadas geográficas y marcas de tiempo para muchas observaciones, lo que te permite visualizar o modelar tus movimientos.
Espero que encuentres tu propio conjunto de ideas interesantes al descargar tus datos personales. Por favor, avísame si tienes experiencias destacadas al trabajar con empresas que no menciono aquí.
Es tu dato, ¡ahora a por él!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Lo mejor de ambos mundos desarrolladores humanos y colaboradores de IA
- ¡Atención Industria del Gaming! No más espejos extraños con Mirror-NeRF
- Optimización del tamaño del archivo de salida en Apache Spark
- GANs (Redes Generativas Adversarias)
- La IA es crucial para la ciberseguridad en el ámbito de la salud
- Clasificación de texto sin entrenamiento previo con Amazon SageMaker JumpStart
- ¿Qué tienen en común una medusa, un gato, una serpiente y un astronauta? Matemáticas






