Abriendo en Canal la Biblioteca de Transformers de Hugging Face
Abriendo la Biblioteca de Transformers de Hugging Face
Una guía rápida para usar los LLM de código abierto
Este es el tercer artículo de una serie sobre el uso de grandes modelos de lenguaje (LLMs) en la práctica. Aquí daré una guía amigable para principiantes sobre la biblioteca Hugging Face Transformers, que proporciona una forma fácil y gratuita de trabajar con una amplia variedad de modelos de lenguaje de código abierto. Empezaré revisando conceptos clave y luego me sumergiré en ejemplos de código Python.
En el artículo anterior de esta serie, exploramos la API de Python de OpenAI y la utilizamos para crear un chatbot personalizado. Sin embargo, una desventaja de esta API es que las llamadas a la API tienen un costo, lo cual puede no ser escalable para algunos casos de uso.
En estos escenarios, puede ser ventajoso recurrir a soluciones de código abierto. Una forma popular de hacer esto es a través de la biblioteca Transformers de Hugging Face.
¿Qué es Hugging Face?
Hugging Face es una compañía de IA que se ha convertido en un importante centro para el aprendizaje automático (ML) de código abierto. Su plataforma tiene 3 elementos principales que permiten a los usuarios acceder y compartir recursos de aprendizaje automático.
- 3 funciones de pandas para combinar DataFrames
- Microsoft recibe duras críticas por su seguridad groseramente irresponsable
- Optimizar la preparación de datos con nuevas funciones en AWS SageMaker Data Wrangler
El primero es su creciente repositorio de modelos de ML de código abierto pre-entrenados para tareas como el procesamiento del lenguaje natural (NLP), la visión por computadora y más. El segundo es su biblioteca de conjuntos de datos para entrenar modelos de ML para casi cualquier tarea. Tercero, y finalmente, está Spaces, que es una colección de aplicaciones de ML de código abierto alojadas por Hugging Face.
La potencia de estos recursos radica en que son generados por la comunidad, lo que aprovecha todos los beneficios del código abierto (es decir, sin costo, amplia diversidad de herramientas, recursos de alta calidad y ritmo rápido de innovación). Si bien esto hace que la construcción de proyectos de ML potentes sea más accesible que antes, hay otro elemento clave del ecosistema de Hugging Face: la biblioteca Transformers.
🤗Transformers
Transformers es una biblioteca de Python que facilita la descarga y el entrenamiento de modelos de ML de última generación. Aunque inicialmente se creó para desarrollar modelos de lenguaje, su funcionalidad se ha ampliado para incluir modelos para visión por computadora, procesamiento de audio y más.
Dos grandes fortalezas de esta biblioteca son, en primer lugar, que se integra fácilmente con los repositorios de Modelos, Conjuntos de datos y Spaces de Hugging Face mencionados anteriormente, y en segundo lugar, la biblioteca es compatible con otros marcos populares de ML como PyTorch y TensorFlow.
Esto resulta en una plataforma simple y flexible todo en uno para descargar, entrenar e implementar modelos de aprendizaje automático y aplicaciones.
Pipeline()
La forma más sencilla de comenzar a utilizar la biblioteca es a través de la función pipeline(), que abstrae tareas de NLP (y otras) en 1 línea de código. Por ejemplo, si queremos hacer análisis de sentimientos, necesitaríamos seleccionar un modelo, tokenizar el texto de entrada, pasarlo por el modelo y decodificar la salida numérica para determinar la etiqueta de sentimiento (positivo o negativo).
Aunque esto puede parecer muchos pasos, podemos hacer todo esto en 1 línea utilizando la función pipeline(), como se muestra en el fragmento de código a continuación.
pipeline(task="sentiment-analysis")("¡Me encanta!")# salida -> [{'label': 'POSITIVO', 'score': 0.9998745918273926}]Por supuesto, el análisis de sentimientos no es lo único que podemos hacer aquí. Casi cualquier tarea de NLP se puede hacer de esta manera, por ejemplo, resumen, traducción, pregunta-respuesta, extracción de características (es decir, incrustación de texto), generación de texto, clasificación sin etiquetas y más. Para ver una lista completa de las tareas integradas, consulte la documentación de pipeline().
En el código de ejemplo anterior, como no especificamos un modelo, se utilizó el modelo predeterminado para el análisis de sentimientos (es decir, distilbert-base-uncased-finetuned-sst-2-english). Sin embargo, si quisiéramos ser más explícitos, podríamos haber utilizado la siguiente línea de código.
pipeline(tarea="análisis-de-sentimientos", modelo='distilbert-base-uncased-finetuned-sst-2-english')("¡Amo esto!")# salida -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]Uno de los mayores beneficios de la biblioteca Transformers es que podríamos haber utilizado cualquiera de los 28,000+ modelos de clasificación de texto disponibles en el repositorio de modelos de Hugging Face simplemente cambiando el nombre del modelo pasado a la función pipeline().
Modelos
Hay un enorme repositorio de modelos pre-entrenados disponibles en Hugging Face (277,528 en el momento de escribir esto). Casi todos estos modelos se pueden utilizar fácilmente a través de Transformers, utilizando la misma sintaxis que vimos en el bloque de código anterior.
Sin embargo, los modelos en Hugging Face no son solo para la biblioteca Transformers. También hay modelos para otros populares frameworks de aprendizaje automático como PyTorch, Tensorflow, Jax. Esto hace que el repositorio de modelos de Hugging Face sea útil para los profesionales de aprendizaje automático más allá del contexto de la biblioteca Transformers.
Para ver cómo se navega por el repositorio, consideremos un ejemplo. Digamos que queremos un modelo que pueda generar texto, pero queremos que esté disponible a través de la biblioteca Transformers para poder usarlo en una sola línea de código (como hicimos antes). Podemos ver fácilmente todos los modelos que cumplen con estos criterios utilizando los filtros “Tasks” y “Libraries”.
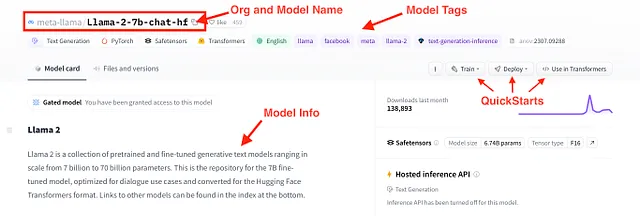
Un modelo que cumple con estos criterios es el recientemente lanzado Llama 2. Más específicamente, Llama-2–7b-chat-hf, que es un modelo de la familia Llama 2 con aproximadamente 7 mil millones de parámetros, optimizado para chat y en formato Transformers de Hugging Face. Podemos obtener más información sobre este modelo a través de su tarjeta de modelo, que se muestra en la figura de abajo.
Instalación 🤗Transformers (con Conda)
Ahora que tenemos una idea básica de los recursos ofrecidos por Hugging Face y la biblioteca Transformers, veamos cómo podemos usarlos. Comenzamos instalando la biblioteca y otras dependencias.
Hugging Face proporciona una guía de instalación en su sitio web. Por lo tanto, no intentaré duplicar esa guía aquí de forma deficiente. Sin embargo, proporcionaré una guía rápida de 2 pasos sobre cómo configurar el entorno de conda para el código de ejemplo a continuación.
Paso 1) El primer paso es descargar el archivo hf-env.yml disponible en el repositorio de GitHub. Puede descargar el archivo directamente o clonar todo el repositorio.
Paso 2) Luego, en su terminal (o en el símbolo del sistema de Anaconda), puede crear un nuevo entorno conda basado en hf-env.yml utilizando los siguientes comandos
>>> cd <directorio con hf-env.yml>>>> conda env create --file hf-env.ymlEsto puede tardar unos minutos en instalarse, pero una vez completado, ¡deberías estar listo para comenzar!
Código de Ejemplo: NLP con 🤗Transformers
Con las bibliotecas necesarias instaladas, vamos a ver algunos ejemplos de código. Aquí vamos a examinar 3 casos de uso de NLP, a saber, análisis de sentimientos, resumen y generación de texto conversacional, utilizando la función pipeline().
Al final, utilizaremos Gradio para generar rápidamente una interfaz de usuario (UI) para cualquiera de estos casos de uso y desplegarla como una aplicación en Hugging Face Spaces. Todo el código de ejemplo está disponible en el repositorio de GitHub.
Análisis de Sentimientos
Comenzamos con el análisis de sentimientos. Recordemos que antes utilizamos la función pipeline para hacer algo como el bloque de código a continuación, donde creamos un clasificador que puede etiquetar el texto de entrada como positivo o negativo.
from transformers import pipeline
classifier = pipeline(task="sentiment-analysis", \
model="distilbert-base-uncased-finetuned-sst-2-english")
classifier("¡Odio esto!")# output -> [{'label': 'NEGATIVE', 'score': 0.9997110962867737}]
Para ir un paso más allá, en lugar de procesar texto uno por uno, podemos pasar una lista al clasificador para procesar en lotes.
text_list = ["Esto es genial", \
"Gracias por nada", \
"Tienes que trabajar en tu cara", \
"¡Eres hermosa, nunca cambies!"]
classifier(text_list)# output -> [{'label': 'POSITIVE', 'score': 0.9998785257339478},# {'label': 'POSITIVE', 'score': 0.9680058360099792},# {'label': 'NEGATIVE', 'score': 0.8776106238365173},# {'label': 'POSITIVE', 'score': 0.9998120665550232}]
Sin embargo, los modelos de clasificación de texto en Hugging Face no se limitan solo a sentimiento positivo-negativo. Por ejemplo, el modelo "roberta-base-go_emotions" de SamLowe genera una serie de etiquetas de clase. Podemos aplicar fácilmente este modelo al texto, como se muestra en el fragmento de código a continuación.
classifier = pipeline(task="text-classification", \
model="SamLowe/roberta-base-go_emotions", top_k=None)
classifier(text_list[0])# output -> [[{'label': 'admiration', 'score': 0.9526104927062988},# {'label': 'approval', 'score': 0.03047208860516548},# {'label': 'neutral', 'score': 0.015236231498420238},# {'label': 'excitement', 'score': 0.006063772831112146},# {'label': 'gratitude', 'score': 0.005296189337968826},# {'label': 'joy', 'score': 0.004475208930671215},# ... y muchos más
Resumen
Otra forma en que podemos usar la función pipeline() es para resumir texto. Aunque esta es una tarea completamente diferente al análisis de sentimientos, la sintaxis es casi idéntica.
Primero cargamos un modelo de resumen. Luego pasamos un texto junto con un par de parámetros de entrada.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
text = """Hugging Face es una compañía de IA que se ha convertido en un importante centro de aprendizaje automático de código abierto. Su plataforma tiene 3 elementos principales que permiten a los usuarios acceder y compartir recursos de aprendizaje automático. Primero, está su creciente repositorio de modelos de aprendizaje automático de código abierto pre-entrenados para cosas como procesamiento del lenguaje natural (NLP), visión por computadora y más. Segundo, está su biblioteca de conjuntos de datos para entrenar modelos de aprendizaje automático para casi cualquier tarea. Tercero, y finalmente, está Spaces, que es una colección de aplicaciones de ML de código abierto. El poder de estos recursos es que son generados por la comunidad, lo que aprovecha todos los beneficios del código abierto, es decir, sin costo, amplia diversidad de herramientas, recursos de alta calidad y un ritmo rápido de innovación. Si bien esto hace que la construcción de proyectos de ML potentes sea más accesible que antes, hay otro elemento clave del ecosistema de Hugging Face: su biblioteca Transformers."""
summarized_text = summarizer(text, min_length=5, max_length=140)[0]['summary_text']
print(summarized_text)# output -> 'Hugging Face es una compañía de IA que se ha convertido en un importante centro para el aprendizaje automático de código abierto. Tienen 3 elementos principales que permiten a los usuarios acceder y compartir recursos de aprendizaje automático.'
Para casos de uso más sofisticados, puede ser necesario utilizar múltiples modelos en sucesión. Por ejemplo, podemos aplicar análisis de sentimientos al texto resumido para acelerar el tiempo de ejecución.
classifier(summarized_text)# output -> [[{'label': 'neutral', 'score': 0.9101783633232117}, # {'label': 'approval', 'score': 0.08781372010707855}, # {'label': 'realization', 'score': 0.023256294429302216}, # {'label': 'annoyance', 'score': 0.006623792927712202}, # {'label': 'admiration', 'score': 0.004981081001460552}, # {'label': 'disapproval', 'score': 0.004730119835585356}, # {'label': 'optimism', 'score': 0.0033590723760426044}, # ... y muchos másConversacional
Finalmente, podemos utilizar modelos desarrollados específicamente para generar texto conversacional. Dado que las conversaciones requieren que los estímulos y respuestas pasadas se pasen a las respuestas del modelo subsecuente, la sintaxis es un poco diferente aquí. Sin embargo, comenzamos instanciando nuestro modelo utilizando la función pipeline().
chatbot = pipeline(model="facebook/blenderbot-400M-distill")A continuación, podemos utilizar la clase Conversation() para manejar el diálogo de ida y vuelta. La inicializamos con un estímulo del usuario y luego lo pasamos al modelo de chatbot del bloque de código anterior.
from transformers import Conversationconversation = Conversation("Hola, soy Shaw, ¿cómo estás?")conversation = chatbot(conversation)print(conversation)# output -> ID de conversación: 9248ee7d-2a58-4355-9fba-525189fae206 # usuario >> Hola, soy Shaw, ¿cómo estás? # bot >> Estoy bien. ¿Cómo te encuentras esta noche? Acabo de llegar a casa del trabajo. Para mantener la conversación en curso, podemos utilizar el método add_user_input() para agregar otro estímulo a la conversación. Luego, pasamos el objeto de la conversación nuevamente al chatbot.
conversation.add_user_input("¿Dónde trabajas?")conversation = chatbot(conversation)print(conversation)# output -> ID de conversación: 9248ee7d-2a58-4355-9fba-525189fae206 # usuario >> Hola, soy Shaw, ¿cómo estás? # bot >> Estoy bien. ¿Cómo te encuentras esta noche? Acabo de llegar a casa del trabajo.# usuario >> ¿Dónde trabajas? # bot >> Trabajo en un supermercado. ¿Y tú? ¿A qué te dedicas? Interfaz de usuario del chatbot con Gradio
Aunque obtenemos la funcionalidad básica del chatbot con la biblioteca Transformer, esta no es una forma conveniente de interactuar con un chatbot. Para hacer la interacción un poco más intuitiva, podemos usar Gradio para crear una interfaz frontal en pocas líneas de código en Python.
Esto se logra con el siguiente código. En la parte superior, inicializamos dos listas para almacenar los mensajes del usuario y las respuestas del modelo, respectivamente. Luego, definimos una función que tomará el estímulo del usuario y generará una respuesta del chatbot. A continuación, creamos la interfaz de chat utilizando la clase ChatInterface() de Gradio. Por último, lanzamos la aplicación.
message_list = []response_list = []def chatbot_vainilla(message, historial): conversation = Conversation(text=message, past_user_inputs=message_list, generated_responses=response_list) conversation = chatbot(conversation) return conversation.generated_responses[-1]demo_chatbot = gr.ChatInterface(chatbot_vainilla, title="Chatbot Vainilla", description="Ingresa texto para comenzar a chatear.")demo_chatbot.launch()Esto iniciará la interfaz mediante una URL local. Si la ventana no se abre automáticamente, puedes copiar y pegar la URL directamente en tu navegador.
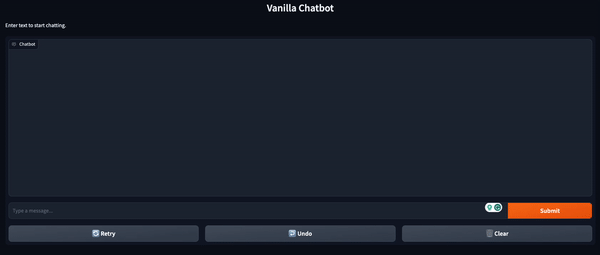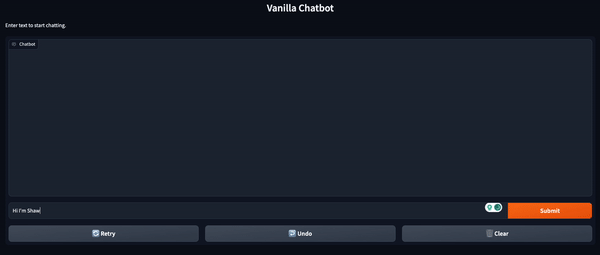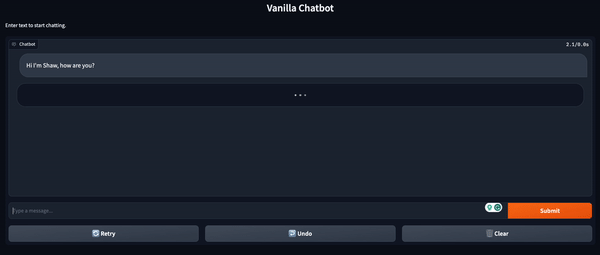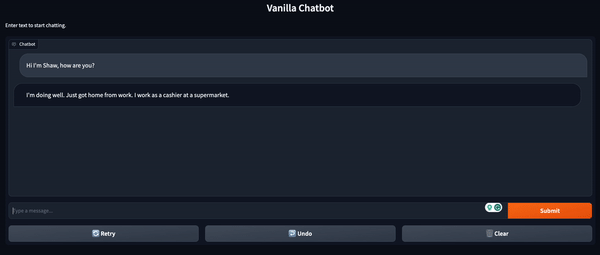
Hugging Face Spaces
Para ir un paso más allá, podemos implementar rápidamente esta interfaz a través de Hugging Face Spaces. Estos son repositorios de Git alojados por Hugging Face y ampliados por recursos computacionales. Hay opciones gratuitas y de pago disponibles según el caso de uso. Aquí nos quedaremos con la opción gratuita.
Para crear un nuevo espacio, primero vamos a la página de Espacios y hacemos clic en “Crear nuevo espacio”. Luego, configuramos el espacio dándole un nombre, por ejemplo, “mi-primer-espacio”, y seleccionando Gradio como el SDK. Luego hacemos clic en “Crear espacio”.
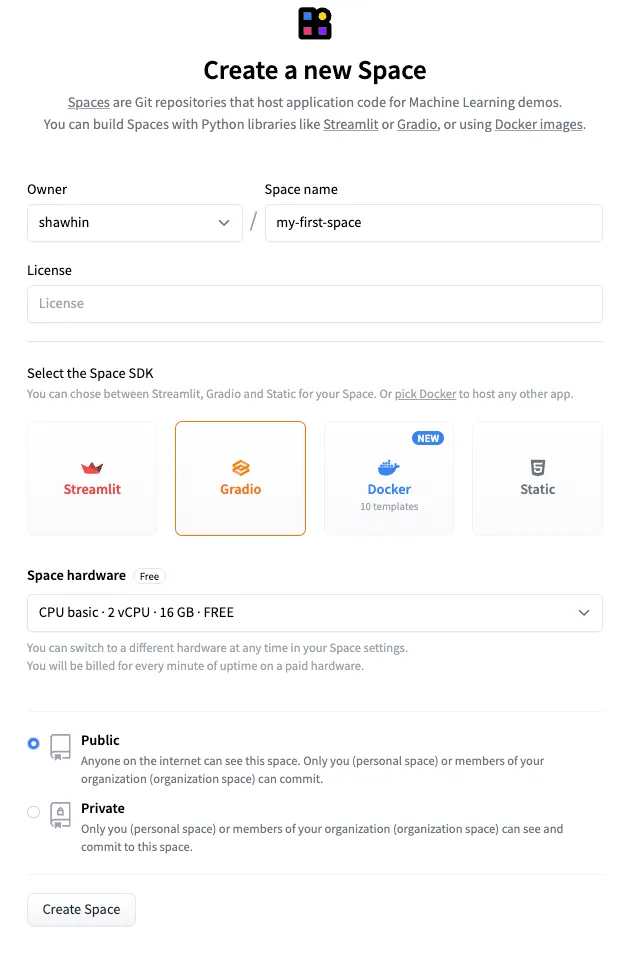
A continuación, debemos cargar los archivos app.py y requirements.txt en el Espacio. El archivo app.py contiene el código que utilizamos para generar la interfaz de usuario Gradio, y el archivo requirements.txt especifica las dependencias de la aplicación. Los archivos para este ejemplo están disponibles en el repositorio de GitHub y en el Espacio de Hugging Face.
Finalmente, subimos el código al Espacio de la misma manera que lo haríamos en GitHub. El resultado final es una aplicación pública alojada en Hugging Face Spaces.
Enlace de la aplicación: https://huggingface.co/spaces/shawhin/my-first-space
Conclusión
Hugging Face se ha convertido en sinónimo de modelos de lenguaje de código abierto y aprendizaje automático. La mayor ventaja de su ecosistema es que brinda a los desarrolladores, investigadores y aficionados de menor escala acceso a recursos de ML poderosos.
Aunque hemos cubierto mucho material en esta publicación, apenas hemos rozado la superficie de lo que el ecosistema de Hugging Face puede hacer. En futuros artículos de esta serie, exploraremos casos de uso más avanzados y cubriremos cómo afinar modelos utilizando 🤗Transformers.
👉 Más sobre LLMs: Introducción | API de OpenAI
Recursos
Conexiones: Mi sitio web | Reservar una llamada | Pregúntame cualquier cosa
Redes sociales: YouTube 🎥 | LinkedIn | Twitter
Soporte: Hazte miembro ⭐️ | Comprarme un café ☕️
Los Emprendedores de Datos
Una comunidad para emprendedores en el espacio de datos. 👉 ¡Únete a Discord!
VoAGI.com
[1] Hugging Face — https://huggingface.co/
[2] Curso de Hugging Face — https://huggingface.co/learn/nlp-course/chapter1/1
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Mejora tus fotos con IA desde la mejora de resolución HD hasta los filtros de dibujos animados
- De cero a avanzado en la ingeniería de comandos con Langchain en Python
- Conoce MovieChat un innovador sistema de comprensión de video que integra modelos fundamentales de video y grandes modelos de lenguaje.
- IA Generativa en la Salud
- V-Net, el hermano mayor de U-Net en la segmentación de imágenes
- Una Introducción Suave al Aprendizaje Profundo Bayesiano
- Olvida ChatGPT, este nuevo asistente de IA está a años luz y cambiará la forma en que trabajas para siempre






