Potenciando la equidad Reconociendo y abordando el sesgo en los modelos generativos
Abordando el sesgo en modelos generativos para fomentar la equidad.
Con la integración de la IA en nuestra vida cotidiana, un modelo sesgado puede tener consecuencias drásticas en los usuarios
En 2021, el Centro de Política de Tecnología de la Información de la Universidad de Princeton publicó un informe en el que descubrieron que los algoritmos de aprendizaje automático pueden adquirir sesgos similares a los de los humanos a partir de sus datos de entrenamiento. Un ejemplo impactante de este efecto es un estudio sobre la herramienta de contratación de IA de Amazon [1]. La herramienta se entrenó con currículums enviados a Amazon durante el año anterior y clasificaba a los diferentes candidatos. Debido al desequilibrio de género en los puestos tecnológicos durante la última década, el algoritmo había aprendido un lenguaje que se asociaba con las mujeres, como los equipos deportivos femeninos, y degradaba la clasificación de esos currículums. Este ejemplo resalta la necesidad no solo de modelos justos y precisos, sino también de conjuntos de datos que eliminen los sesgos durante el entrenamiento. En el contexto actual del rápido desarrollo de modelos generativos como ChatGPT y la integración de la IA en nuestra vida cotidiana, un modelo sesgado puede tener consecuencias drásticas y erosionar la confianza de los usuarios y la aceptación global. Por lo tanto, abordar estos sesgos es necesario desde una perspectiva empresarial y los científicos de datos (en una definición amplia) deben ser conscientes de ellos para mitigarlos y asegurarse de que estén alineados con sus principios.
Ejemplos de sesgos en modelos generativos
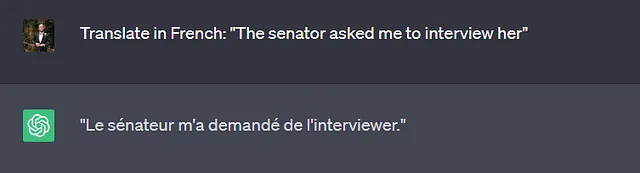
El primer tipo de tarea en la que se utilizan ampliamente los modelos generativos que viene a la mente es una tarea de traducción. Los usuarios ingresan un texto en el idioma A y esperan una traducción en el idioma B. Los diferentes idiomas no necesariamente utilizan el mismo tipo de pronombres con género, por ejemplo, “The senator” en inglés puede ser tanto femenino como masculino, mientras que en francés sería “La senatrice” o “Le senateur”. Incluso en el caso de que se especifique el género en la oración (ejemplo a continuación), no es raro que los modelos generativos refuercen los roles estereotipados de género durante la traducción.
Similar a las tareas de traducción, las tareas de generación de subtítulos requieren que el modelo genere un nuevo texto basado en alguna entrada, es decir, una traducción de una imagen a un texto. Un estudio reciente [2] analizó el rendimiento de un modelo generativo de transformador en una tarea de generación de subtítulos (figura a continuación) en el conjunto de datos “Common Objects in Context”.

El modelo generativo asignó diversas descripciones raciales y culturales a los subtítulos, a pesar de que no eran aplicables en todas las imágenes. Estos descriptores solo fueron aprendidos por los modelos generativos más nuevos y muestran un aumento en el sesgo para estos modelos. Vale la pena mencionar que los modelos de transformador también exhiben sesgos de género para este conjunto de datos, exacerbando la desproporción entre hombres y mujeres, por ejemplo, identificando a una persona como mujer dependiendo del fondo de una casa/habitación.
- Falcon AI El nuevo modelo de lenguaje grande de código abierto
- Cuando la visión por computadora funciona más como un cerebro, ve más como lo hacen las personas.
- Predecir la probabilidad de fallo de la flota de vehículos utilizando Amazon SageMaker Jumpstart
¿Por qué ocurre el sesgo?
La fase de concepción de un generativo deja mucho espacio para que se desarrolle el sesgo dentro de un modelo. Pueden surgir del propio conjunto de datos, las etiquetas y anotaciones, las representaciones internas o incluso el modelo en sí (consulte https://huggingface.co/blog/ethics-soc-4 para obtener una lista extensa centrada en modelos de texto a imagen).
Los datos necesarios para el entrenamiento de un modelo generativo provienen de múltiples fuentes, generalmente en línea. Para garantizar la integridad de los datos de entrenamiento, las empresas de IA suelen utilizar sitios web de noticias conocidos y similares para construir su base de datos. Los modelos entrenados con este conjunto de datos van a perpetuar asociaciones sesgadas debido a las restricciones demográficas que se consideran (generalmente personas blancas, de mediana edad y clase media alta).
El sesgo de etiquetado (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3994857/) es quizás el más explícito, ya que resulta en la introducción de sesgos, generalmente inadvertidos, en los datos etiquetados. Los modelos generativos se entrenan para reproducir/aproximar su conjunto de datos de entrenamiento, por lo que un sesgo en las etiquetas tendrá un impacto drástico en las representaciones de salida del modelo. Afortunadamente, el uso de múltiples versiones de la etiqueta y su verificación cruzada permite mitigar los sesgos.
Los dos últimos tipos de sesgos, las representaciones internas y los sesgos del modelo, provienen de un paso específico en el modelado. El primero se introduce en la etapa de preprocesamiento, ya sea manual o algorítmico. Esta etapa tiende a incorporar sesgos y una pérdida de matices culturales, especialmente si el conjunto de datos original carece de diversidad. El sesgo del modelo surge simplemente de una función objetivo basada en características discriminatorias y una amplificación de los sesgos para mejorar la precisión del modelo.
Detección de sesgos en modelos generativos
Como se destaca en este artículo, los sesgos en los modelos generativos se observan en diversas formas y bajo diversas condiciones. Los métodos para detectarlos deben ser tan diversos como los sesgos que intentan detectar.
Una de las principales medidas de sesgos en los modelos de lenguaje consiste en la Prueba de Asociación de Incrustación de Palabras. Esta puntuación mide la similitud, dentro de un espacio de incrustación (representación interna), entre dos conjuntos de palabras. Una puntuación alta indica una fuerte asociación. Más específicamente, calcula la diferencia de similitud entre un conjunto de palabras objetivo y dos conjuntos de entradas, por ejemplo, [casa, familia] como objetivo y [él, hombre]/[ella, mujer] como entradas. Una puntuación de 0 indicaría un modelo perfectamente equilibrado. Esta métrica se utilizó para demostrar que RoBERTa es uno de los modelos generativos más sesgados (https://arxiv.org/pdf/2106.13219.pdf).
Una forma innovadora de medir los sesgos en los modelos generativos (evaluación contrafactual) y, más específicamente, el sesgo de género, consiste en intercambiar el género de las palabras y observar el cambio de precisión en las predicciones. Si la precisión modificada y la precisión original son diferentes, esto resalta la presencia de sesgos en el modelo, ya que un modelo generativo imparcial debería ser preciso independientemente del género de las entradas. La principal limitación de esta medida es que solo captura el sesgo de género y, por lo tanto, debe complementarse con otras medidas para evaluar completamente las fuentes de sesgo. Siguiendo una idea similar, se puede utilizar la Evaluación Bilingüe de Compañeros (una medida de traducción clásica) para comparar la similitud entre la salida resultante de la entrada con el género intercambiado y la original.
Los modelos generativos actuales se basan en modelos transformadores que utilizan una característica llamada atención para predecir la salida en función de la salida. Los estudios han investigado la relación entre género y roles utilizando el puntaje de atención directamente del modelo (https://arxiv.org/abs/2110.15733). Esto permite comparar diferentes partes del modelo entre sí para detectar qué módulo contribuye más al sesgo. Si bien se ha demostrado con esta medida que los modelos generativos introducen un sesgo de género en el conjunto de datos de Wikipedia, una limitación de esta medida es que los valores de atención no representan un efecto directo y similitud entre conceptos, y requieren un análisis en profundidad para sacar conclusiones.
¿Cómo superar los sesgos en los modelos generativos?
Los investigadores han desarrollado diversas técnicas para proporcionar sistemas generativos con menos sesgos. En la mayoría de los casos, estas técnicas consisten en pasos adicionales en el modelado, como establecer una variable de control que fije el género en función de la información previa o agregar otro modelo para proporcionar información contextual. Sin embargo, todos estos pasos no abordan necesariamente el uso de conjuntos de datos inherentemente sesgados. Además, la mayoría de los modelos generativos se basan en datos de entrenamiento en inglés, lo que limita drásticamente la diversidad cultural y social de estos modelos.
Superar por completo los sesgos en los modelos generativos requeriría el establecimiento de un marco formal y puntos de referencia para probar y evaluar modelos en varios idiomas. Esto permitiría detectar los sesgos presentes de formas matizadas en diversos modelos de IA.
Referencias
- Amazon descarta herramienta de reclutamiento de IA secreta que mostraba sesgo contra las mujeres, Jeffrey Dastin, https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G
- Comprensión y evaluación de sesgos raciales en la descripción de imágenes, Dora Zhao, Angelina Wang, Olga Russakovsky, https://arxiv.org/pdf/2106.08503.pdf
¡Sígueme en VoAGI para obtener más contenido sobre Ciencia de Datos!
Si te gusta leer historias como estas y quieres apoyarme como escritor, considera suscribirte para convertirte en miembro de VoAGI. Cuesta $5 al mes y te brinda acceso ilimitado a historias en VoAGI. Si te registras usando mi enlace, recibiré una pequeña comisión.
Únete a VoAGI con mi enlace de referencia – Kevin Berlemont, PhD
Como miembro de VoAGI, una parte de tu cuota de membresía se destina a los escritores que lees, y obtienes acceso completo a cada historia…
VoAGI.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Destacar el texto mientras se está hablando utilizando Amazon Polly
- XPENG lanza el G6 Coupe SUV para el mercado general
- NVIDIA CEO, ejecutivos europeos de IA generativa discuten claves para el éxito.
- Robot se posiciona en el podio como director de orquesta en Seúl.
- Tour de France incorpora ChatGPT y tecnología de gemelos digitales.
- Casas de cuidado en Japón utilizan Big Data para impulsar a los cuidadores y aligerar las cargas de trabajo.
- Comprensión del código en tu propio hardware