Un manual para escalar MLOps.
A guide to scaling MLOps.
Los equipos de MLOps están bajo presión para mejorar sus capacidades y escalar la inteligencia artificial. Nos asociamos con Ford Motors para explorar cómo escalar MLOps dentro de una organización y cómo empezar.
Por Mike Caravetta y Brendan Kelly
Escalando MLOps para tus equipos
Los equipos de MLOps están bajo presión para avanzar en sus capacidades en el escalado de la IA. En 2022, vimos una explosión de entusiasmo en torno a la IA y MLOps dentro y fuera de las organizaciones. 2023 promete más hype con el éxito de ChatGPT y la tracción de los modelos dentro de las empresas.
Los equipos de MLOps buscan expandir sus capacidades mientras satisfacen las necesidades urgentes del negocio. Estos equipos comienzan el 2023 con una larga lista de resoluciones e iniciativas para mejorar cómo industrializan la IA. ¿Cómo vamos a escalar los componentes de MLOps (implementación, monitoreo y gobernanza)? ¿Cuáles son las principales prioridades para nuestro equipo?
- Diez años de revisión de la Inteligencia Artificial.
- El Arte de la Ingeniería de Respuesta Rápida Decodificando ChatGPT
- Empezando con ReactPy
AlignAI se asoció con Ford Motors para escribir este manual que guía a los equipos de MLOps basado en lo que hemos visto ser exitoso para escalar.
¿Qué significa MLOps?
Para comenzar, necesitamos una definición de trabajo de MLOps. MLOps es la transición de una organización de proporcionar algunos modelos de IA a proporcionar algoritmos de manera confiable a escala. Esta transición requiere un proceso repetible y predecible. MLOps significa más IA y el retorno de la inversión asociado. Los equipos ganan en MLOps cuando se centran en orquestar el proceso, el equipo y las herramientas.
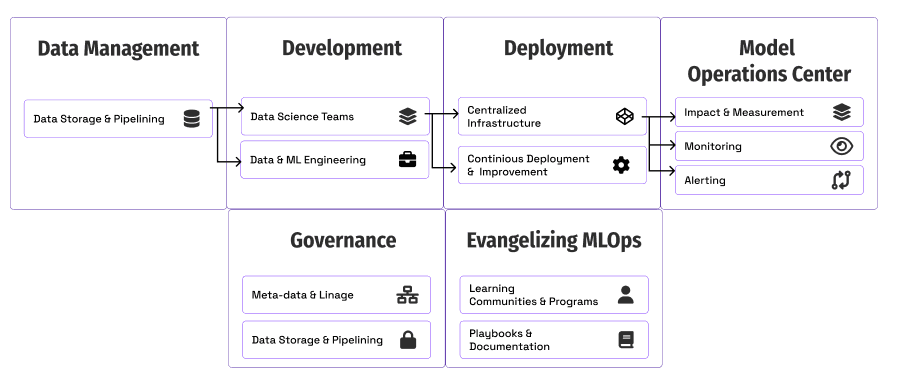
Componentes fundamentales de MLOps para escalar
Repasemos cada área con ejemplos de Ford Motors e ideas para ayudarte a comenzar.
- Medición e impacto: cómo los equipos hacen seguimiento y miden el progreso.
- Implementación e infraestructura: cómo los equipos escalan las implementaciones de los modelos.
- Monitoreo: mantenimiento de la calidad y el rendimiento de los modelos en producción.
- Gobernanza: creación de controles y visibilidad en torno a los modelos.
- Evangelizar MLOps: educar al negocio y a otros equipos técnicos sobre por qué y cómo utilizar los métodos de MLOps.
Medición e impacto
Un día, un ejecutivo de negocios entró al centro de comando de MLOps de Ford. Revisamos las métricas de uso de un modelo y tuvimos una conversación productiva sobre por qué había disminuido el uso. Esta visibilidad del impacto y la adopción de modelos es crucial para construir confianza y reaccionar a las necesidades del negocio.
Una pregunta fundamental para los equipos que aprovechan la IA e invierten en capacidades de MLOps es ¿cómo sabemos si estamos progresando?
La clave es alinear a nuestro equipo en cómo brindamos valor a nuestros clientes y partes interesadas del negocio. Los equipos se centran en cuantificar el rendimiento en el impacto empresarial que proporcionan y las métricas operativas que lo permiten. Medir el impacto captura la imagen de cómo generamos.
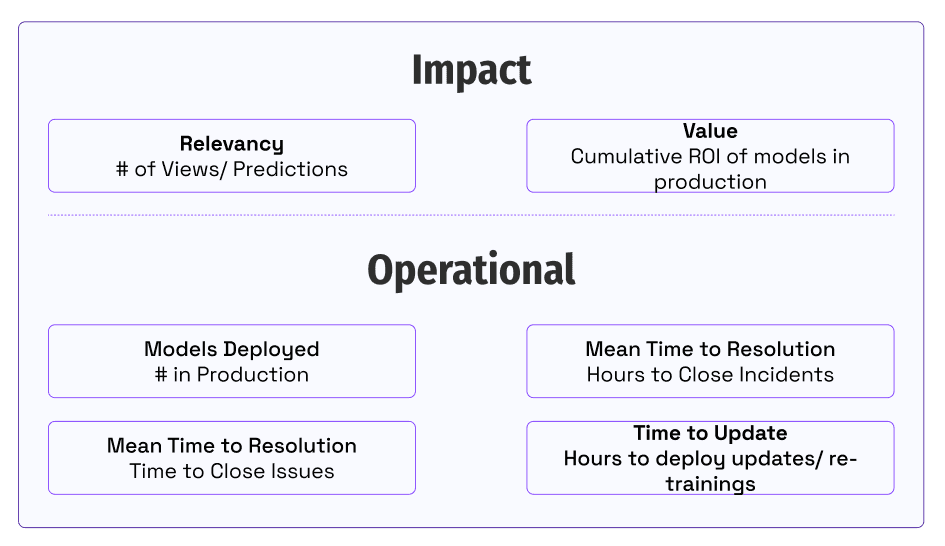
Ideas para comenzar:
- ¿Cómo mides el valor de los modelos en desarrollo o producción hoy? ¿Cómo haces seguimiento del uso y la participación de las partes interesadas del negocio?
- ¿Cuáles son las métricas operativas o de ingeniería para tus modelos en producción hoy? ¿Quién es responsable de la mejora de estas métricas? ¿Cómo das acceso a las personas para ver estas métricas?
- ¿Cómo saben las personas si hay un cambio en el comportamiento del usuario o el uso de la solución? ¿Quién responde a estos problemas?
Implementación e infraestructura
El primer obstáculo que enfrenta el equipo en MLOps es la implementación de modelos en producción. A medida que aumenta el número de modelos, los equipos deben crear un proceso estandarizado y una plataforma compartida para manejar el aumento de volumen. La gestión de 20 modelos implementados utilizando 20 patrones diferentes puede hacer las cosas engorrosas. Los equipos empresariales típicamente crean recursos de infraestructura centralizados alrededor de X modelos. Elegir la arquitectura y la infraestructura adecuadas en todos los modelos y equipos puede ser una batalla cuesta arriba. Sin embargo, una vez que se establece, proporciona una base sólida para construir las capacidades en torno al monitoreo y la gobernanza.
En Ford, creamos una función de implementación estándar utilizando Kubernetes, Google Cloud Platform y un equipo para apoyarlos.
Enlace Lucid
Ideas para tu equipo:
- ¿Cómo vas a centralizar la implementación de modelos? ¿Puedes crear o designar un equipo y recursos centralizados para gestionar las implementaciones?
- ¿Qué patrones de implementación (REST, por lotes, en continuo, etc.)?
- ¿Cómo vas a definirlos y compartirlos con otros equipos?
- ¿Cuáles son los aspectos más consumidores de tiempo o difíciles para tus equipos de modelado para superar y obtener un modelo en producción? ¿Cómo puede diseñarse el sistema de implementación centralizado para mitigar estos problemas?
Monitoreo
Un aspecto único y desafiante del aprendizaje automático es la capacidad de los modelos para cambiar y desviarse en producción. El monitoreo es fundamental para generar confianza con las partes interesadas que utilizan los modelos. Las Reglas de Aprendizaje Automático de Google dicen que se debe “practicar una buena higiene de alerta, como hacer que las alertas sean viables”. Esto requiere que los equipos definan las áreas a monitorear y cómo generar estas alertas. La parte desafiante es hacer que estas alertas sean viables. Debe haber un proceso establecido para investigar y mitigar problemas en producción.

En Ford, el Centro de Operaciones de Modelo es el lugar centralizado con pantallas llenas de información y datos para entender si los modelos están obteniendo lo que esperamos en tiempo casi real.
Aquí hay un ejemplo simplificado de un panel de control que busca que el uso o el recuento de registros no caiga por debajo de un umbral establecido.
Métricas de Monitoreo
Aquí hay métricas de monitoreo a considerar para sus modelos:
- Latencia: Tiempo para devolver predicciones (por ejemplo, tiempo de procesamiento por lotes para 100 registros).
- Rendimiento estadístico: la capacidad de un modelo para hacer predicciones correctas o cercanas dada un conjunto de datos de prueba (por ejemplo, Error Cuadrático Medio, F2, etc.).
- Calidad de los datos: cuantificación de la completitud, precisión, validez y puntualidad de la predicción o los datos de entrenamiento. (por ejemplo, % de registros de predicción que faltan una característica).
- Desviación de datos: cambios en la distribución de datos con el tiempo (por ejemplo, cambios de iluminación para un modelo de visión por computadora).
- Uso del modelo: con qué frecuencia se utilizan las predicciones del modelo para resolver problemas empresariales o de usuario (por ejemplo, # de predicciones para el modelo implementado como un punto final REST).
Ideas para su equipo:
- ¿Cómo se deben monitorear todos los modelos?
- ¿Qué métricas deben incluirse con cada modelo?
- ¿Existe una herramienta o marco estándar para generar las métricas?
- ¿Cómo vamos a manejar las alertas y problemas de monitoreo?
Gobernanza
La innovación inherentemente crea riesgos, especialmente en el entorno empresarial. Por lo tanto, liderar la innovación con éxito requiere diseñar controles en los sistemas para mitigar el riesgo. Ser proactivo puede ahorrar muchos dolores de cabeza y tiempo. Los equipos de MLOps deben anticipar y educar proactivamente a las partes interesadas sobre los riesgos y cómo mitigarlos.
Desarrollar un enfoque proactivo para la gobernanza ayuda a evitar reaccionar a las necesidades del negocio. Dos piezas clave de la estrategia son controlar el acceso a los datos sensibles y capturar la linaje y los metadatos para visibilidad y auditoría.
La gobernanza ofrece grandes oportunidades para la automatización a medida que los equipos crecen. La espera de datos es un asesino constante del impulso en proyectos de ciencia de datos. En Ford, un modelo determina automáticamente si hay información de identificación personal en un conjunto de datos con un 97% de precisión. Los modelos de aprendizaje automático también ayudan con las solicitudes de acceso y han reducido el tiempo de procesamiento de semanas a minutos en el 90% de los casos.
La otra pieza es el seguimiento de los metadatos a lo largo del ciclo de vida del modelo. Escalar el aprendizaje automático requiere escalar la confianza en los propios modelos. MLOps a escala requieren calidad incorporada, seguridad y control para evitar problemas y sesgos en producción.
Los equipos pueden quedar atrapados en la teoría y las opiniones en torno a la gobernanza. El mejor curso de acción es comenzar con un acceso claro y controles en torno al acceso del usuario.
A partir de ahí, la captura de metadatos y la automatización son clave. La tabla a continuación describe las áreas para recopilar metadatos. En la medida de lo posible, aproveche los sistemas de canalización u otra automatización para capturar esta información automáticamente y evitar el procesamiento manual e inconsistencias.
Metadatos a recopilar
Aquí están los elementos a recopilar para cada modelo:
- Artefacto de modelo entrenado / Versión: Identificador único del artefacto de modelo entrenado.
- Datos de entrenamiento: datos utilizados para crear el artefacto de modelo entrenado.
- Código de entrenamiento: hash de Git o enlace al código fuente para inferencia.
- Dependencias: bibliotecas utilizadas en el entrenamiento.
- Código de predicción: hash de Git o enlace al código fuente para inferencia.
- Predicciones históricas: almacenar inferencias para fines de auditoría.
Ideas para su equipo:
- ¿Qué problemas hemos encontrado en proyectos anteriores?
- ¿Qué problemas están experimentando o preocupando a nuestras partes interesadas empresariales?
- ¿Cómo manejamos las solicitudes de acceso a los datos?
- ¿Quién los aprueba?
- ¿Existen oportunidades de automatización?
- ¿Qué vulnerabilidades crean nuestras canalizaciones o implementaciones de modelos?
- ¿Qué piezas de metadatos necesitamos capturar?
- ¿Cómo se almacena y se pone a disposición?
Evangelizando MLOps
Muchos equipos técnicos caen en la trampa de pensar: “si lo construimos, vendrán”. Resolver el problema implica más que eso. También implica compartir y promover la solución para aumentar el impacto organizacional. Los equipos de MLOps necesitan compartir las mejores prácticas y cómo resolver los problemas únicos de las herramientas, datos, modelos y partes interesadas de su organización.
Cualquier persona en el equipo de MLOps puede ser un evangelista al asociarse con las partes interesadas del negocio para mostrar sus historias de éxito. Mostrar ejemplos de su organización puede ilustrar claramente los beneficios y oportunidades.
Las personas en toda la organización que buscan industrializar la IA necesitan educación, documentación y otro tipo de apoyo. Las sesiones de almuerzo y aprendizaje, la integración y los programas de mentoría son excelentes lugares para comenzar. A medida que su organización crece, los programas de aprendizaje y integración más formalizados con documentación de apoyo pueden acelerar la transformación de su organización.
Ideas para su equipo:
- ¿Cómo puede crear una comunidad o enseñanzas recurrentes y las mejores prácticas para MLOps?
- ¿Cuáles son los nuevos roles y capacidades que necesitamos establecer y compartir?
- ¿Qué problemas hemos resuelto que podemos compartir?
- ¿Cómo está proporcionando formación o documentación para compartir las mejores prácticas e historias de éxito con otros equipos?
- ¿Cómo podemos crear programas de aprendizaje o listas de verificación para que los científicos de datos, ingenieros de datos y partes interesadas del negocio aprendan a trabajar con modelos de IA?
Empezando
Los equipos y líderes de MLOps enfrentan una montaña de oportunidades mientras equilibran las necesidades urgentes de industrializar los modelos. Cada organización enfrenta diferentes desafíos, dados sus datos, modelos y tecnologías. Si MLOps fuera fácil, probablemente no nos gustaría trabajar en el problema.
El desafío siempre es la priorización.
Esperamos que este playbook haya ayudado a generar nuevas ideas y áreas para que su equipo explore. El primer paso es generar una gran lista de oportunidades para su equipo en 2023. Luego, priorícelas sin piedad en función de lo que tendrá el mayor impacto en sus clientes. Los equipos también pueden definir y medir su progreso de madurez frente a los puntos de referencia emergentes. Esta guía de Google puede proporcionar un marco y hitos de madurez para su equipo.
Ideas para su equipo:
- ¿Cuáles son las mayores oportunidades para avanzar en nuestra madurez o sofisticación con MLOps?
- ¿Cómo capturamos y seguimos nuestro progreso en los proyectos que avanzan la madurez?
- Genere una lista de tareas para esta guía y su equipo. Priorice según el tiempo de implementación y el beneficio esperado. Cree una hoja de ruta.
Referencias
- https://www2.deloitte.com/content/dam/insights/articles/7022_TT-MLOps-industrialized-AI/DI_2021-TT-MLOps-industrialized-AI.pdf
- https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- https://developers.google.com/machine-learning/guides/rules-of-ml
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Mike Caravetta ha entregado cientos de millones de dólares en valor empresarial utilizando análisis. Actualmente lidera la carga para escalar MLOps en la reducción de complejidad y manufactura en Ford. Brendan Kelly, cofundador de AlignAI, ha ayudado a docenas de organizaciones a acelerar MLOps en las industrias bancarias, de servicios financieros, manufactura y seguros.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Convierta ideas en música con MusicLM.
- Potenciando la búsqueda con inteligencia artificial generativa
- Presentando PaLM 2
- Presentamos Project Gameface un ratón de juego sin manos impulsado por inteligencia artificial.
- 100 cosas que anunciamos en I/O 2023.
- Una agenda de políticas para el progreso responsable de la inteligencia artificial Oportunidad, Responsabilidad, Seguridad.
- Casos de uso revolucionarios de IA en la industria logística





