Una guía completa para empezar su propio Homelab para análisis de datos.
'A complete guide to starting your own Homelab for data analysis.'
Nunca ha habido un mejor momento para iniciar tu laboratorio de ciencia de datos en casa para analizar datos útiles, almacenar información importante o desarrollar tus propias habilidades tecnológicas.
Hay una expresión que he leído en Reddit algunas veces en diferentes subreddits enfocados en tecnología que dice algo así como “Pagar por servicios en la nube es simplemente alquilar la computadora de otra persona”. Si bien creo que la informática y el almacenamiento en la nube pueden ser extremadamente útiles, este artículo se centrará en algunas de las razones por las que he trasladado mis análisis, almacenamiento y herramientas lejos de los proveedores en línea y hacia mi oficina en casa. También se encuentra disponible un enlace a las herramientas y hardware que usé para hacer esto.
Introducción
La mejor manera de empezar a explicar el método de mi locura es compartiendo un problema empresarial con el que me encontré. Si bien soy un inversor bastante tradicional con una baja tolerancia al riesgo, hay una pequeña esperanza dentro de mí de que tal vez, solo tal vez, pueda ser uno de los menos del 1% que vence al S&P 500. Tengan en cuenta que usé la palabra “esperanza” y, como tal, no arriesguen demasiado en esta esperanza. Unas pocas veces al año le doy a mi cuenta de Robinhood $100 y la trato con tanto respeto como trato un billete de lotería, esperando ganar mucho. Pongo a los adultos en la habitación a gusto compartiendo que esta cuenta está separada de mis cuentas más grandes que se basan principalmente en fondos indexados con retornos modestos regulares con algunas acciones de valor en las que vendo opciones cubiertas de forma constante. Sin embargo, mi cuenta de Robinhood es un juego de azar borderline degenerado y cualquier cosa puede pasar. Aunque tengo algunas reglas para mí mismo:
- Nunca tomo margen.
- Nunca vendo al descubierto, solo compro para abrir.
- No gasto dinero persiguiendo operaciones perdedoras.
Pueden preguntarse hacia dónde voy con esto, y me alejaré de mi tangente compartiendo que mis “billetes de lotería” que, lamentablemente, aún no me han ganado un yate digno de Jeff Bezos, pero me han enseñado mucho sobre el riesgo y la pérdida. Estas lecciones también han inspirado al entusiasta de los datos dentro de mí a intentar mejorar la forma en que cuantifico el riesgo y trato de anticipar las tendencias y eventos del mercado. Incluso los modelos direccionales correctos a corto plazo pueden proporcionar un valor tremendo a los inversores, tanto minoristas como de cobertura.
El primer paso que vi hacia la mejora de mi toma de decisiones fue tener datos disponibles para tomar decisiones basadas en datos. La eliminación de la emoción de la inversión es un consejo de éxito bien conocido. Si bien los datos históricos están ampliamente disponibles para acciones y ETF y están abiertos a través de recursos de código abierto como yfinance (un ejemplo mío se encuentra a continuación), los conjuntos de datos históricos derivados son mucho más costosos y difíciles de conseguir. Algunas miradas iniciales a las API disponibles dieron pistas de que el acceso regular y rutinario a los datos para backtesting estrategias para mi cartera podría costarme cientos de dólares anualmente, y posiblemente incluso mensualmente dependiendo de la granularidad que estaba buscando.
- Motivando la Autoatención
- 10 hiperparámetros confusos de XGBoost y cómo ajustarlos como un profesional en 2023.
- Cinco fuentes de datos meteorológicos gratuitas y confiables.
Graficando datos financieros y múltiples tendencias superpuestas usando Python y Plotly
Plotly ofrece a los desarrolladores de Python flexibilidad para utilizar gráficos de velas y una variedad de otras herramientas de graficación para modelar…
wire.insiderfinance.io
Decidí que prefería invertir en mí mismo en este proceso y gastar cientos de dólares en mis propios términos. *El público se queja*
Construyendo en la nube
Mis primeros pensamientos sobre la extracción y almacenamiento de datos me llevaron a las mismas herramientas que uso diariamente en mi trabajo. Creé una cuenta personal de AWS y escribí scripts en Python para implementar en Lambda y extraer conjuntos de datos de opciones gratuitos y en vivo en intervalos predeterminados y escribir los datos en mi nombre. Este era un sistema completamente automatizado y casi infinitamente escalable, porque un scraper diferente se generaría dinámicamente para cada ticker en mi cartera. Escribir los datos fue más desafiante, y estaba entre dos opciones. Podía escribir los datos en S3, analizarlos con Glue y analizarlos con consultas sin servidor en Athena, o podía usar un servicio de base de datos relacional y escribir directamente mis datos desde Lambda en RDS.
Una rápida descripción de las herramientas de AWS mencionadas:
Lambda es la computación sin servidor que permite a los usuarios ejecutar scripts sin mucha sobrecarga y con un generoso nivel gratuito.
S3, también conocido como servicio de almacenamiento simple, es un sistema de almacenamiento de objetos con un amplio nivel gratuito y un almacenamiento extremadamente rentable a $0.02 por GB por mes.
Glue es una herramienta de preparación de datos, integración y ETL de AWS con rastreadores web disponibles para leer e interpretar datos tabulares.
Athena es una arquitectura de consulta sin servidor.
Terminé inclinándome hacia RDS solo para tener los datos fácilmente consultables y monitoreables, si es por ninguna otra razón. También tenían un nivel gratuito disponible de 750 horas gratis, así como 20 GB de almacenamiento, dándome un buen sandbox para ensuciarme las manos.
Pero no me di cuenta de lo grandes que son los datos de las opciones de acciones. Empecé a escribir alrededor de 100 MB de datos por símbolo por mes en intervalos de 15 minutos, lo que puede no parecer mucho, pero considerando que tengo una cartera de 20 símbolos, antes del final del año habría usado todo el nivel gratuito. Además, la capacidad de computación pequeña dentro del nivel gratuito fue rápidamente consumida, y mi servidor consumió todas las 750 horas antes de que me diera cuenta (considerando que quería rastrear operaciones de opciones durante aproximadamente 8 horas al día, 5 días a la semana). También frecuentemente leía y analizaba datos después del trabajo en mi trabajo diario, lo que llevó a un mayor uso. Después de unos dos meses, terminé mi asignación de nivel gratuito y recibí mi primera factura de AWS: alrededor de $60 al mes. Tenga en cuenta que una vez que finaliza el nivel gratuito, está pagando por cada hora de procesamiento del servidor, una cantidad por GB fuera del ecosistema de AWS a mi máquina de desarrollo local y un costo de almacenamiento en GB/mes. Anticipé que dentro de un mes o dos mis costos de propiedad podrían aumentar al menos un 50% o más, y continuar así.

Dejando la Nube
En este punto, me di cuenta de que preferiría tomar esos $60 al mes que estoy gastando en alquilar equipos de Amazon, y gastarlos en facturas de electricidad y poner lo que queda en mi cuenta de Robinhood, donde comenzamos. Por mucho que me encanta usar las herramientas de AWS, cuando mi empleador no está pagando la factura (y para mis compañeros de trabajo que leen esto, prometo que también soy frugal en el trabajo), realmente no tengo mucho interés en invertir en ellas. AWS simplemente no está fijado en el punto para los aficionados. Ofrecen muchos recursos gratuitos excelentes para que los novatos aprendan, y una gran relación calidad-precio profesionalmente, pero no en este nivel intermedio actual.
Tenía una vieja laptop Lenovo Y50-70 de antes de la universidad con una pantalla rota que pensé en reutilizar como un bot de raspado web y servidor SQL en casa. Aunque todavía pueden obtener un precio decente nuevos o certificados como reformados (probablemente debido al procesador i7 y la tarjeta gráfica dedicada), mi pantalla rota básicamente totalizó el valor de la computadora, y conectarla como un servidor le dio nueva vida, y alrededor de tres años de polvo. Lo configuré en la esquina de mi sala de estar encima de un altavoz (junto a un gnomo) y frente a mi PlayStation y lo puse en “siempre encendido” para cumplir con su nuevo propósito. Incluso mi novia dijo que la luz roja molesta de las teclas de la computadora incluso “unía la habitación” por lo que vale.

Convenientemente, mi TV certificada como jugable de Call of Duty de 65″ estaba a una distancia de cable HDMI de la laptop para ver realmente el código que estaba escribiendo.
Migré mi servidor de la nube a mi laptop destartalada y estaba listo para empezar. ¡Ahora podía realizar todo el análisis que quería por el costo de la electricidad, o alrededor de $0.14/kWh, o alrededor de $0.20–0.30 al día. Por otro mes o dos, jugueteé y ajusté localmente. Por lo general, esto se vería como unas pocas horas a la semana después del trabajo de abrir mi MacBook, jugar con modelos de ML con datos de mi gnomo-altavoz-servidor, visualizar datos en paneles locales de Plotly y luego dirigir mis inversiones de Robinhood.
Experimenté cierto éxito limitado. Guardaré los detalles para otro post de Zepes una vez que tenga más datos y métricas de rendimiento para compartir, pero decidí que quería expandirme desde un portátil roto a mi propia micro nube. Esta vez, no alquilada, sino propia.
Construyendo el laboratorio en casa
“Home Lab” es un nombre que suena realmente complicado y genial * empuja las gafas *, pero en realidad es relativamente sencillo cuando se deconstruye. Básicamente, había algunos desafíos que buscaba abordar con mi configuración de portátil roto que proporcionaban motivación, así como nuevos objetivos y cosas agradables de tener que proporcionaban inspiración.
Problemas del portátil roto:
El disco duro era antiguo, al menos de 5 o 6 años, lo que suponía un riesgo de posibles pérdidas de datos futuras. También se ralentizaba significativamente bajo presión con consultas más grandes, un problema notado con el modelo.
Tener que usar mi televisor y teclado Bluetooth para usar mi portátil con Windows 10 Home instalado era muy incómodo y no era ergonómico.
El portátil no era actualizable en caso de que quisiera agregar más RAM más allá de lo que ya había instalado.
La tecnología estaba limitada en paralelizar tareas.
El portátil solo no era lo suficientemente fuerte como para alojar mi servidor SQL, así como paneles de control y números de crujido para mis modelos de ML. Tampoco me sentiría cómodo compartiendo los recursos en la misma computadora, disparando los otros servicios en los pies.
Un sistema que implementaría tuvo que resolver cada uno de estos problemas, pero también había nuevas características que me gustaría lograr.
Nuevas características planificadas:
Una nueva configuración de oficina en casa para hacer que trabajar desde casa de vez en cuando sea más cómodo.
Cableado Ethernet en todo mi apartamento (si estoy pagando por todo el gigabit, voy a usar todo el gigabit de AT&T).
Computación distribuida* con microservidores cuando sea apropiado.
Los servidores serían capaces de ser actualizados e intercambiados.
Programas y software diferentes desplegables para lograr diferentes subobjetivos de manera independiente y sin impedir programas actuales o paralelos.
*La computación distribuida con las computadoras que elegí es un tema debatido que se explicará más adelante en el artículo.
Pasé bastante tiempo investigando sobre configuraciones de hardware apropiadas. Uno de mis recursos favoritos que leí fue “Project TinyMiniMicro”, que comparó la plataforma Lenovo ThinkCentre Tiny, la plataforma HP ProDesk/EliteDesk Mini y la plataforma Dell OptiPlex Micro. Yo también he usado computadoras de placa única antes como los autores de Project TMM, y tengo dos Raspberry Pis y un Odroid XU4.
Lo que me gustó de mis Pis:
Eran pequeñas, consumían poca energía y los nuevos modelos tienen 8 GB de RAM.
Lo que me gustó de mi Odroid XU4:
Es pequeño, tiene 8 núcleos y es una plataforma de emulación genial.
Aunque estoy seguro de que mis SBCs todavía encontrarán un hogar en mi homelab, recuerda, necesito equipos que manejen los servicios que quiero alojar. También terminé comprando probablemente el pedido más caro de Amazon de toda mi vida y rediseñé por completo toda mi oficina. Mi carrito de compras incluyó:
- Múltiples cables Ethernet Cat6
- Herramienta de engarce RJ45
- Bridas
- 2 Mini EliteDesk 800 G1 i5 (pero me enviaron G2 #Win)
- 1 Mini EliteDesk 800 G4 i7 (y me enviaron un procesador i7 aún mejor #Win)
- 2 Mini ProDesk 600 G3 i5 (y me enviaron un i5 ligeramente peor #Karma)
- RAM extra
- Múltiples SSD
- Un nuevo escritorio de oficina para reemplazar mi credenza/runner
- Nueva iluminación de oficina
- Equipo de clonación de disco duro
- Dos interruptores de red de 8 puertos
- Un suministro de energía ininterrumpida
- Una impresora
- Un teclado mecánico (relacionado, también tengo cinco combinaciones de teclado y ratón de las computadoras si alguien quiere uno)
- Dos monitores nuevos
Si desea ver mi lista completa de piezas con enlaces a cada artículo para verificarlo o hacer una compra para usted, no dude en visitar mi sitio web para obtener una lista completa.
Una vez que mi Navidad-en-verano llegó con una gran cantidad de cajas en mi puerta, la diversión real podía comenzar. El primer paso fue terminar de cablear mi ethernet en toda mi casa. Los instaladores no habían conectado ningún cable ethernet a la caja de cable por defecto, así que tuve que cortar los extremos e instalar los enchufes yo mismo. Afortunadamente, el KIT IMPRESIONANTE que compré (enlace en mi sitio) incluía la herramienta de engarce, los extremos RJ45 y el equipo de prueba para asegurarme de que había cableado los extremos correctamente y para identificar qué puerto alrededor de mi apartamento se correlacionaba con qué cable. Por supuesto, con mi suerte, el último de los 8 cables terminó siendo el que necesitaba para mi oficina, pero supongo que los futuros inquilinos de mi lugar se beneficiarán de mi buena acción del día. Todo el proceso tomó alrededor de 2-3 horas de cableado de las conexiones gigabit, pero afortunadamente, mi novia disfrutó ayudar y una copa de vino hizo que fuera más rápido.
Después de la red cableada, comencé a configurar mi oficina construyendo los muebles, instalando la iluminación y desempaquetando el hardware. Mi configuración de escritorio resultó bastante limpia, y estoy contento con cómo se ve mi oficina ahora.


En cuanto a mi configuración de hardware, cada una de las computadoras que compré tenía 16GB de RAM que actualicé a 32, así como unidades de estado sólido (unas cuantas que actualicé). Como cada dispositivo está ejecutando Windows 10 Pro, puedo iniciar sesión remota en mi red y ya configuré algunos de mis servicios. La interconexión de los dispositivos también fue bastante divertida, aunque creo que mi gestión de cables deja un poco que desear.




Ahora, con el asterisco que tenía al principio, ¿por qué gasté alrededor de un año de costos de AWS en cinco computadoras con alrededor de 22 núcleos en total en lugar de simplemente comprar/construir una PC moderna y equipada? Bueno, hay algunas razones, y estoy seguro de que esto puede ser divisivo con algunos de los otros geeks de la tecnología en la habitación.
- Escala: puedo agregar fácilmente otro nodo a mi clúster aquí o quitar uno para mantenimiento/actualizaciones.
- Costo: es fácil y económico actualizar y mantener. Además, con alrededor de 35W como máximo para la mayoría de las unidades, el costo de ejecutar mis servidores es muy asequible.
- Redundancia: si un nodo se cae (es decir, una CPU muere), tengo scripts de corrección para equilibrar mis cargas de trabajo distribuidas.
- Educación: estoy aprendiendo una cantidad significativa que mejora mis habilidades y experiencia profesionales, y la educación es ✨invaluable✨.
- Se ve genial. El punto número 5 aquí debería ser suficiente justificación por sí solo.
Hablando de educación, aquí hay algunas cosas que aprendí e implementé en mi clúster:
- Cuando se clonan unidades de menor a mayor tamaño, es necesario ampliar los volúmenes de la nueva unidad, lo que con frecuencia requiere software de terceros para hacerlo fácilmente (como Paragon).
- Debe asignar manualmente direcciones IP estáticas para obtener resultados confiables al conectarse de forma remota entre escritorios.
- Cuando se migran servidores SQL, es más fácil restaurar desde una copia de seguridad que consultar entre dos servidores diferentes.
Estoy seguro de que habrá muchas más lecciones que aprenderé en el camino…
A continuación se muestra un diagrama aproximado de mi red doméstica ahora. No se muestran mis dispositivos wifi como mi MacBook y mi teléfono, pero saltan entre los dos enrutadores mostrados. Eventualmente, también agregaré mis computadoras de placa única y posiblemente una PC más al conjunto. ¡Ah, sí, y mi vieja computadora portátil con pantalla rota! Nadie quiso comprarla en Marketplace de Facebook ni siquiera por $50, así que instalé Windows 10 Pro en ella para acceso remoto y la agregué al conjunto también por si acaso, y eso realmente podría ser algo bueno porque puedo usar su GPU para ayudar en la construcción de modelos de Tensorflow (y también jugar algunos juegos por turnos).
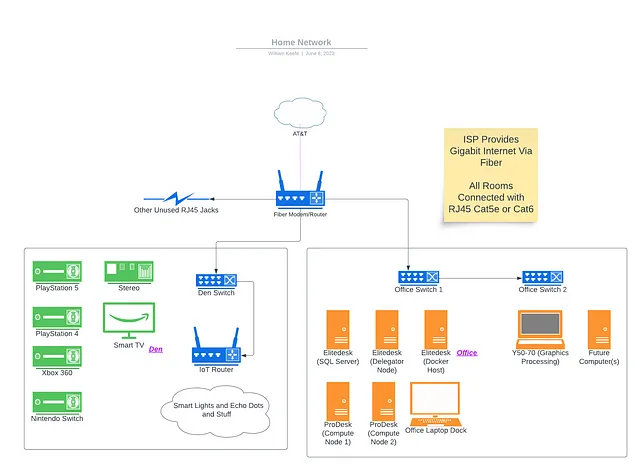
Hablando de Tensorflow, aquí hay algunos de los servicios y funciones que implementaré en mi nuevo laboratorio doméstico:
- El servidor SQL (actualmente alojando mis conjuntos de datos financieros, así como nuevos conjuntos de datos que estoy raspando de la web y que luego escribiré, incluidas las finanzas de mi alma mater y los conjuntos de datos de seguridad pública de la ciudad en la que vivo)
- Docker (para alojar aplicaciones/contenedores que construiré, así como un servidor de Minecraft, porque, ¿por qué no?)
- Sistema Jenkins CI/CD para construir, entrenar e implementar modelos de aprendizaje automático en mis conjuntos de datos
- Repositorio Git para mi base de código personal
- Almacenamiento conectado a la red que admite muchas fotos de mi hobby de fotografía, documentos y cualquier otra actividad de almacenamiento de datos
- Y otros proyectos/servicios por determinar
Pensamientos finales:
¿Valió la pena? Bueno, hay un elemento de “solo el tiempo lo dirá”. Una vez que mi tarjeta de crédito se enfríe de mis compras de cumplimiento de Amazon, estoy seguro de que también disfrutará del alivio de los precios de AWS. También estoy emocionado de poder construir e implementar más de mis hobbies, así como recopilar más datos para escribir más artículos de Zepes. Algunos de mis próximos artículos planificados incluyen un análisis de la deuda que enfrenta actualmente la Universidad de West Virginia en términos financieros, así como un análisis exploratorio de datos del informe de seguridad pública de Nashville (y posiblemente un modelo de aprendizaje automático para anticipar eventos de emergencia y asignar necesidades de recursos). Estos proyectos de ciencia de datos son lo suficientemente grandes como para que no sean posibles sin algún tipo de arquitectura para almacenar y consultar la gran cantidad de datos relacionados.
¿Qué piensas? ¿Dejar la nube y construir un laboratorio doméstico suena como un proyecto que te gustaría hacer? ¿Cuál sería tu elección de hardware?
Si tienes curiosidad sobre el hardware que utilicé, echa un vistazo a mis reseñas en www.willkeefe.com
Algunos de mis contenidos recientes relacionados de Zepes:
Planificación de producción y gestión de recursos de sistemas de fabricación en Python
Las cadenas de suministro eficientes, la planificación de producción y la gestión de asignación de recursos son más importantes que nunca. Python…
towardsdatascience.com
Análisis y predicción de la ubicación del delito usando Python y aprendizaje automático
Usando Python, Folium y ScyPy, se pueden construir modelos para ilustrar incidentes delictivos, calcular las mejores ubicaciones para…
towardsdatascience.com
¡Conéctate conmigo en LinkedIn también!
https://www.linkedin.com/in/will-keefe-476016127/
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Lo que aprendí al llevar la Ingeniería de Prompt al límite
- Los modelos de lenguaje grandes tienen sesgos. ¿Puede la lógica ayudar a salvarlos?
- Aprendiendo a hacer crecer modelos de aprendizaje automático
- Uniéndose a la lucha contra el sesgo en la atención médica
- Los investigadores del MIT hacen que los modelos de lenguaje sean autoaprendices escalables.
- La IA se está comiendo la Ciencia de Datos.
- Hoja de ayuda de Bard para Ciencia de Datos




