Learn more about Search Results la distancia entre embeddings

- You may be interested
- Un paso hacia pilotos automáticos segur...
- Investigadores de Microsoft presentan H...
- Rendimiento máximo de IA las últimas ac...
- La Prueba de Alex Hormozi para Ideas de...
- Impulsando la innovación herramientas c...
- Iniciar un canal de YouTube sin rostro ...
- Este artículo de IA revela las implicac...
- Google AI presenta Visually Rich Docume...
- Parte 1 Crear paso a paso un entorno vi...
- Gráfico de barras agrupadas con barras ...
- Aprendizaje de operadores a través de D...
- Optimización del controlador PID Un enf...
- Engañando a los clasificadores forenses...
- Convirtiendo viejos mapas en modelos di...
- Una introducción a la estimación estadí...

¿Cómo las bases de datos vectoriales dan forma al futuro de las soluciones de IA generativa?
Introducción En el paisaje en constante evolución de la IA generativa, el papel fundamental de las bases de datos de vectores se ha vuelto…

Las mejores 15 bases de datos vectoriales para la ciencia de datos en 2024 una guía completa
Introducción En el paisaje en constante evolución de la ciencia de datos, las bases de datos vectoriales juegan un papel fundamental en permitir el…

Volviendo la primavera AI y OpenAI GPT útiles con RAG en tus propios documentos
Descubre cómo usar RAG para mejorar tu experiencia de búsqueda de documentos con Spring AI y OpenAI GPT. Aprende cómo hacer que tus propios…

Explora las relaciones semánticas en textos de corpora con modelos de embedding
Recientemente he hablado con varios compañeros de estudios e investigadores cuyos intereses de investigación involucran el análisis de texto libre. Desafortunadamente, para todos, obtener…

La nueva función de diseño de Amazon Textract introduce eficiencias en tareas de procesamiento de documentos de inteligencia artificial generales y generativos.
Amazon Textract es un servicio de aprendizaje automático (ML) que extrae automáticamente texto, escritura a mano y datos de cualquier documento o imagen. AnalyzeDocument…

Una Nueva Era de Generación de Texto RAG, LangChain y Bases de Datos Vectoriales
Introducción Técnicas innovadoras continúan dando forma a cómo las máquinas entienden y generan lenguaje humano en el cambiante panorama de procesamiento de lenguaje natural.…

Modelado de temas en producción
En el artículo anterior, discutimos cómo realizar la Modelización de Temas utilizando ChatGPT y obtuvimos excelentes resultados. La tarea consistía en analizar las opiniones…

Construye un RAG Pipeline con el Índice LLama
Introducción Una de las aplicaciones más populares de los modelos de lenguaje grandes (LLMs, por sus siglas en inglés) es responder preguntas sobre conjuntos…

Apache SeaTunnel, Milvus y OpenAI mejoran la precisión y eficiencia de la búsqueda de similitud de títulos de libros’.
Utilizando Apache SeaTunnel, Milvus y OpenAI, podemos lograr búsquedas de similitud de títulos de libros más precisas a través de modelos de lenguaje extensos.

Introducción a la Reidentificación de Personas
La reidentificación de personas es un proceso que identifica a individuos que aparecen en diferentes vistas de cámaras que no se superponen. Este proceso…

10 Temas populares que llegarán a ODSC West 2023
¡ODSC West está a menos de un mes de distancia! Prepárate para más de 300 horas de sesiones prácticas de capacitación, talleres y charlas…

Word Embeddings Dando contexto a tu ChatBot para obtener mejores respuestas
Aprende cómo construir un bot experto utilizando incrustaciones de palabras y ChatGPT. Aprovecha el poder de los vectores de palabras para mejorar las respuestas…
Temas por Clase Utilizando BERTopic
Tenemos cientos de miles de textos. Tomaría años leerlos todos y obtener algunas ideas. Afortunadamente, hay muchas herramientas de ciencia de datos que podrían…

Encontrar agujas en un pajar índices de búsqueda para la similitud de Jaccard
Las bases de datos vectoriales están en las noticias por ser la memoria externa de los grandes modelos de lenguaje (LLMs). Las bases de…

Consulta tus DataFrames con potentes modelos de lenguaje grandes utilizando LangChain.
En el artículo anterior, expliqué cómo utilizar una base de datos de vectores como ChromaDB para almacenar información y utilizarla para crear una sugerencia…

NLP moderno Una descripción detallada. Parte 3 BERT
En mis artículos anteriores sobre transformadores y GPTs, hemos realizado un análisis sistemático de la línea de tiempo y desarrollo de NLP. Hemos visto…
Aproveche el poder de las bases de datos vectoriales influenciando los modelos de lenguaje con información personalizada.
En este artículo, aprenderemos sobre cómo dos nuevas tecnologías bases de datos vectoriales y modelos de lenguaje grandes, pueden trabajar juntas. Esta combinación está…

Comenzando con Embeddings
Echa un vistazo a este tutorial con el compañero de cuaderno: Comprendiendo los embeddings Un embedding es una representación numérica de una pieza de…
Agentes Orientados a Documentos Un Viaje con Bases de Datos Vectoriales, LLMs, Langchain, FastAPI y Docker
Aprovechando ChromaDB, Langchain y ChatGPT Respuestas mejoradas y fuentes citadas de grandes bases de datos de documentos.

Cómo convertí una base de datos relacional regular en una base de datos vectorial para almacenar incrustaciones
En este artículo, te guiaré en cómo convertir un RDBMS regular en una base de datos vectorial completamente funcional para almacenar incrustaciones para desarrollar…
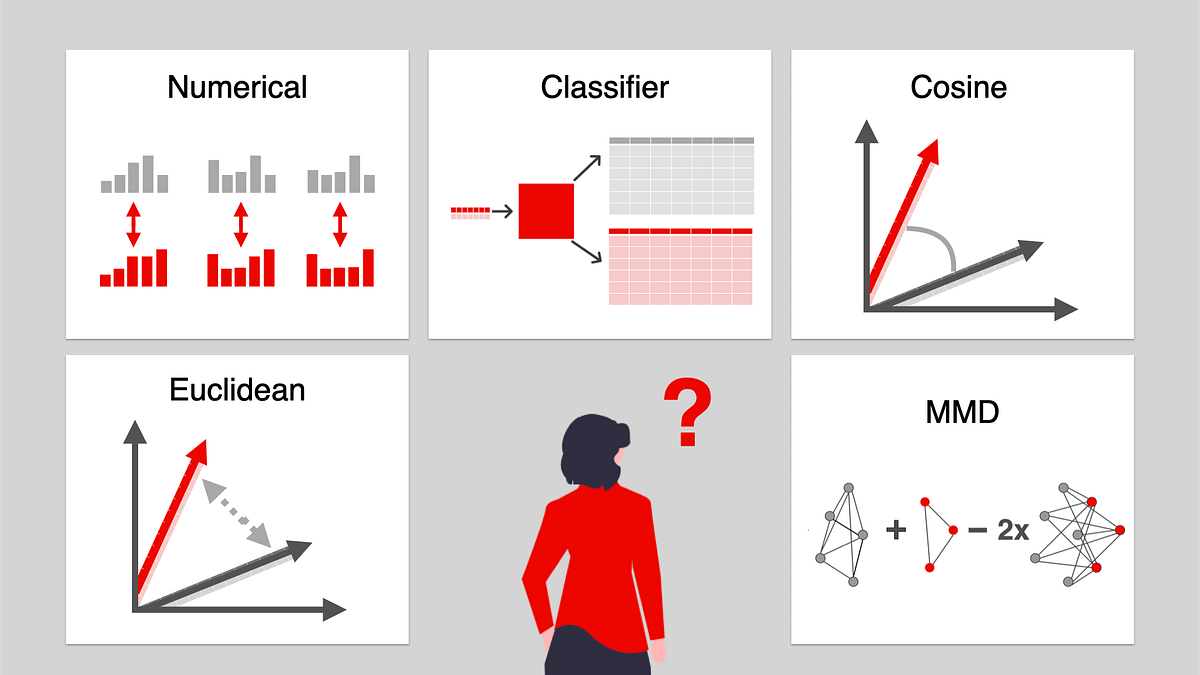
Cómo medir el desvío en las incrustaciones de ML
Cuando los sistemas de ML están en producción, a menudo no se obtienen de inmediato las etiquetas de verdad del suelo. El modelo predice…

Técnicas avanzadas de RAG una visión general ilustrada
Dado que el objetivo del artículo es hacer un resumen y explicación de los algoritmos y técnicas RAG disponibles, no entraré en detalles de…
Modelos de Lenguaje Grandes y Bases de Datos Vectoriales para Recomendaciones de Noticias
Los modelos de lenguaje grandes (LLMs) generaron un gran revuelo a nivel mundial en la comunidad de aprendizaje automático con los recientes lanzamientos de…
Por favor, utiliza una carga de trabajo de transmisión para evaluar los bancos de datos vectoriales.
Las bases de datos vectoriales están diseñadas para la recuperación de vectores de alta dimensionalidad. Hoy en día, muchos vectores son incrustaciones generadas por…

Construye fácilmente una búsqueda de imágenes semántica utilizando Amazon Titan
Los editores digitales están buscando constantemente maneras de agilizar y automatizar sus flujos de trabajo de medios para generar y publicar contenido nuevo lo…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.