Learn more about Search Results La Estrategia de Fragmentación Importa

- You may be interested
- Encendiendo la Combustión Cognitiva Fus...
- Agrupación desatada Entendiendo el agru...
- ‘Búsqueda potenciada en el 🤗 Hub&...
- Cómo Veriff redujo el tiempo de impleme...
- Dominando el Futuro Evaluando Arquitect...
- Reseña de HitPaw Photo Enhancer ¿El mej...
- Google DeepMind lanza Open X-Embodiment...
- Buscar semántica moderna para imágenes
- El algoritmo de Reingold Tilford explic...
- Filtrado de datos en Julia Todo lo que ...
- Aprovechando el poder de las APIs Molde...
- Prediciendo la expresión génica con IA
- Asiste a ODSC West Virtual de forma gra...
- Comprensión del código en tu propio har...
- Noticias VoAGI, 11 de octubre 3 proyect...

Permite un entrenamiento más rápido con la biblioteca de paralelismo de datos de Amazon SageMaker
El entrenamiento de modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés) se ha vuelto cada vez más popular en el…

Una Nueva Era de Generación de Texto RAG, LangChain y Bases de Datos Vectoriales
Introducción Técnicas innovadoras continúan dando forma a cómo las máquinas entienden y generan lenguaje humano en el cambiante panorama de procesamiento de lenguaje natural.…
Este boletín de inteligencia artificial es todo lo que necesitas #71
Esta semana, el presidente Joe Biden volvió a poner la regulación de la inteligencia artificial en el punto de mira al firmar una orden…

El CEO de Boomi esboza la visión para la plataforma de integración y automatización
Plataforma impulsada por IA supera la fragmentación digital y empodera a los desarrolladores, permitiendo a las empresas aprovechar el valor comercial de sus datos…
Consideraciones prácticas en el diseño de aplicaciones RAG
La arquitectura RAG (Recuperación Generada con Augmento) ha demostrado ser eficiente en superar el límite de longitud de entrada de LLM y el problema…

Plataforma moderna de MLOps para la Inteligencia Artificial Generativa
Una plataforma MLOps moderna para la IA generativa integra de manera perfecta las prácticas de operaciones de aprendizaje automático con los aspectos únicos de…
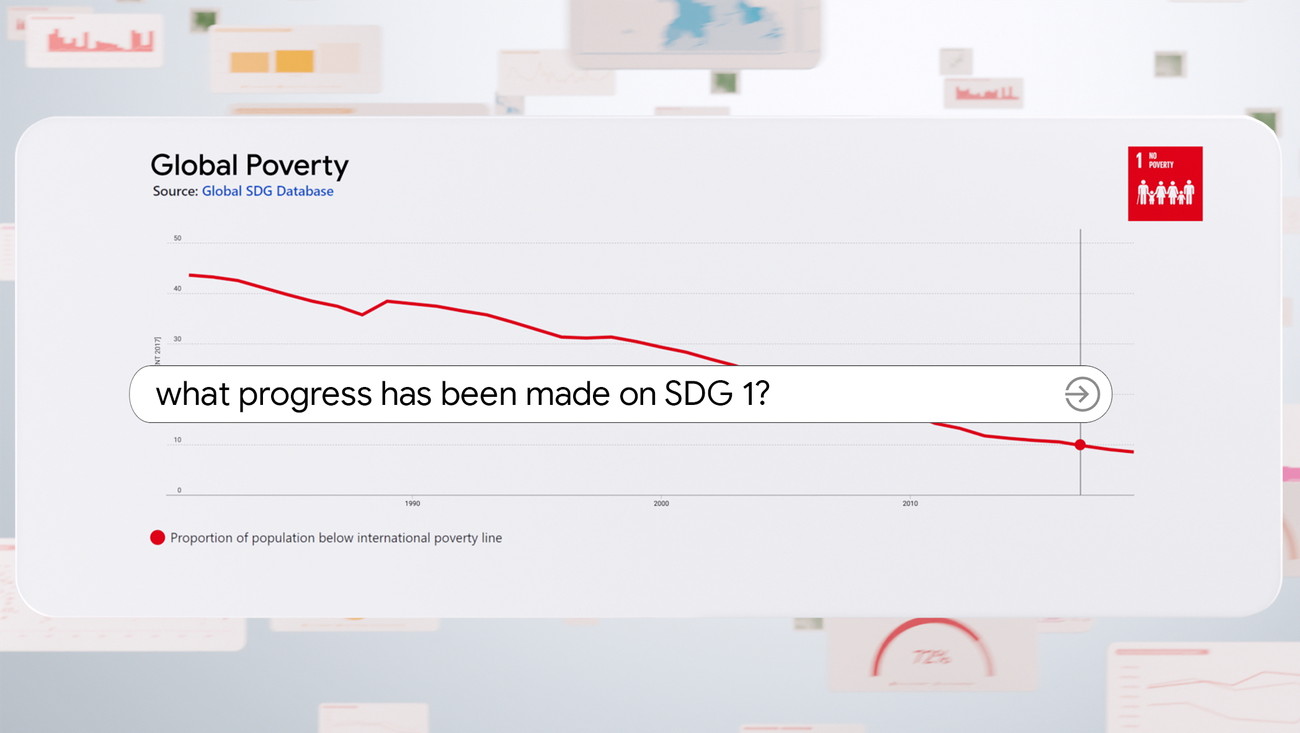
Utilizando datos e inteligencia artificial para rastrear el progreso hacia los Objetivos Globales de las Naciones Unidas
Data Commons trabaja con la ONU y ONE para realizar un seguimiento del progreso hacia los Objetivos de Desarrollo Sostenible (SDG).

10 formas de mejorar el rendimiento de los sistemas de generación mejorada de recuperación
Los LLMs son una invención asombrosa, propensa a un problema clave. Se inventan cosas. RAG hace que los LLMs sean mucho más útiles al…

Ajuste fino de Llama 2 70B utilizando PyTorch FSDP
Introducción En esta publicación del blog, veremos cómo afinar Llama 2 70B utilizando PyTorch FSDP y las mejores prácticas relacionadas. Aprovecharemos Hugging Face Transformers,…

Escalando la inferencia del modelo similar a BERT en CPU modernas – Parte 2
Introducción: Utilizando el software de Intel para optimizar la eficiencia de la IA en CPU Como detallamos en nuestra publicación de blog anterior, los…

Historia de optimización Inferencia de Bloom
Este artículo te brinda información sobre cómo creamos un servidor de inferencia eficiente que alimenta a bloom, un servidor de inferencia que alimenta https://huggingface.co/bigscience/bloom.…

El estado de la Visión por Computadora en Hugging Face 🤗
En Hugging Face, nos enorgullece democratizar el campo de la inteligencia artificial junto con la comunidad. Como parte de esa misión, hemos comenzado a…

Arquitectura y Construcción de Aplicaciones Potenciadas por LLM
Este artículo de investigación explora el proceso de diseñar y construir una aplicación impulsada por un LLM (Aprendizaje basado en Modelos de Lenguaje).
Una agenda de políticas para el progreso responsable de la inteligencia artificial Oportunidad, Responsabilidad, Seguridad.
Para que la sociedad pueda cosechar los beneficios de la IA, las estrategias de oportunidad, responsabilidad y seguridad nacional deben ser incorporadas en esa…
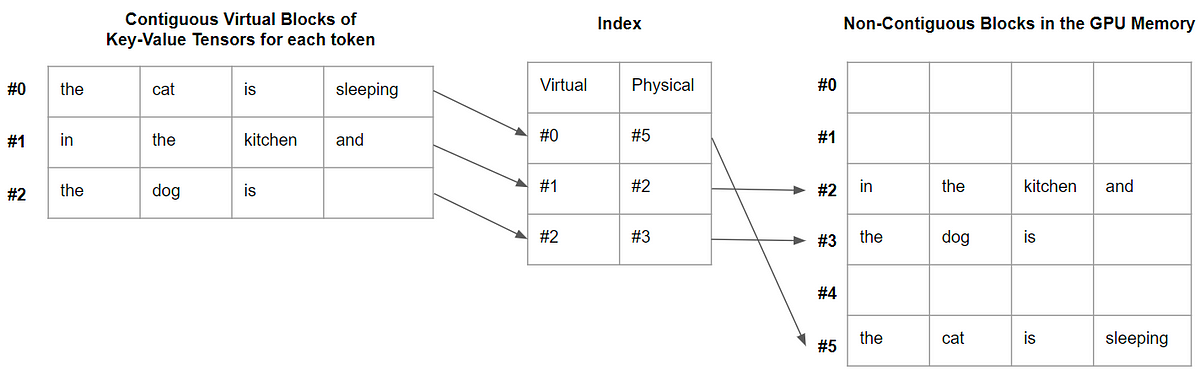
vLLM PagedAttention para una inferencia LLM 24 veces más rápida
En este artículo, explico qué es PagedAttention y por qué acelera significativamente la decodificación.
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.