Learn more about Search Results Iris

- You may be interested
- La Guía Esencial de Análisis Explorator...
- 5 Técnicas de Optimización de Código Pa...
- Los 15 principales YouTubers de IA para...
- Implementando LoRA desde cero
- Aprendizaje por Refuerzo sin Modelo par...
- Flujos de trabajo CI/CD sin interrupcio...
- Utilizando datos de física para enfocar...
- Ciencia de datos del entretenimiento St...
- Equilibrando la urgencia vs. la sosteni...
- 4 gigantes tecnológicos – OpenAI,...
- Aplicando Estadísticas Descriptivas e I...
- Investigadores de Apple proponen la pol...
- Auriculares para monitorear el cerebro ...
- GPT-4 8 Modelos en Uno; El Secreto ha S...
- Artículo de Georgia Tech propone un mét...

La Maldición de la Dimensionalidad en Clasificadores KNN
En este artículo, exploraremos el efecto de la dimensionalidad de la maldición en el algoritmo KNN, comenzando con una breve descripción de cómo funciona…

Cuantificar el consumo de electricidad de la AI generativa
Fecha de actualización 11 de diciembre de 2023 - El análisis revisado en el Apéndice refleja el doble estimado de las ventas por AMD.…

Empaqueta e implementa fácilmente modelos de ML clásicos y LLMs con Amazon SageMaker, parte 2 Experiencias interactivas para usuarios en SageMaker Studio
Amazon SageMaker es un servicio completamente administrado que permite a los desarrolladores y científicos de datos construir, entrenar y implementar modelos de aprendizaje automático…

La IA detecta emisiones de metano desde el espacio
Una nueva herramienta de aprendizaje automático utiliza datos de satélites hiperespectrales para detectar automáticamente nubes de metano desde el espacio.

Cómo SnapLogic creó una aplicación de texto a tubería con Amazon Bedrock para traducir la intención empresarial en acción
Esta publicación fue coescrita por Greg Benson, científico jefe; Aaron Kesler, gerente senior de productos; y Rich Dill, arquitecto de soluciones empresariales de SnapLogic.…

Datos de navegación web recopilados con más detalle de lo que se conocía anteriormente.
Según un informe del Irish Council for Civil Liberties, se está recopilando y vendiendo datos de navegación web con mayor detalle de lo que…

Una Guía Completa para la División de Entrenamiento-Prueba-Validación en 2023
Introducción Un objetivo del aprendizaje supervisado es construir un modelo que funcione bien en un conjunto de datos nuevos. El problema es que es…

Ajusta y despliega Mistral 7B con Amazon SageMaker JumpStart
Hoy, nos complace anunciar la capacidad de ajustar el modelo Mistral 7B utilizando Amazon SageMaker JumpStart. Ahora puedes afinar y implementar modelos de generación…

Mejores prácticas para depurar errores en la regresión logística con Python
Se ha escrito mucho sobre los conceptos básicos de la Regresión Logística (RL) su versatilidad, desempeño probado con el tiempo, incluso las matemáticas subyacentes.…

Búsqueda de imágenes en 5 minutos
En esta publicación implementaremos la búsqueda de texto a imagen (que nos permitirá buscar una imagen a través de texto) y la búsqueda de…

La incorporación del smartphone podría aumentar la equidad racial en la detección neurológica
Un nuevo accesorio para teléfonos inteligentes podría ser utilizado para realizar pruebas neurológicas de bajo costo, para garantizar resultados precisos independientemente del tono de…

Redimensionar imágenes sobre la marcha
En esta publicación, describimos cómo utilizar Apache APISIX con imgproxy para reducir el costo de almacenamiento de imágenes en múltiples resoluciones.

Python Ray ¿La vía rápida de la computación distribuida?
Python Ray es un marco dinámico que revoluciona la computación distribuida. Desarrollado por RISELab de UC Berkeley, simplifica las aplicaciones paralelas y distribuidas de…

7 Visualizaciones con Python para manejar datos categóricos multivariables
Los datos comunes, como el conocido conjunto de datos de iris o pingüinos, utilizados para el análisis son bastante simples ya que solo tienen…

Empezando con Scikit-learn en 5 Pasos
Este tutorial ofrece un recorrido completo y práctico sobre el aprendizaje automático con Scikit-learn. Los lectores aprenderán conceptos y técnicas clave, incluyendo el preprocesamiento…
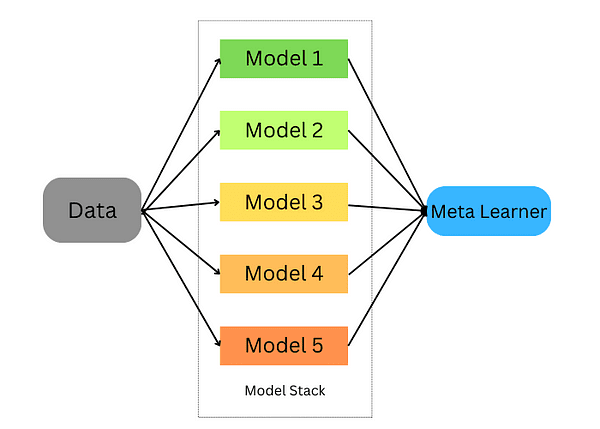
Técnicas de Aprendizaje en Conjunto Un Recorrido con Bosques Aleatorios en Python
Un recorrido práctico por los bosques aleatorios en Python.

Mejorando la Ajuste de Hiperparámetros con el Estimador Parzen Estructurado en Árbol (Hyperopt)
Este artículo explora el concepto del Estimador de Parzen Estructurado en Árbol (TPE) para la sintonización de hiperparámetros en el aprendizaje automático y su…

Ajuste fino de Llama 2 para generación de texto en Amazon SageMaker JumpStart
Hoy, nos complace anunciar la capacidad de ajustar finamente los modelos Llama 2 de Meta utilizando Amazon SageMaker JumpStart. La familia de modelos de…
Una guía para la recolección de datos del mundo real para el Aprendizaje Automático
Ya sea que seas completamente nuevo en la ciencia de datos o el científico de datos principal de una gran organización, probablemente hayas jugado…

Limpieza de datos con Pandas
Este tutorial paso a paso está diseñado para principiantes y los guiará a través del proceso de limpieza y preprocesamiento de datos utilizando la…
Escalando la Agrupación Aglomerativa para Grandes Volúmenes de Datos
La agrupación aglomerativa es una de las mejores herramientas de agrupación en ciencia de datos, pero las implementaciones tradicionales no logran escalar a conjuntos…
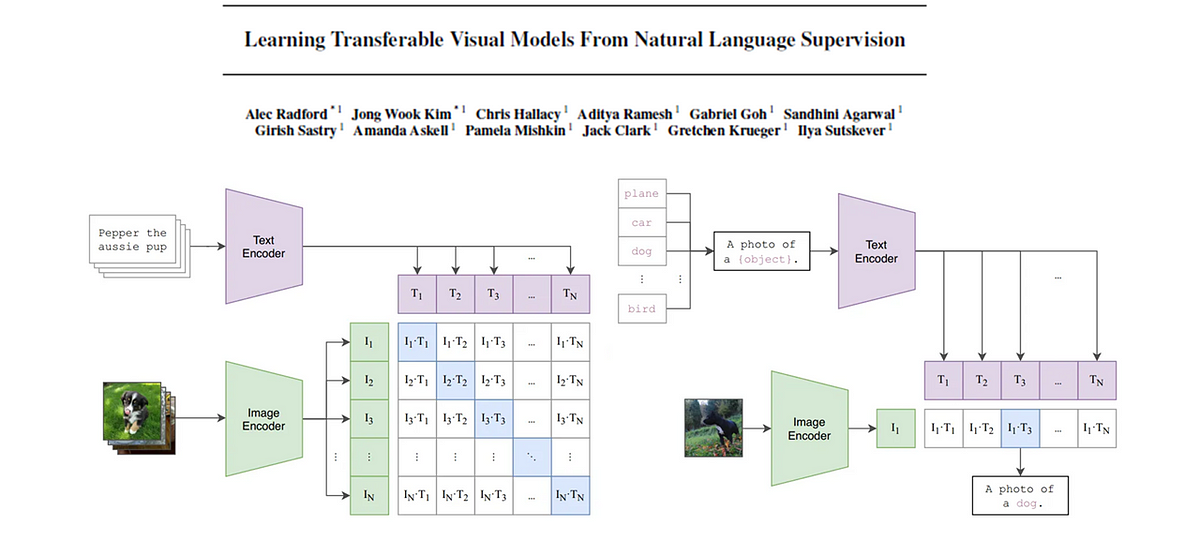
El modelo base de CLIP
En este artículo vamos a analizar el documento detrás de CLIP (Contrastive Language-Image Pre-Training). Extraeremos conceptos clave y los desglosaremos para que sean fáciles…
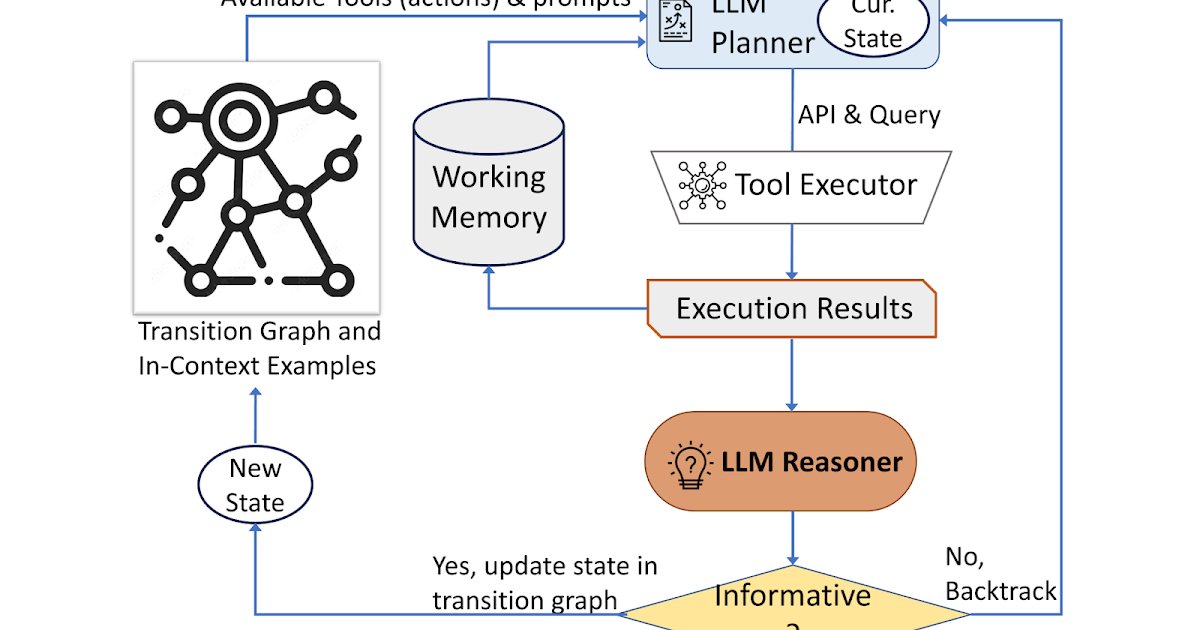
Búsqueda autónoma de información visual con modelos de lenguaje grandes
Publicado por Ziniu Hu, Investigador Estudiantil, y Alireza Fathi, Científico Investigador, Equipo de Percepción de Google Research Se ha progresado mucho en la adaptación…

Código de Destilación de Conocimiento y Pesos de SD-Small y SD-Tiny de código abierto
En tiempos recientes, la comunidad de IA ha presenciado un notable aumento en el desarrollo de modelos de lenguaje más grandes y con mejor…
Profundización en la Interpretabilidad de Modelos con PFI
Saber cómo evaluar tu modelo es esencial para tu trabajo como científico de datos. Nadie aprobará tu solución si no eres capaz de entenderla…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.