Learn more about Search Results El aprendizaje por refuerzo

- You may be interested
- Investigadores del MIT descubren nuevos...
- Encontrar agujas en un pajar índices de...
- Meta AI anuncia Purple Llama para ayuda...
- ¿Cómo cambiar de carrera de analista de...
- PyTorchEdge presenta ExecuTorch Potenci...
- Utilizar modelos de lenguaje grandes en...
- Essential AI recauda $56.5 millones en ...
- Científico de datos vs. Analista de dat...
- AI para el juego de mesa Diplomacy
- La ingeniería ha cambiado para siempre
- NODO Árboles Neuronales Centrados en Ta...
- Alibaba libera el modelo de IA de códig...
- ChatDev Agentes comunicativos para el d...
- BERT 101 – Modelo de Procesamient...
- El avance de la inteligencia artificial...

Revolucionando el arte digital Investigadores de la Universidad Nacional de Seúl introducen un enfoque novedoso para la creación de collages utilizando el aprendizaje por refuerzo.
La creación de collages artísticos, un campo profundamente entrelazado con la habilidad artística humana, ha despertado el interés en la inteligencia artificial (IA). El…

Este artículo de IA tiene movimientos Cómo los modelos de lenguaje se adentran en el aprendizaje por refuerzo sin conexión con los pasos de baile de ‘LaMo’ y el aprendizaje de pocos disparos
Investigadores presentan Language Models for Motion Control (LaMo), un marco utilizando Large Language Models (LLMs) para el aprendizaje por refuerzo sin conexión en línea.…

Integrando la IA generativa y el aprendizaje por refuerzo para el auto-mejoramiento
Introducción En el siempre cambiante panorama de la inteligencia artificial, dos actores clave se han unido para romper nuevos límites: la IA generativa y…

Investigadores de Microsoft presentan Hydra-RLHF Una solución eficiente en memoria para el aprendizaje por refuerzo con retroalimentación humana
Desde que se hicieron conocidos, los modelos familiares ChatGPT, GPT-4 y Llama-2 han conquistado a los usuarios con su versatilidad como asistentes útiles para…

Investigadores de UC Berkeley presentan Video Prediction Rewards (VIPER) un algoritmo que aprovecha los modelos de predicción de video preentrenados como señales de recompensa sin acción para el aprendizaje por refuerzo.
El diseño de una función de recompensa manualmente es lento y puede resultar en consecuencias no deseadas. Esto es un obstáculo importante en el…
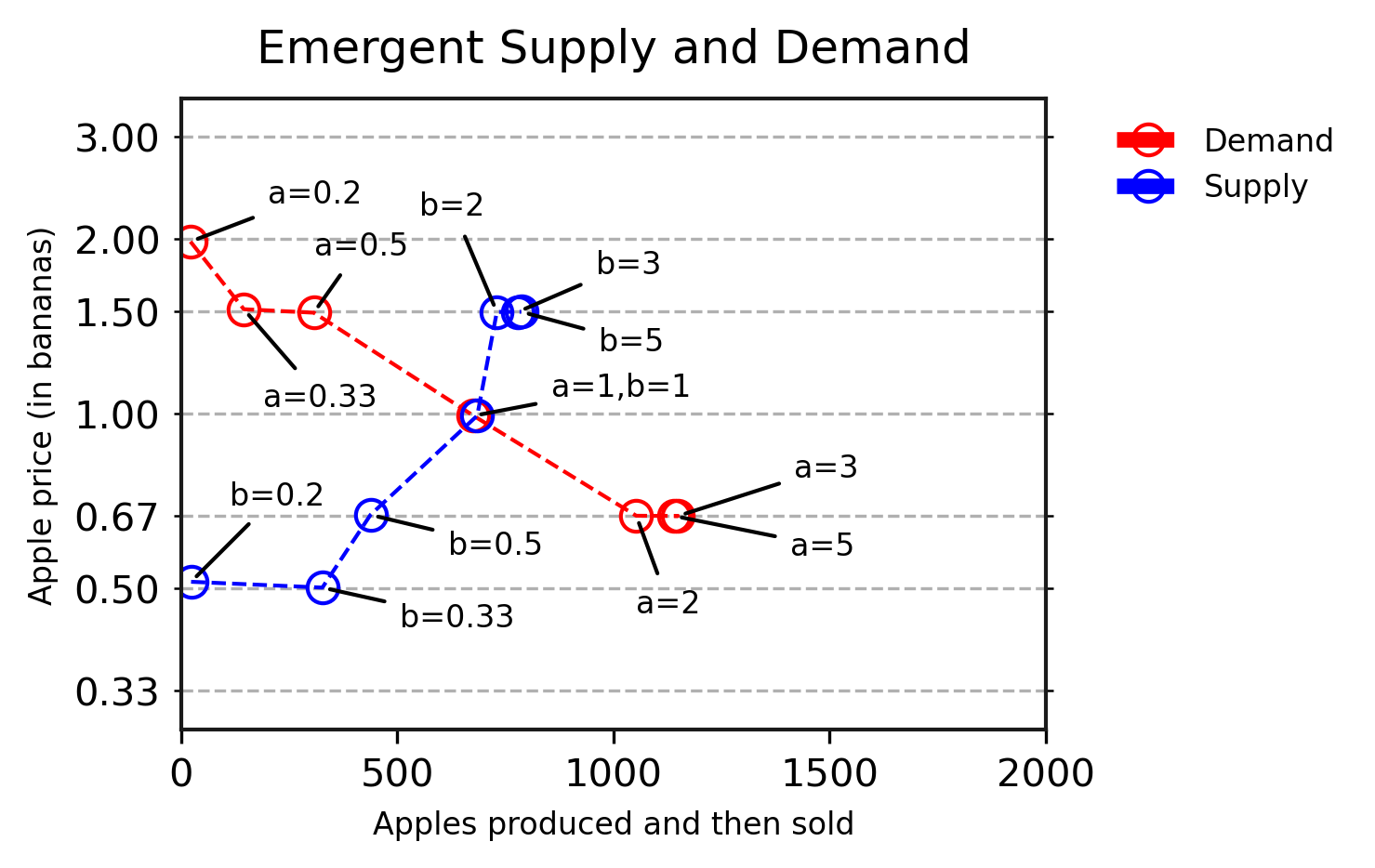
Comportamiento emergente de trueque en el aprendizaje por refuerzo de múltiples agentes
En nuestro artículo reciente, exploramos cómo las poblaciones de agentes de aprendizaje por refuerzo profundo (RL profundo) pueden aprender comportamientos microeconómicos, como la producción,…

Aprendizaje por Refuerzo Conveniente con Stable-Baselines3
En mis artículos anteriores sobre aprendizaje por refuerzo, te he mostrado cómo implementar el (aprendizaje profundo) Q-learning utilizando únicamente un poco de numpy y…

Investigadores de Apple proponen la política de aprendizaje por refuerzo del modelo de lenguaje grande (LLaRP, por sus siglas en inglés) Enfoque de IA mediante el cual los LLM pueden adaptarse para actuar como políticas generalizables para tareas visuales
El Procesamiento de Lenguaje Natural, la comprensión y generación han entrado en una nueva fase con la introducción de los Modelos de Lenguaje Grandes…

Vectoriza y paraleliza entornos de RL con JAX Aprendizaje por refuerzo a la velocidad de la luz⚡
En la historia anterior, presentamos el Aprendizaje de Diferencia Temporal, particularmente el Aprendizaje Q, en el contexto de un GridWorld (mundo de cuadrícula). Si…

Google Research explora ¿Puede la retroalimentación de IA reemplazar la entrada humana para un aprendizaje por refuerzo efectivo en modelos de lenguaje grandes?
La retroalimentación humana es esencial para mejorar y optimizar los modelos de aprendizaje automático. En los últimos años, el aprendizaje por refuerzo a partir…

Investigadores de la Universidad de Tokio desarrollaron un esquema de aprendizaje por refuerzo fotónico extendido que se mueve desde el problema estático del bandido hacia un entorno dinámico más desafiante.
En el mundo del aprendizaje automático, el concepto de aprendizaje por refuerzo ha tomado protagonismo, permitiendo a los agentes conquistar tareas a través de…

LLMs superan al aprendizaje por refuerzo Conozca SPRING un innovador marco de trabajo de sugerencias para LLMs diseñado para permitir la planificación y el razonamiento en cadena de pensamiento en contexto.
SPRING es una política basada en LLM que supera a los algoritmos de Reinforcement Learning en un entorno interactivo que requiere planificación y razonamiento…
Aprendizaje por Refuerzo sin Modelo para el Desarrollo de Procesos Químicos
El desarrollo, diseño, optimización y control de procesos son algunas de las principales tareas dentro de la ingeniería química y de procesos. En términos…

Visión por Computadora 101
A medida que la Visión por Computadora continúa avanzando, posee un inmenso potencial para el futuro. Su impacto transformador se extiende a través de…
Hacia la IA General el papel de LLMs y Modelos Fundamentales en la Revolución del Aprendizaje de por Vida
En la última década y especialmente con el éxito del aprendizaje profundo, se ha formado una discusión continua en torno a la posibilidad de…

Resumen semanal de IA de ODSC semana del 15 de diciembre
La inteligencia artificial ha estado avanzando a la velocidad de la luz con todas las noticias que se han publicado. Así que hagamos un…

El (Largo) Cola Mueve al Perro Las Consecuencias Inesperadas del Arte Personalizado de la IA
La reciente presentación de Meta de Emu en el mundo de las películas generativas marca un punto de inflexión, un momento en el que…

Los 10 mejores modelos de lenguaje grandes en Hugging Face
Introducción Hugging Face se ha convertido en un tesoro para los entusiastas y desarrolladores de procesamiento de lenguaje natural, ofreciendo una diversa colección de…

Investigadores de Meta IA publican como código abierto Pearl una biblioteca de agentes de IA de aprendizaje por refuerzo lista para la producción.
Aprendizaje por refuerzo (RL) es un subcampo del aprendizaje automático en el cual un agente toma acciones adecuadas para maximizar sus recompensas. En el…

Conectando los puntos Desentrañando el supuesto modelo Q-Star de OpenAI
‘Descubre el Q-Star de OpenAI un presunto salto hacia la Inteligencia Artificial General (IAG). Adéntrate en el drama de CEO sospechando el papel de…
Aprendamos Inteligencia Artificial Juntos – Boletín de la Comunidad Towards AI #4
Buenos días, estimados entusiastas de la IA. En este número, compartimos un nuevo video para nuestra serie de videos del curso con Activeloop sobre…

Potenciando asistentes inteligentes de documentos basados en RAG utilizando extracción de entidades, consultas SQL y agentes con Amazon Bedrock
La inteligencia artificial conversacional ha recorrido un largo camino en los últimos años gracias a los rápidos avances en la IA generativa, especialmente en…

Conoce DreamSync un nuevo marco de inteligencia artificial para mejorar la síntesis de texto a imagen (T2I) con comentarios de modelos de comprensión de imagen
Investigadores de la Universidad del Sur de California, la Universidad de Washington, la Universidad Bar-Ilan y Google Research presentaron DreamSync, que aborda el problema…

Investigadores de UC Berkeley presentan Starling-7B un Modelo de Lenguaje Amplio (LLM) Abierto entrenado mediante Aprendizaje por Reforzamiento a partir de Retroalimentación de IA (ARIA).
Los Modelos de Lenguaje Grandes (LLMs) son modelos de inteligencia artificial para tareas de procesamiento de lenguaje natural. Estos modelos se entrenan con conjuntos…

Este artículo de IA publica una revisión detallada de los modelos de lenguaje de código abierto a gran escala que afirman alcanzar o superar a ChatGPT en diferentes tareas.
El lanzamiento reciente de ChatGPT el año pasado ha causado sensación en la comunidad de Inteligencia Artificial. Basado en la arquitectura de transformadores de…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.