Learn more about Search Results Documentación de CUDA

- You may be interested
- Construyendo aplicaciones de IA generat...
- Conoce Jupyter AI Un nuevo proyecto de ...
- Ajuste fino de LLaMA en documentos médi...
- Combinando los datos reales y las previ...
- Google presenta Project IDX un paraíso ...
- Google DeepMind utilizó un gran modelo ...
- De ChatGPT a Pi, ¡y te voy a contar por...
- Informe China finaliza las reglas de go...
- Conoce Cursive Un Marco de Inteligencia...
- El audaz movimiento de Walmart equipar ...
- Control Sintético ¿Y si pudiéramos simu...
- Uplift Modeling – Una guía para c...
- Gradio-Lite Gradio sin servidor funcion...
- CEO de OpenAI, Sam Altman Empleos en ri...
- Together AI presenta Llama-2-7B-32K-Ins...

Consultas de lenguaje natural potenciadas por IA para descubrimiento de conocimiento
En este artículo, quería compartir un proyecto de prueba de concepto en el que he estado trabajando llamado UE5_documentalist. Es un proyecto emocionante que…

Aprovechando el poder de las GPUs con CuPy en Python
Ya sea que estés haciendo aprendizaje automático, cómputo científico o trabajando con conjuntos de datos enormes, CuPy es un cambio de juego absoluto.

Explora de forma interactiva tu conjunto de datos de Huggingface con una línea de código
La biblioteca de datasets de Hugging Face no solo proporciona acceso a más de 70k conjuntos de datos públicamente disponibles, sino que también ofrece…

QLoRA Entrenando un Modelo de Lenguaje Grande en una GPU de 16GB.
Vamos a combinar una técnica de reducción de peso para modelos, como la cuantización, con una técnica de ajuste fino eficiente en parámetros como…

Aprovechando los superpoderes de NLP Un tutorial paso a paso para ajustar finamente Hugging Face
Introducción Ajustar finamente un modelo de procesamiento de lenguaje natural (NLP, por sus siglas en inglés) implica alterar los hiperparámetros y la arquitectura del…

Multiplicación de matrices en la GPU
Este blog explora cómo se implementa la multiplicación de matrices de última generación en CUDA. Se sumerge en la arquitectura de las GPUs de…

¿Y si pudiéramos explicar fácilmente modelos excesivamente complejos?
Este artículo se basa en el siguiente artículo https//www.sciencedirect.com/science/article/abs/pii/S0377221723006598 Si estás leyendo esto, es posible que sepas lo fundamental que es la Inteligencia Artificial…

Introducción a las bibliotecas de Aprendizaje Profundo PyTorch y Lightning AI
Explicación simple de PyTorch y Lightning AI.

¡Construye y juega! ¡Tu propio modelo V&L equipado con LLM!
Los modelos de lenguaje grandes (LLM) están demostrando cada vez más su valor. La incorporación de imágenes en los LLM los hace aún más…

Quantización GPTQ en un modelo Llama 2 7B Fine-Tuned con HuggingFace
En mi artículo anterior, te mostré cómo ajustar finamente el nuevo modelo Llama 2, recién lanzado por Meta AI, para construir un generador de…

Introducción a Semantic Kernel para los entusiastas de Python
Desde el lanzamiento de ChatGPT, los Modelos de Lenguaje Grandes (LLMs, por sus siglas en inglés) han recibido una gran cantidad de atención tanto…

Comparación de Frameworks de Aprendizaje Profundo
Descubre los principales marcos de trabajo de aprendizaje profundo para desarrolladores. Compara características, rendimiento y facilidad de uso para optimizar tu viaje de codificación…

Anunciando la vista previa de Amazon SageMaker Profiler Haga un seguimiento y visualice datos detallados de rendimiento de hardware para sus cargas de trabajo de entrenamiento de modelos.
Hoy nos complace anunciar la vista previa de Amazon SageMaker Profiler, una capacidad de Amazon SageMaker que brinda una vista detallada de los recursos…
Análisis y optimización del rendimiento del modelo PyTorch – Parte 3
Esta es la tercera parte de una serie de publicaciones sobre el tema de analizar y optimizar modelos de PyTorch utilizando PyTorch Profiler y…

El Reformador – Empujando los límites del modelado de lenguaje
Cómo el Reformer utiliza menos de 8GB de RAM para entrenar en secuencias de medio millón de tokens El modelo Reformer, presentado por Kitaev,…

Aprovechando los puntos de control de modelos de lenguaje pre-entrenados para modelos codificador-decodificador.
Los modelos codificador-decodificador basados en transformadores fueron propuestos en Vaswani et al. (2017) y recientemente han experimentado un aumento de interés, por ejemplo, Lewis…
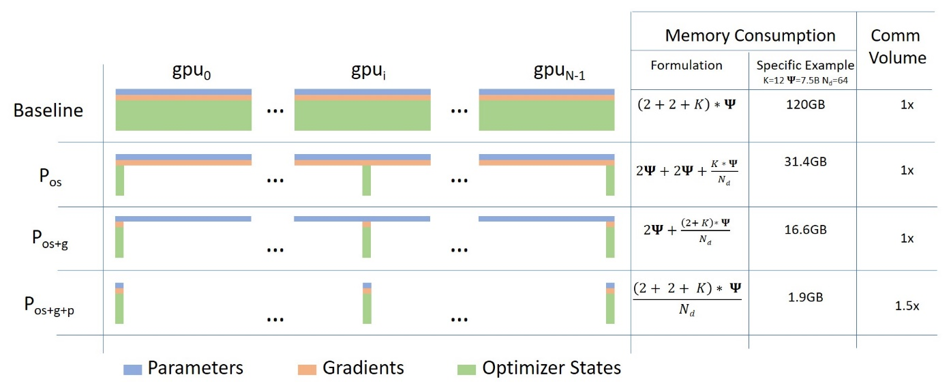
Ajusta más y entrena más rápido con ZeRO a través de DeepSpeed y FairScale
Una entrada de blog invitada del compañero de Hugging Face Stas Bekman A medida que los modelos de Aprendizaje Automático recientes han crecido mucho…

Acelerando el ajuste fino distribuido de PyTorch con tecnologías de Intel
Para toda su asombrosa capacidad, los modelos de aprendizaje profundo de última generación a menudo tardan mucho tiempo en entrenarse. Para acelerar los trabajos…
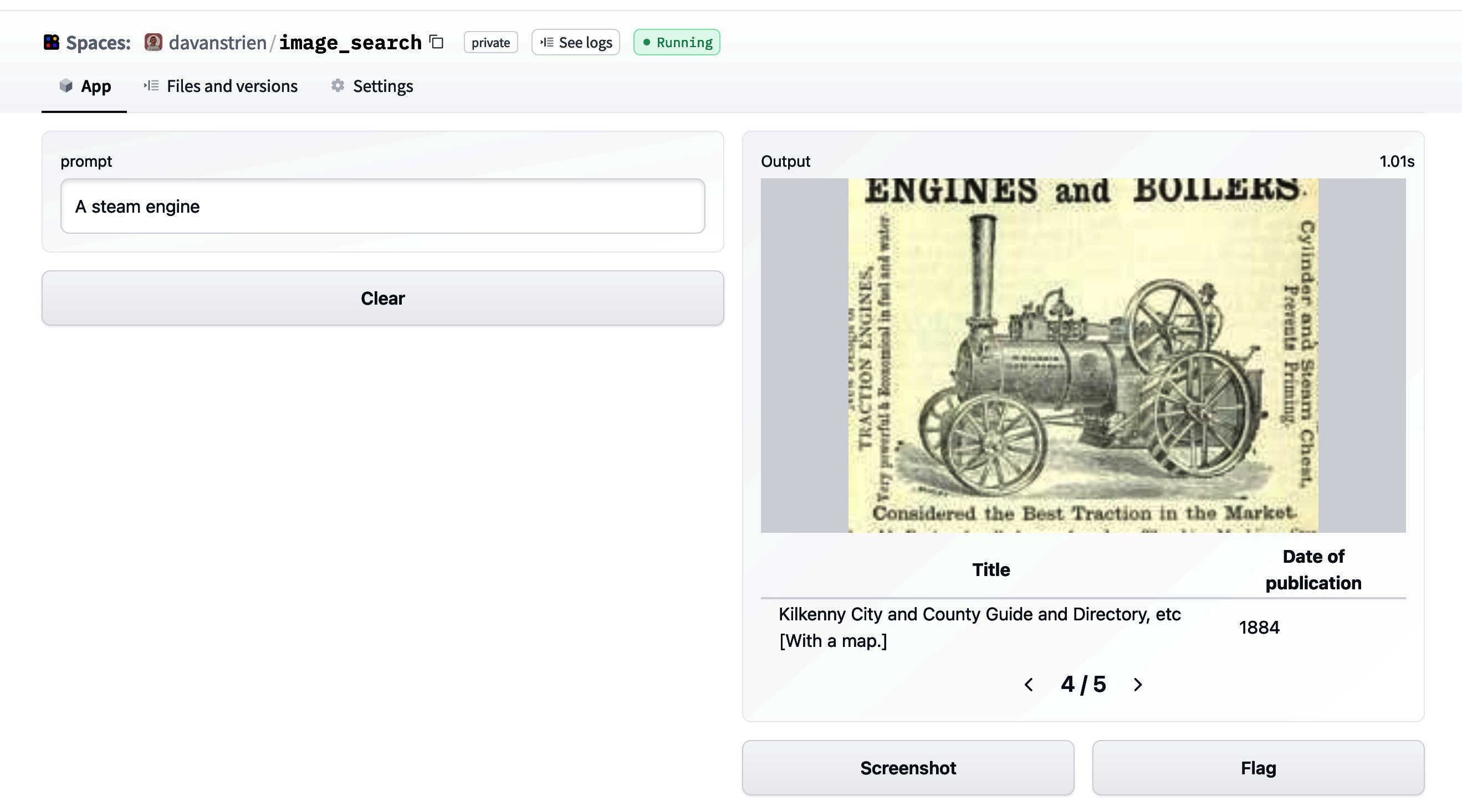
Búsqueda de imágenes con 🤗 conjuntos de datos
🤗 datasets es una biblioteca que facilita el acceso y compartición de conjuntos de datos. También facilita el procesamiento eficiente de datos, incluyendo el…

La Tecnología Detrás del Entrenamiento BLOOM
En los últimos años, se ha vuelto habitual entrenar modelos de lenguaje cada vez más grandes. Si bien se discute con frecuencia el tema…

¿Qué hay de nuevo en los Difusores? 🎨
Hace un mes y medio lanzamos diffusers, una biblioteca que proporciona un conjunto de herramientas modulares para modelos de difusión en diferentes modalidades. Un…

Cómo entrenar un Modelo de Lenguaje con Megatron-LM
Entrenar modelos de lenguaje grandes en Pytorch requiere más que un simple bucle de entrenamiento. Por lo general, se distribuye en múltiples dispositivos, con…

Historia de optimización Inferencia de Bloom
Este artículo te brinda información sobre cómo creamos un servidor de inferencia eficiente que alimenta a bloom, un servidor de inferencia que alimenta https://huggingface.co/bigscience/bloom.…

De PyTorch DDP a Accelerate Trainer, dominio del entrenamiento distribuido con facilidad.
Visión general general Este tutorial asume que tienes una comprensión básica de PyTorch y cómo entrenar un modelo simple. Mostrará el entrenamiento en múltiples…

Optimum+ONNX Runtime Entrenamiento más fácil y rápido para tus modelos de Hugging Face
Introducción Los modelos basados en Transformers en lenguaje, visión y habla están creciendo para soportar casos de uso multimodales más complejos para el cliente…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.