7 Pasos para Dominar las Técnicas de Limpieza y Preprocesamiento de Datos
7 Pasos para Limpieza y Preprocesamiento de Datos
Dominar las técnicas de limpieza y preprocesamiento de datos es fundamental para resolver muchos proyectos de ciencia de datos. Una simple demostración de lo importante que puede ser se puede encontrar en el meme sobre las expectativas de un estudiante que estudia ciencia de datos antes de trabajar, en comparación con la realidad del trabajo de científico de datos.
Tendemos a idealizar el puesto de trabajo antes de tener una experiencia concreta, pero la realidad siempre es diferente de lo que realmente esperamos. Al trabajar con un problema del mundo real, no hay documentación de los datos y el conjunto de datos está muy sucio. Primero, debes profundizar en el problema, entender qué pistas te faltan y qué información puedes extraer.
Después de entender el problema, necesitas preparar el conjunto de datos para tu modelo de aprendizaje automático, ya que los datos en su condición inicial nunca son suficientes. En este artículo, voy a mostrar siete pasos que pueden ayudarte a preprocesar y limpiar tu conjunto de datos.
- El gigante del streaming Netflix lista trabajo de Inteligencia Artificial a $900,000 mientras continúa la huelga de escritores
- Todo lo que necesitas saber sobre análisis deportivo en 2023
- Conoce a LP-MusicCaps un enfoque de generación de subtítulos seudoposicionales con grandes modelos de lenguaje para abordar el problema de escasez de datos en la subtitulación automática de música.
Paso 1: Análisis exploratorio de datos
El primer paso en un proyecto de ciencia de datos es el análisis exploratorio, que ayuda a comprender el problema y tomar decisiones en los siguientes pasos. Tiende a pasarse por alto, pero es el peor error porque perderás mucho tiempo más adelante para encontrar la razón por la que el modelo da errores o no se desempeña como se esperaba.
Según mi experiencia como científico de datos, dividiría el análisis exploratorio en tres partes:
- Verificar la estructura del conjunto de datos, las estadísticas, los valores faltantes, los duplicados, los valores únicos de las variables categóricas
- Comprender el significado y la distribución de las variables
- Estudiar las relaciones entre variables
Para analizar cómo se organiza el conjunto de datos, existen los siguientes métodos de Pandas que pueden ayudarte:
df.head()
df.info()
df.isnull().sum()
df.duplicated().sum()
df.describe([x*0.1 for x in range(10)])
for c in list(df):
print(df[c].value_counts())
Cuando intentas entender las variables, es útil dividir el análisis en dos partes: características numéricas y características categóricas. Primero, podemos centrarnos en las características numéricas que se pueden visualizar a través de histogramas y diagramas de caja. Después, es el turno de las variables categóricas. En caso de que sea un problema binario, es mejor comenzar por verificar si las clases están balanceadas. Después, podemos enfocar nuestra atención en las variables categóricas restantes utilizando los gráficos de barras. Al final, finalmente podemos verificar la correlación entre cada par de variables numéricas. Otras visualizaciones de datos útiles pueden ser los diagramas de dispersión y diagramas de caja para observar las relaciones entre una variable numérica y una variable categórica.
Paso 2: Tratar los valores faltantes
En el primer paso, ya hemos investigado si hay valores faltantes en cada variable. En caso de que haya valores faltantes, debemos entender cómo manejar el problema. La forma más fácil sería eliminar las variables o las filas que contienen valores NaN, pero preferiríamos evitarlo porque corremos el riesgo de perder información útil que puede ayudar a nuestro modelo de aprendizaje automático a resolver el problema.
Si estamos tratando con una variable numérica, hay varios enfoques para completarla. El método más popular consiste en llenar los valores faltantes con la media/mediana de esa característica:
df['age'].fillna(df['age'].mean())
df['age'].fillna(df['age'].median())
Otra forma es sustituir los espacios en blanco con imputaciones por grupo:
df['price'].fillna(df.group('type_building')['price'].transform('mean'),
inplace=True)
Puede ser una mejor opción en caso de que haya una fuerte relación entre una característica numérica y una característica categórica.
De la misma manera, podemos completar los valores faltantes de las variables categóricas basándonos en la moda de esa variable:
df['type_building'].fillna(df['type_building'].mode()[0])
Paso 3: Tratar duplicados y valores atípicos
Si hay duplicados dentro del conjunto de datos, es mejor eliminar las filas duplicadas:
df = df.drop_duplicates()
Mientras decidir cómo manejar los duplicados es simple, lidiar con valores atípicos puede ser desafiante. Necesitas preguntarte “¿Eliminar o no eliminar los valores atípicos?”.
Los valores atípicos deben eliminarse si estás seguro de que solo proporcionan información ruidosa. Por ejemplo, el conjunto de datos contiene dos personas con 200 años, mientras que el rango de edad está entre 0 y 90. En ese caso, es mejor eliminar estos dos puntos de datos.
df = df[df.Age<=90]
Desafortunadamente, la mayoría de las veces eliminar los valores atípicos puede llevar a perder información importante. La forma más eficiente es aplicar la transformación logarítmica a la característica numérica.
Otra técnica que descubrí durante mi última experiencia es el método de recorte. En esta técnica, eliges el límite superior e inferior, que pueden ser el percentil 0.1 y el percentil 0.9. Los valores de la característica por debajo del límite inferior se sustituirán por el valor del límite inferior, mientras que los valores de la variable por encima del límite superior se reemplazarán por el valor del límite superior.
for c in columns_with_outliers:
transform= 'clipped_'+ c
lower_limit = df[c].quantile(0.10)
upper_limit = df[c].quantile(0.90)
df[transform] = df[c].clip(lower_limit, upper_limit, axis = 0)
Paso 4: Codificar características categóricas
La siguiente fase es convertir las características categóricas en características numéricas. De hecho, el modelo de aprendizaje automático solo puede trabajar con números, no con cadenas de texto.
Antes de continuar, debes distinguir entre dos tipos de variables categóricas: variables no ordinales y variables ordinales.
Ejemplos de variables no ordinales son el género, el estado civil, el tipo de trabajo. Por lo tanto, es no ordinal si la variable no sigue un orden, a diferencia de las características ordinales. Un ejemplo de variables ordinales puede ser la educación con valores “infancia”, “primaria”, “secundaria” y “terciaria”, y los ingresos con niveles “bajos”, “VoAGI” y “altos”.
Cuando estamos tratando con variables no ordinales, la codificación One-Hot es la técnica más popular que se toma en cuenta para convertir estas variables en numéricas.
En este método, creamos una nueva variable binaria para cada nivel de la característica categórica. El valor de cada variable binaria es 1 cuando el nombre del nivel coincide con el valor del nivel, 0 en caso contrario.
from sklearn.preprocessing import OneHotEncoder
data_to_encode = df[cols_to_encode]
encoder = OneHotEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
dummy_variables = encoder.get_feature_names_out(cols_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=encoder.get_feature_names_out(cols_to_encode))
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
Cuando la variable es ordinal, la técnica más comúnmente utilizada es la Codificación Ordinal, que consiste en convertir los valores únicos de la variable categórica en enteros que siguen un orden. Por ejemplo, los niveles “bajos”, “VoAGI” y “Altos” de los ingresos se codificarán respectivamente como 0, 1 y 2.
from sklearn.preprocessing import OrdinalEncoder
data_to_encode = df[cols_to_encode]
encoder = OrdinalEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=["Ingresos"])
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
Hay otras posibles técnicas de codificación si deseas explorar aquí. Puedes echar un vistazo aquí en caso de que estés interesado en alternativas.
Paso 5: Dividir el conjunto de datos en entrenamiento y prueba
Es hora de dividir el conjunto de datos en tres subconjuntos fijos: la elección más común es usar el 60% para entrenamiento, el 20% para validación y el 20% para prueba. A medida que la cantidad de datos aumenta, el porcentaje para el entrenamiento aumenta y el porcentaje para la validación y prueba disminuye.
Es importante tener tres subconjuntos porque el conjunto de entrenamiento se utiliza para entrenar el modelo, mientras que los conjuntos de validación y prueba pueden ser útiles para comprender cómo se está desempeñando el modelo en datos nuevos.
Para dividir el conjunto de datos, podemos usar train_test_split de scikit-learn:
from sklearn.model_selection import train_test_split
X = final_df.drop(['y'],axis=1)
y = final_df['y']
train_idx, test_idx,_,_ = train_test_split(X.index,y,test_size=0.2,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,random_state=123)
df_train = final_df[final_df.index.isin(train_idx)]
df_test = final_df[final_df.index.isin(test_idx)]
df_val = final_df[final_df.index.isin(val_idx)]
En caso de que estemos tratando con un problema de clasificación y las clases no estén balanceadas, es mejor configurar el argumento stratify para asegurarnos de que haya la misma proporción de clases en los conjuntos de entrenamiento, validación y prueba.
train_idx, test_idx,y_train,_ = train_test_split(X.index,y,test_size=0.2,stratify=y,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,stratify=y_train,random_state=123)
Esta validación cruzada estratificada también ayuda a garantizar que haya el mismo porcentaje de la variable objetivo en los tres subconjuntos y proporciona un rendimiento más preciso del modelo.
Paso 6: Escalado de características
Hay modelos de aprendizaje automático, como Regresión Lineal, Regresión Logística, KNN, Máquina de Vectores de Soporte y Redes Neuronales, que requieren el escalado de características. El escalado de características solo ayuda a que las variables estén en el mismo rango, sin cambiar la distribución.
Las tres técnicas de escalado de características más populares son Normalización, Estandarización y Escalado robusto.
La normalización, también llamada escalado min-max, consiste en asignar el valor de una variable a un rango entre 0 y 1. Esto es posible restando el mínimo de la característica del valor de la característica y, luego, dividiendo por la diferencia entre el máximo y el mínimo de esa característica.
from sklearn.preprocessing import MinMaxScaler
sc=MinMaxScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
Otro enfoque común es la estandarización, que reescala los valores de una columna respetando las propiedades de una distribución normal estándar, que se caracteriza por una media igual a 0 y una varianza igual a 1.
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
Si la característica contiene valores atípicos que no se pueden eliminar, un método preferible es el escalado robusto, que reescala los valores de una característica en función de estadísticas robustas, como la mediana, el primer y el tercer cuartil. El valor reescalado se obtiene restando la mediana del valor original y, luego, dividiendo por el rango intercuartílico, que es la diferencia entre el cuartil 75 y el cuartil 25 de la característica.
from sklearn.preprocessing import RobustScaler
sc=RobustScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
En general, es preferible calcular las estadísticas basadas en el conjunto de entrenamiento y luego usarlas para reescalar los valores tanto en los conjuntos de entrenamiento, validación y prueba. Esto se debe a que suponemos que solo tenemos los datos de entrenamiento y, más tarde, queremos probar nuestro modelo en datos nuevos, que deberían tener una distribución similar al conjunto de entrenamiento.
Paso 7: Tratar con datos desequilibrados
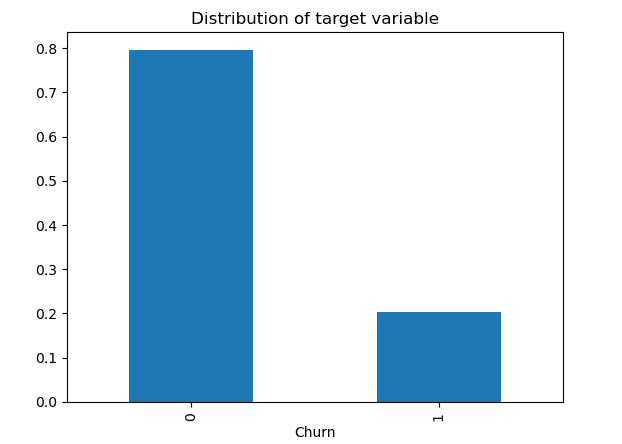
Este paso solo se incluye cuando estamos trabajando en un problema de clasificación y hemos descubierto que las clases están desbalanceadas.
En caso de que haya una pequeña diferencia entre las clases, por ejemplo, la clase 1 contiene el 40% de las observaciones y la clase 2 contiene el 60% restante, no es necesario aplicar técnicas de sobremuestreo o submuestreo para alterar el número de muestras en una de las clases. Simplemente podemos evitar mirar la precisión ya que es una buena medida solo cuando el conjunto de datos está balanceado y solo debemos preocuparnos por las medidas de evaluación, como la precisión, la recuperación y la puntuación F1.
Pero puede suceder que la clase positiva tenga una proporción muy baja de puntos de datos (0.2) en comparación con la clase negativa (0.8). El aprendizaje automático puede no funcionar bien con la clase con menos observaciones, lo que lleva a no resolver la tarea.
Para superar este problema, existen dos posibilidades: submuestrear la clase mayoritaria y sobremuestrear la clase minoritaria. La submuestreo consiste en reducir el número de muestras eliminando aleatoriamente algunos puntos de datos de la clase mayoritaria, mientras que el sobremuestreo aumenta el número de observaciones en la clase minoritaria agregando aleatoriamente puntos de datos de la clase menos frecuente. Existe el paquete imblearn que permite equilibrar el conjunto de datos con pocas líneas de código:
# submuestreo
from imblearn.over_sampling import RandomUnderSampler,RandomOverSampler
undersample = RandomUnderSampler(sampling_strategy='majority')
X_train, y_train = undersample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
# sobremuestreo
oversample = RandomOverSampler(sampling_strategy='minority')
X_train, y_train = oversample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
Sin embargo, eliminar o duplicar algunas de las observaciones puede ser ineficaz a veces para mejorar el rendimiento del modelo. Sería mejor crear nuevos puntos de datos artificiales en la clase minoritaria. Una técnica propuesta para resolver este problema es SMOTE, que se conoce por generar registros sintéticos en la clase menos representada. Al igual que KNN, la idea es identificar los k vecinos más cercanos de las observaciones que pertenecen a la clase minoritaria, basado en una distancia particular, como t. Luego, se genera un nuevo punto en una ubicación aleatoria entre estos k vecinos más cercanos. Este proceso seguirá creando nuevos puntos hasta que el conjunto de datos esté completamente balanceado.
from imblearn.over_sampling import SMOTE
resampler = SMOTE(random_state=123)
X_train, y_train = resampler.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
Debo destacar que estos enfoques deben aplicarse solo para remuestrear el conjunto de entrenamiento. Queremos que nuestro modelo de aprendizaje automático aprenda de manera robusta y, luego, podemos aplicarlo para hacer predicciones sobre nuevos datos.
Conclusiones
Espero que hayas encontrado útil este tutorial completo. Puede ser difícil comenzar nuestro primer proyecto de ciencia de datos sin conocer todas estas técnicas. Puedes encontrar todo mi código aquí.
Seguramente hay otros métodos que no cubrí en el artículo, pero preferí centrarme en los más populares y conocidos. ¿Tienes otras sugerencias? Déjalas en los comentarios si tienes sugerencias interesantes.
Recursos útiles:
- Una guía práctica para el análisis exploratorio de datos
- ¿Qué modelos requieren datos normalizados?
- Sobremuestreo y submuestreo aleatorio para clasificación desbalanceada
Eugenia Anello actualmente es investigadora en el Departamento de Ingeniería de la Información de la Universidad de Padua, Italia. Su proyecto de investigación se centra en el aprendizaje continuo combinado con la detección de anomalías.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Herramientas principales de análisis predictivo para ventas y marketing (2023)
- Una guía paso a paso para construir una estrategia efectiva de calidad de datos desde cero
- ¿Qué tan malo es ser codicioso?
- Cómo construí un lenguaje de programación El camino (difícil) hacia el éxito
- Reconocimiento de Emociones en el Borde Mejorando la Interacción entre Humanos y Máquinas a través del Análisis de Habla en Tiempo Real
- Dominando Monte Carlo Cómo simular tu camino hacia mejores modelos de aprendizaje automático
- Registro KYC ahora hecho fácil usando IA






