4 Funciones de Pandas para la comparación elemento a elemento de DataFrames
4 Pandas Functions for Element-Wise Comparison of DataFrames.
Explicado con ejemplos.

Los DataFrames de Pandas son estructuras de datos bidimensionales con filas y columnas etiquetadas.
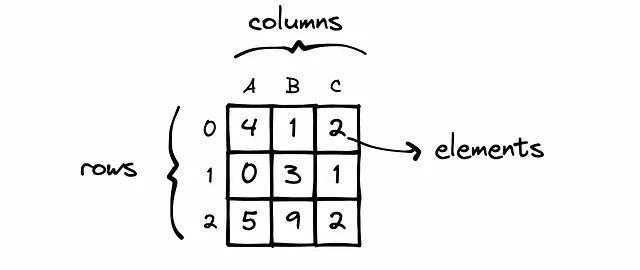
A veces, necesitamos realizar una comparación elemento a elemento de dos DataFrames. Por ejemplo:
- Actualizar valores en un DataFrame utilizando los valores de otro.
- Comparar valores y elegir el valor más grande o más pequeño.
En este artículo, aprenderemos cuatro funciones diferentes de Pandas que se pueden utilizar para tales tareas. También haremos ejemplos para entender mejor las diferencias y similitudes entre ellas.
Primero, creemos dos DataFrames que se utilizarán en los ejemplos.
- Una guía completa para empezar su propio Homelab para análisis de datos.
- Motivando la Autoatención
- 10 hiperparámetros confusos de XGBoost y cómo ajustarlos como un profesional en 2023.
import numpy as npimport pandas as pd# crear DataFrames con enteros aleatoriosdf1 = pd.DataFrame(np.random.randint(0, 10, size=(4, 4)), columns=list("ABCD"))df2 = pd.DataFrame(np.random.randint(0, 10, size=(4, 4)), columns=list("ABCD"))# agregar un par de valores faltantesdf1.iloc[2, 3] = np.nandf1.iloc[1, 2] = np.nan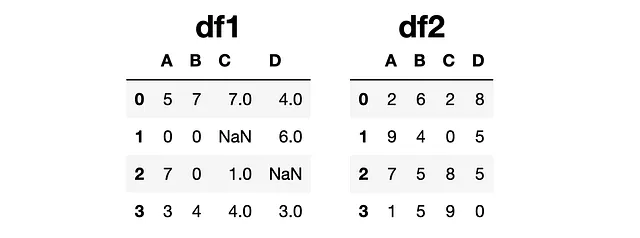
1. combine
La función combine realiza una comparación elemento a elemento basada en la función dada.
Por ejemplo, podemos seleccionar el valor máximo de dos valores para cada posición. Será más claro cuando hagamos el ejemplo.
combined_df = df1.combine(df2, np.maximum)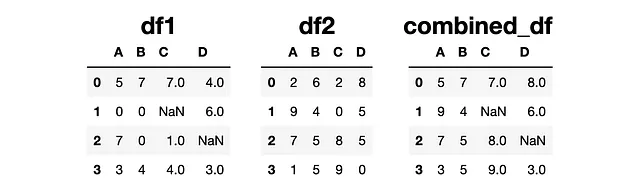
Observa el valor en la primera fila y primera columna. El DataFrame combinado tiene el más grande de 5 y 2.
Si uno de los valores es NaN (es decir, valor faltante), el DataFrame combinado en esta posición también tiene NaN porque Pandas no puede comparar un valor con un valor faltante.
Podemos elegir un valor constante que se utilizará en caso de valores faltantes utilizando el parámetro fill_value. Los valores faltantes se rellenan con este valor antes de compararlos con los valores en el otro DataFrame.
combined_df = df1.combine(df2, np.maximum, fill_value=0)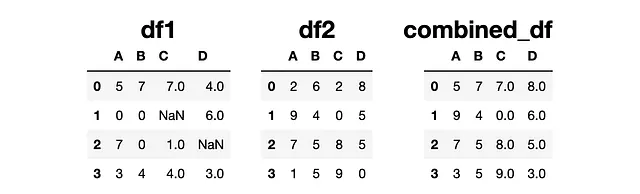
Hay dos valores NaN en df1, que se llenan con 0 y luego se comparan con los valores en la misma posición de df2.
2. combine_first
La función combine_first actualiza los valores NaN con los valores en la misma posición del otro DataFrame.
combined_df = df1.combine_first(df2)
Como se ve en la captura de pantalla anterior, combined_df tiene los mismos valores que df1 excepto por los valores NaN, los cuales son llenados con valores de df2.
Es importante tener en cuenta que la función combine_first no actualiza los valores en df1 y df2. Solo devuelve una versión actualizada del primer DataFrame.
3. Actualizar
La función update actualiza el valor faltante en un DataFrame utilizando los valores en la misma ubicación de otro DataFrame.
Esto suena igual que lo que hace la función combine_first. Sin embargo, hay una diferencia importante.
La función update no devuelve nada pero actualiza en su lugar. Por lo tanto, el DataFrame original se modifica (o se actualiza). Será más claro con un ejemplo.
Tenemos dos DataFrames como se muestra a continuación:
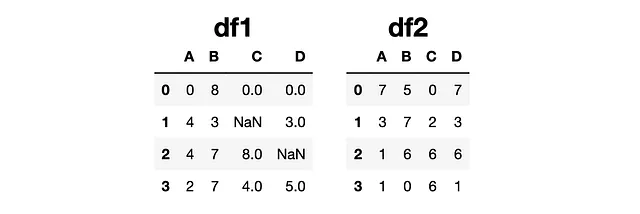
Usemos la función update en df1.
df1.update(df2)Esta línea de código no devuelve nada pero actualiza df1. La versión actualizada es:

df1 ya no incluye valores faltantes, los cuales han sido actualizados usando los valores de df2.
4. Comparar
La función compare compara los valores en la misma ubicación y devuelve un DataFrame que los muestra lado a lado.
comparison = df1.compare(df2)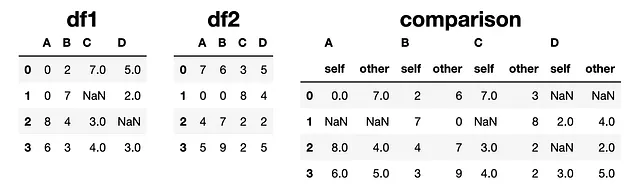
Si los valores en una ubicación particular son los mismos, la comparación los muestra como NaN (por ejemplo, segunda fila, primera columna). Podemos cambiar este comportamiento utilizando el parámetro keep_equal.
comparison = df1.compare(df2, keep_equal=True)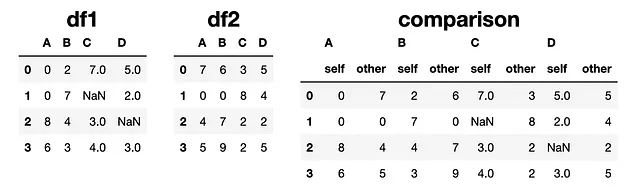
Conclusión
Aprendimos cuatro funciones de Pandas diferentes que realizan una comparación elemento por elemento de los valores en dos DataFrames. Todas tienen diferentes propósitos. Algunas se utilizan para actualizar valores, mientras que otras solo hacen una comparación.
Habrá casos en los que sea apropiado utilizar una función en particular de estas. Por lo tanto, es mejor conocerlas todas.
Puede convertirse en miembro de Zepes para desbloquear el acceso completo a mis escritos, además del resto de Zepes. Si ya lo es, no olvide suscribirse si desea recibir un correo electrónico cada vez que publique un nuevo artículo.
Gracias por leer. Por favor, háganme saber si tienen algún comentario.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cinco fuentes de datos meteorológicos gratuitas y confiables.
- Lo que aprendí al llevar la Ingeniería de Prompt al límite
- Los modelos de lenguaje grandes tienen sesgos. ¿Puede la lógica ayudar a salvarlos?
- Aprendiendo a hacer crecer modelos de aprendizaje automático
- Uniéndose a la lucha contra el sesgo en la atención médica
- Los investigadores del MIT hacen que los modelos de lenguaje sean autoaprendices escalables.
- La IA se está comiendo la Ciencia de Datos.





