4-bit Cuantización con GPTQ
4-bit Cuantización GPTQ
Quantiza tus propios LLM utilizando AutoGPTQ
Los avances recientes en la cuantización de pesos nos permiten ejecutar modelos de lenguaje grandes masivos en hardware de consumo, como un modelo LLaMA-30B en una GPU RTX 3090. Esto es posible gracias a nuevas técnicas de cuantización de 4 bits con una degradación mínima del rendimiento, como GPTQ, GGML y NF4.
En el artículo anterior, presentamos técnicas de cuantización ingenuas de 8 bits y la excelente función LLM.int8(). En este artículo, exploraremos el popular algoritmo GPTQ para comprender cómo funciona e implementarlo utilizando la biblioteca AutoGPTQ.
Puedes encontrar el código en Google Colab y GitHub.
🧠 Cuantización óptima del cerebro
Comencemos presentando el problema que estamos tratando de resolver. Para cada capa ℓ en la red, queremos encontrar una versión cuantizada Ŵₗ de los pesos originales Wₗ. Esto se llama el problema de compresión por capas. Más específicamente, para minimizar la degradación del rendimiento, queremos que las salidas (ŴᵨXᵨ) de estos nuevos pesos sean lo más cercanas posible a las originales (WᵨXᵨ). En otras palabras, queremos encontrar:
- Formas fascinantes en las que la IA está ayudando a las personas a dominar el alemán y otros idiomas
- Transforma tu proyecto de Ciencia de Datos Descubre los beneficios de almacenar variables en un archivo YAML
- Desbloqueando el potencial del texto Un vistazo más cercano a los métodos de limpieza de texto previo a la incrustación
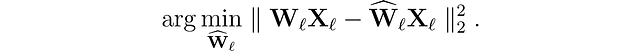
Se han propuesto diferentes enfoques para resolver este problema, pero aquí nos interesa el marco del Cuantizador Óptimo del Cerebro (OBQ).
Este método está inspirado en una técnica de poda para eliminar cuidadosamente pesos de una red neuronal densa completamente entrenada (Optimal Brain Surgeon). Utiliza una técnica de aproximación y proporciona fórmulas explícitas para el mejor peso individual w𐞥 a eliminar y la actualización óptima δꟳ para ajustar el conjunto de pesos no cuantizados restantes F para compensar la eliminación:
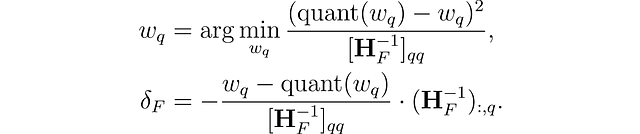
donde quant(w) es el redondeo de peso dado por la cuantización y Hꟳ es el Hessiano.
Usando OBQ, podemos cuantizar el peso más fácil primero y luego ajustar todos los pesos no cuantizados restantes para compensar esta pérdida de precisión. Luego seleccionamos el siguiente peso a cuantizar, y así sucesivamente.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce a los razonadores RAP y LLM Dos marcos basados en conceptos similares para el razonamiento avanzado con LLMs
- Keras 3.0 Todo lo que necesitas saber
- La IA y los implantes cerebrales restauran el movimiento y la sensación para un hombre paralizado
- Aceptando la IA para el Desarrollo de Software Estrategias de Solución e Implementación
- Top 40 Herramientas de IA Generativa 2023
- Investigadores de UC Berkeley presentan Nerfstudio un marco de trabajo en Python para el desarrollo de Neural Radiance Field (NeRF)
- Adopción empresarial de la IA generativa






