30 Años de Ciencia de Datos Una Revisión Desde la Perspectiva de un Profesional de la Ciencia de Datos
30 años de Ciencia de Datos Una revisión desde la perspectiva de un profesional

30 años de VoAGI y 30 años de ciencia de datos. Más o menos 30 años de mi vida profesional. Uno de los privilegios que conlleva trabajar en el mismo campo durante mucho tiempo, también conocido como experiencia, es la oportunidad de escribir sobre su evolución, como testigo ocular directo.
Los Algoritmos
- Grandes modelos de lenguaje RoBERTa – Un enfoque robustamente optimizado de BERT
- Cuantificando las Regresiones Ocultas de GPT-4 a lo largo del tiempo
- You.com lanza YouAgent un agente de IA con ejecución de código para respuestas más precisas a preguntas complejas de matemáticas y ciencias.
Comencé a trabajar a principios de los años 90 en lo que entonces se llamaba Inteligencia Artificial, refiriéndose a un nuevo paradigma que era autoaprendizaje, imitando organizaciones de células nerviosas y que no requería ninguna hipótesis estadística para ser verificada: ¡sí, redes neuronales! Un uso eficiente del algoritmo de retropropagación se había publicado solo unos años antes [1], resolviendo el problema del entrenamiento de capas ocultas en redes neuronales multicapa, lo que permitió a un ejército de estudiantes entusiastas abordar nuevas soluciones para una serie de casos de uso antiguos. Nada podía detenernos… excepto la potencia de la máquina.
Entrenar una red neuronal multicapa requiere bastante potencia computacional, especialmente si el número de parámetros de la red es alto y el conjunto de datos es grande. Sin embargo, las máquinas de la época no tenían esa potencia computacional. Se desarrollaron marcos teóricos, como Back-Propagation Through Time (BPTT) en 1988 [2] para series temporales o Long Short Term Memories (LSTM) [3] en 1997 para el aprendizaje de memoria selectiva. Sin embargo, la potencia computacional seguía siendo un problema y la mayoría de los profesionales del análisis de datos dejaron de utilizar redes neuronales, esperando tiempos mejores.
Mientras tanto, aparecieron algoritmos más livianos y a menudo igualmente efectivos. Los árboles de decisión en forma de C4.5 [4] se hicieron populares en 1993, aunque en forma de CART [5] ya existían desde 1984. Los árboles de decisión eran más fáciles de entrenar, más intuitivos de entender y a menudo tenían un rendimiento lo suficientemente bueno en los conjuntos de datos de la época. Pronto, también aprendimos a combinar muchos árboles de decisión en un bosque [6], en el algoritmo de bosque aleatorio, o en una cascada [7] [8], en el algoritmo de árboles potenciados por gradientes. Aunque esos modelos son bastante grandes, es decir, tienen un gran número de parámetros para entrenar, aún se podían manejar en un tiempo razonable. Especialmente los árboles potenciados por gradientes, con su cascada de árboles entrenados en secuencia, diluyeron la potencia computacional requerida a lo largo del tiempo, convirtiéndolo en un algoritmo muy asequible y exitoso para la ciencia de datos.
Hasta finales de los años 90, todos los conjuntos de datos eran conjuntos de datos clásicos de tamaño razonable: datos de clientes, datos de pacientes, transacciones, datos de química, etc. Básicamente, datos clásicos de operaciones comerciales. Con la expansión de las redes sociales, el comercio electrónico y las plataformas de transmisión, los datos comenzaron a crecer a un ritmo mucho más rápido, planteando desafíos completamente nuevos. En primer lugar, el desafío del almacenamiento y acceso rápido para cantidades tan grandes de datos estructurados y no estructurados. En segundo lugar, la necesidad de algoritmos más rápidos para su análisis. Las plataformas de big data se encargaron del almacenamiento y acceso rápido. Las bases de datos relacionales tradicionales que alojaban datos estructurados dejaron espacio a nuevos lagos de datos que alojan todo tipo de datos. Además, la expansión de los negocios de comercio electrónico impulsó la popularidad de los motores de recomendación. Ya sea utilizado para análisis de la cesta de mercado o para recomendaciones de transmisión de video, dos de esos algoritmos se volvieron comúnmente utilizados: el algoritmo apriori [9] y el algoritmo de filtrado colaborativo [10].
Mientras tanto, el rendimiento del hardware de computadora mejoró alcanzando una velocidad inimaginable y … volvimos a las redes neuronales. Las GPU comenzaron a utilizarse como aceleradores para la ejecución de operaciones específicas en el entrenamiento de redes neuronales, lo que permitió crear, entrenar e implementar algoritmos y arquitecturas neuronales cada vez más complejas. Esta segunda juventud de las redes neuronales adoptó el nombre de aprendizaje profundo [11] [12]. El término Inteligencia Artificial (IA) comenzó a resurgir.
Una rama secundaria del aprendizaje profundo, la IA generativa [13], se centró en generar nuevos datos: números, textos, imágenes e incluso música. Los modelos y conjuntos de datos seguían creciendo en tamaño y complejidad para lograr la generación de imágenes, textos e interacciones humanas-máquina más realistas.
Los nuevos modelos y nuevos datos fueron rápidamente sustituidos por nuevos modelos y nuevos datos en un ciclo continuo. Se convirtió cada vez más en un problema de ingeniería en lugar de un problema de ciencia de datos. Recientemente, gracias a un admirable esfuerzo en ingeniería de datos y aprendizaje automático, se han desarrollado marcos automáticos para la recopilación continua de datos, el entrenamiento de modelos, las pruebas, las acciones humanas en bucle y, finalmente, la implementación de modelos de aprendizaje automático muy grandes. Toda esta infraestructura de ingeniería es la base de los Modelos de Lenguaje Grande (LLMs) actuales, entrenados para proporcionar respuestas a una variedad de problemas mientras simulan una interacción humano a humano.
El Ciclo de Vida
Más que alrededor de los algoritmos, el mayor cambio en la ciencia de datos en los últimos años, en mi opinión, ha tenido lugar en la infraestructura subyacente: desde la adquisición frecuente de datos hasta la continua reentrenamiento y reimplantación suave de modelos. Es decir, ha habido un cambio en la ciencia de datos de una disciplina de investigación a un esfuerzo de ingeniería.
El ciclo de vida de un modelo de aprendizaje automático ha pasado de ser un único ciclo de creación pura, entrenamiento, pruebas e implementación, como CRISP-DM [14] y otros paradigmas similares, a un doble ciclo que cubre la creación por un lado y la producción – implementación, validación, consumo y mantenimiento – por el otro lado [15].
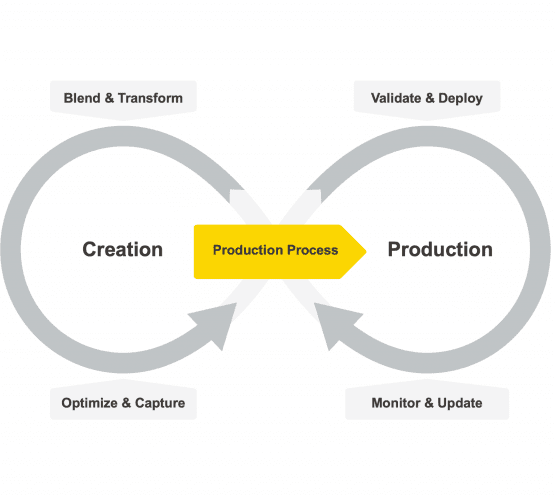
Las Herramientas
En consecuencia, las herramientas de ciencia de datos tuvieron que adaptarse. Tuvieron que comenzar a admitir no solo la fase de creación, sino también la fase de producción de un modelo de aprendizaje automático. Tenía que haber dos productos o dos partes separadas dentro del mismo producto: uno para ayudar al usuario en la creación y capacitación de un modelo de ciencia de datos y otro para permitir una producción suave y sin errores del resultado final. Mientras que la parte de creación sigue siendo un ejercicio intelectual, la parte de producción es una tarea estructurada y repetitiva.
Obviamente, para la fase de creación, los científicos de datos necesitan una plataforma con una amplia cobertura de algoritmos de aprendizaje automático, desde los básicos hasta los más avanzados y sofisticados. Nunca se sabe qué algoritmo necesitará para resolver qué problema. Por supuesto, los modelos más poderosos tienen una mayor probabilidad de éxito, lo que conlleva un mayor riesgo de sobreajuste y una ejecución más lenta. Los científicos de datos, en última instancia, son como artesanos que necesitan una caja llena de diferentes herramientas para los muchos desafíos de su trabajo.
Las plataformas basadas en código bajo también han ganado popularidad, ya que el código bajo permite a los programadores e incluso a los no programadores crear y actualizar rápidamente todo tipo de aplicaciones de ciencia de datos.
Como ejercicio intelectual, la creación de modelos de aprendizaje automático debería ser accesible para todos. Es por eso que, aunque no sea estrictamente necesario, sería deseable una plataforma de código abierto para la ciencia de datos. El código abierto permite el acceso gratuito a operaciones de datos y algoritmos de aprendizaje automático para todos los aspirantes a científicos de datos y, al mismo tiempo, permite a la comunidad investigar y contribuir al código fuente.
Por otro lado del ciclo, la producción requiere una plataforma que proporcione un marco de TI confiable para la implementación, ejecución y monitoreo de la aplicación de ciencia de datos lista para usar.
Conclusión
Resumir 30 años de evolución de la ciencia de datos en menos de 2000 palabras es, por supuesto, imposible. Además, cité las publicaciones más populares en ese momento, aunque es posible que no hayan sido las primeras absolutas sobre el tema. Me disculpo de antemano por los muchos algoritmos que desempeñaron un papel importante en este proceso y que no mencioné aquí. Sin embargo, espero que este breve resumen le brinde una comprensión más profunda de dónde y por qué estamos ahora en el campo de la ciencia de datos, ¡30 años después!
Bibliografía
[1] Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. (1986). “Aprendizaje de representaciones mediante retropropagación de errores”. Nature, 323, p. 533-536.
[2] Werbos, P.J. (1988). “Generalización de retropropagación con aplicación a un modelo de mercado de gas recurrente”. Neural Networks. 1 (4): 339-356. doi:10.1016/0893-6080(88)90007
[3] Hochreiter, S.; Schmidhuber, J. (1997). “Memoria a corto y largo plazo”. Neural Computation. 9 (8): 1735-1780.
[4] Quinlan, J. R. (1993). “C4.5: Programas para el aprendizaje automático” Morgan Kaufmann Publishers.
[5] Breiman, L. ; Friedman, J.; Stone, C.J.; Olshen, R.A. (1984) “Árboles de clasificación y regresión”, Routledge. https://doi.org/10.1201/9781315139470
[6] Ho, T.K. (1995). Bosques de decisión aleatorios. Actas de la 3ª Conferencia Internacional sobre Análisis y Reconocimiento de Documentos, Montreal, QC, 14-16 de agosto de 1995. pp. 278-282
[7] Friedman, J. H. (1999). “Aproximación de función codiciosa: una máquina de impulso de gradiente, Conferencia Reitz
[8] Mason, L .; Baxter, J .; Bartlett, P. L .; Frean, Marcus (1999). “Algoritmos de impulso como descenso de gradiente”. En S.A. Solla y T.K. Leen y K. Müller (eds.). Avances en Sistemas de Información Neural 12. Editorial MIT. pp. 512-518
[9] Agrawal, R .; Srikant, R (1994) Algoritmos rápidos para la extracción de reglas de asociación. Actas de la 20ª Conferencia Internacional sobre Bases de Datos Muy Grandes, VLDB, páginas 487-499, Santiago, Chile, septiembre de 1994.
[10] Breese, J.S .; Heckerman, D .; Kadie C. (1998) “Análisis empírico de algoritmos predictivos para filtrado colaborativo”, Actas de la Decimocuarta Conferencia sobre Incertidumbre en Inteligencia Artificial (UAI1998)
[11] Ciresan, D .; Meier, U .; Schmidhuber, J. (2012). “Redes neuronales profundas de múltiples columnas para clasificación de imágenes”. Conferencia IEEE sobre Visión por Computadora y Reconocimiento de Patrones 2012. pp. 3642-3649. arXiv:1202.2745. doi: 10.1109 / cvpr.2012.6248110. ISBN 978-1-4673-1228-8. S2CID 2161592.
[12] Krizhevsky, A .; Sutskever, I .; Hinton, G. (2012). “Clasificación de ImageNet con redes neuronales convolucionales profundas”. NIPS 2012: Sistemas de Procesamiento de Información Neural, Lake Tahoe, Nevada.
[13] Hinton, G.E .; Osindero, S .; Teh, Y.W. (2006) “Un algoritmo de aprendizaje rápido para redes de creencia profundas”. Neural Comput 2006; 18 (7): 1527-1554. doi: https://doi.org/10.1162/neco.2006.18.7.1527
[14] Wirth, R .; Jochen, H. (2000) “CRISP-DM: hacia un modelo de proceso estándar para la minería de datos”. Actas de la 4ª conferencia internacional sobre aplicaciones prácticas del descubrimiento de conocimiento y la minería de datos (4), pp. 29-39.
[15] Berthold, R.M. (2021) “Cómo llevar la ciencia de datos a la producción”, Blog KNIME. Rosaria Silipo no solo es una experta en minería de datos, aprendizaje automático, informes y almacenamiento de datos, sino que también se ha convertido en una experta reconocida en el motor de minería de datos KNIME, sobre el cual ha publicado tres libros: Suerte para principiantes de KNIME, El libro de cocina de KNIME y El folleto de KNIME para usuarios de SAS. Anteriormente, Rosaria trabajó como analista de datos independiente para muchas empresas en toda Europa. También dirigió el grupo de desarrollo de SAS en Viseca (Zúrich), implementó las interfaces de reconocimiento de voz a texto y de texto a voz en C# en Spoken Translation (Berkeley, California), y desarrolló varios motores de reconocimiento de voz en diferentes idiomas en Nuance Communications (Menlo Park, California). Rosaria obtuvo su doctorado en ingeniería biomédica en 1996 en la Universidad de Florencia, Italia.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 10 Mejores Cursos de Series Temporales para Dominar esta Importante Habilidad en Ciencia de Datos
- Construyendo una Red Neuronal Convolucional con PyTorch
- Los mejores 5 cursos de Power BI (2024)
- Esta investigación de IA propone LayoutNUWA un modelo de IA que trata la generación de diseño como una tarea de generación de código para mejorar la información semántica y aprovechar la experiencia oculta de diseño de los modelos de lenguaje grandes (LLMs).
- Diagnóstico de la enfermedad de Parkinson utilizando análisis de datos de muestras de voz selección de características
- ¿Cómo convertirse en un analista de cadena de suministro en 2023?
- No comiences tu viaje en Ciencia de Datos sin estos 5 pasos obligatorios La guía completa de un Científico de Datos de Spotify






