Diez años de revisión de la Inteligencia Artificial.
10-year review of Artificial Intelligence.
Desde la clasificación de imágenes hasta la terapia de chatbot.
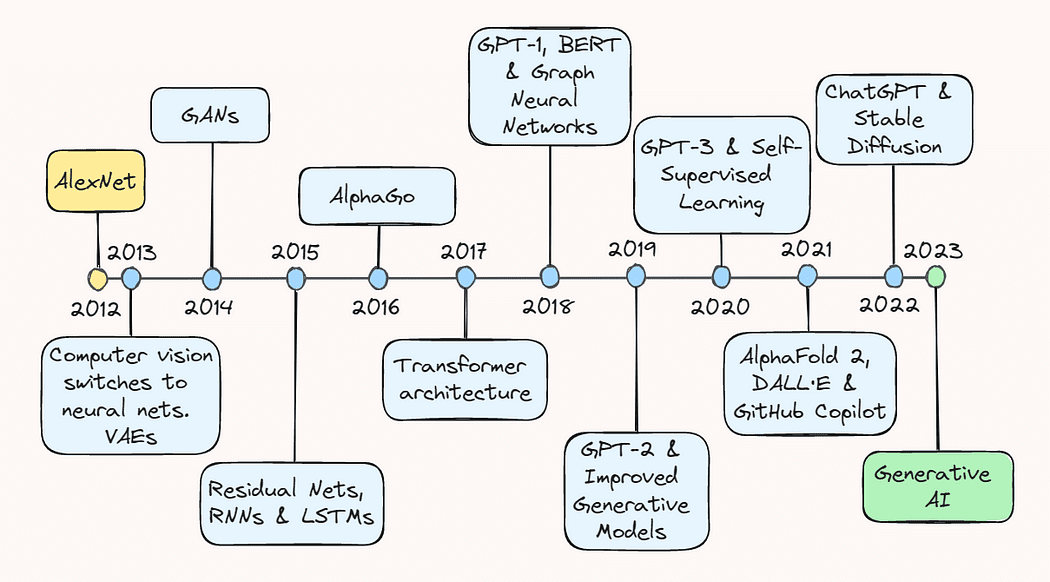
La última década ha sido emocionante y llena de sucesos para el campo de la inteligencia artificial (IA). Las modestas exploraciones del potencial del aprendizaje profundo se convirtieron en una explosiva proliferación de un campo que ahora incluye todo, desde sistemas de recomendación en comercio electrónico hasta detección de objetos para vehículos autónomos y modelos generativos que pueden crear desde imágenes realistas hasta textos coherentes.
En este artículo, daremos un paseo por el camino de la memoria y revisaremos algunos de los avances clave que nos llevaron a donde estamos hoy. Ya sea que sea un profesional experimentado de la IA o simplemente esté interesado en los últimos avances en el campo, este artículo le proporcionará una descripción general exhaustiva del notable progreso que llevó a la IA a convertirse en un nombre familiar.
- El Arte de la Ingeniería de Respuesta Rápida Decodificando ChatGPT
- Empezando con ReactPy
- Convierta ideas en música con MusicLM.
2013: AlexNet y los autoencoderes variacionales
El año 2013 es ampliamente considerado como el “advenimiento” del aprendizaje profundo, iniciado por importantes avances en la visión por computadora. Según una entrevista reciente de Geoffrey Hinton, para 2013 “prácticamente toda la investigación en visión por computadora había cambiado a redes neuronales”. Este auge fue impulsado principalmente por un avance bastante sorprendente en el reconocimiento de imágenes un año antes.
En septiembre de 2012, AlexNet, una red neuronal convolucional profunda (CNN), logró un rendimiento sin precedentes en el ImageNet Large Scale Visual Recognition Challenge (ILSVRC), demostrando el potencial del aprendizaje profundo para tareas de reconocimiento de imágenes. Logró un error de los cinco mejores del 15,3%, que fue un 10,9% menor que el de su competidor más cercano.
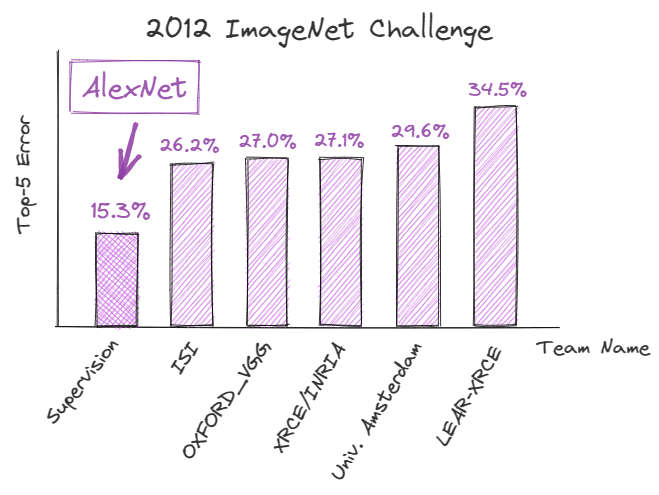
Las mejoras técnicas detrás de este éxito fueron fundamentales para la trayectoria futura de la IA y cambiaron drásticamente la forma en que se percibía el aprendizaje profundo.
En primer lugar, los autores aplicaron una CNN profunda que consistía en cinco capas convolucionales y tres capas lineales completamente conectadas, un diseño arquitectónico que muchos desestimaron como impráctico en ese momento. Además, debido al gran número de parámetros producidos por la profundidad de la red, el entrenamiento se realizó en paralelo en dos unidades de procesamiento gráfico (GPU), lo que demostró la capacidad de acelerar significativamente el entrenamiento en conjuntos de datos grandes. El tiempo de entrenamiento se redujo aún más intercambiando funciones de activación tradicionales, como la sigmoidal y la tangente hiperbólica, por la unidad lineal rectificada (ReLU), que es más eficiente.
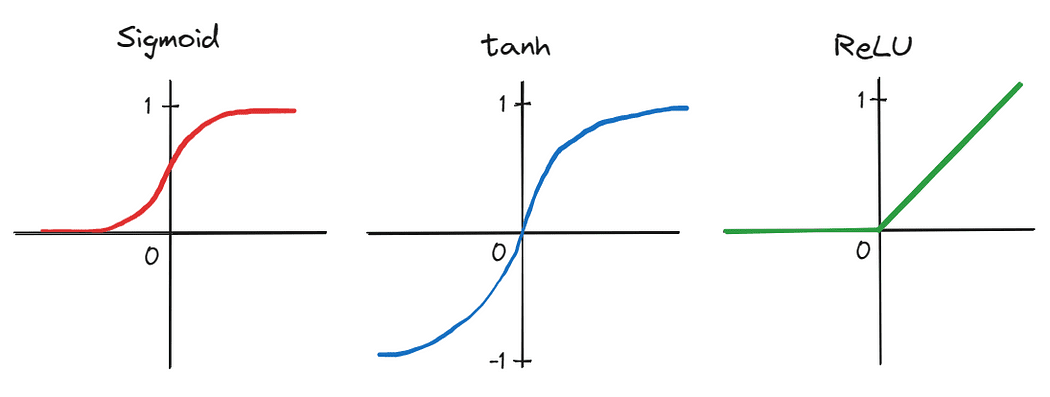
Estos avances que, en conjunto, llevaron al éxito de AlexNet, marcaron un punto de inflexión en la historia de la IA y desencadenaron un aumento del interés en el aprendizaje profundo tanto entre académicos como en la comunidad tecnológica. Como resultado, 2013 es considerado por muchos como el punto de inflexión después del cual el aprendizaje profundo realmente comenzó a despegar.
Otro suceso importante en 2013, aunque un poco ahogado por el ruido de AlexNet, fue el desarrollo de autoencoderes variacionales, o VAE, modelos generativos que pueden aprender a representar y generar datos como imágenes y sonidos. Funcionan aprendiendo una representación comprimida de los datos de entrada en un espacio de menor dimensión, conocido como espacio latente. Esto les permite generar nuevos datos muestreando desde este espacio latente aprendido. Los VAE resultaron ser más adelante nuevos caminos para la modelización generativa y la generación de datos, con aplicaciones en campos como el arte, diseño y juegos.
2014: Redes generativas adversarias
Al año siguiente, en junio de 2014, el campo del aprendizaje profundo presenció otro avance serio con la introducción de redes generativas adversarias, o GAN, por Ian Goodfellow y sus colegas.
Las GAN son un tipo de red neuronal capaz de generar nuevas muestras de datos similares a un conjunto de entrenamiento. Esencialmente, se entrenan simultáneamente dos redes: (1) una red generadora genera muestras falsas o sintéticas, y (2) una red discriminadora evalúa su autenticidad. Este entrenamiento se realiza en un entorno similar a un juego, con la red generadora tratando de crear muestras que engañen a la red discriminadora, y la red discriminadora tratando de llamar correctamente a las muestras falsas.
En ese momento, las GAN representaban una herramienta poderosa y novedosa para la generación de datos, que se utilizaban no solo para generar imágenes y videos, sino también música y arte. También contribuyeron al avance del aprendizaje no supervisado, un dominio considerado en gran medida subdesarrollado y desafiante, al demostrar la posibilidad de generar muestras de datos de alta calidad sin depender de etiquetas explícitas.
2015: ResNets y avances en NLP
En 2015, el campo de la inteligencia artificial (IA) hizo avances considerables tanto en la visión por computadora como en el procesamiento del lenguaje natural, o NLP.
Kaiming He y sus colegas publicaron un artículo titulado “Aprendizaje residual profundo para el reconocimiento de imágenes”, en el que introdujeron el concepto de redes neuronales residuales, o ResNets – arquitecturas que permiten que la información fluya más fácilmente a través de la red mediante la adición de atajos. A diferencia de una red neuronal regular, donde cada capa toma la salida de la capa anterior como entrada, en una ResNet, se agregan conexiones residuales adicionales que saltan una o más capas y se conectan directamente a capas más profundas en la red.
Como resultado, las ResNets pudieron resolver el problema de los gradientes que desaparecen, lo que permitió el entrenamiento de redes neuronales mucho más profundas de lo que se pensaba posible en ese momento. Esto, a su vez, llevó a mejoras significativas en la clasificación de imágenes y en las tareas de reconocimiento de objetos.
Alrededor del mismo tiempo, los investigadores progresaron considerablemente con el desarrollo de redes neuronales recurrentes (RNN) y modelos de memoria a corto y largo plazo (LSTM). A pesar de haber estado presentes desde la década de 1990, estos modelos solo comenzaron a generar cierto entusiasmo alrededor de 2015, principalmente debido a factores como (1) la disponibilidad de conjuntos de datos más grandes y diversos para el entrenamiento, (2) mejoras en la potencia y hardware informático, que permitieron el entrenamiento de modelos más profundos y complejos, y (3) modificaciones realizadas en el camino, como mecanismos de compuerta más sofisticados.
Como resultado, estas arquitecturas permitieron que los modelos de lenguaje comprendieran mejor el contexto y el significado del texto, lo que llevó a vastas mejoras en tareas como la traducción de idiomas, la generación de texto y el análisis de sentimientos. El éxito de RNN y LSTMs en ese momento marcó el camino para el desarrollo de los grandes modelos de lenguaje (LLMs) que vemos hoy.
2016: AlphaGo
Después de la derrota de Garry Kasparov por Deep Blue de IBM en 1997, otra batalla hombre vs. máquina sacudió el mundo de los juegos en 2016: AlphaGo de Google derrotó al campeón mundial de Go, Lee Sedol.

La derrota de Sedol marcó otro hito importante en la trayectoria del avance de la IA: demostró que las máquinas podían superar incluso a los jugadores humanos más habilidosos en un juego que alguna vez se consideró demasiado complejo para que lo manejaran las computadoras. Usando una combinación de aprendizaje profundo por refuerzo y búsqueda de árboles de Monte Carlo, AlphaGo analiza millones de posiciones de juegos anteriores y evalúa los mejores movimientos posibles, una estrategia que supera con creces la toma de decisiones humanas en este contexto.
2017: Arquitectura de transformador y modelos de lenguaje
Quizás, 2017 fue el año más decisivo que sentó las bases para los avances en IA generativa que estamos presenciando hoy.
En diciembre de 2017, Vaswani y sus colegas publicaron el artículo fundamental “La atención es todo lo que necesita”, que presentó la arquitectura de transformador que aprovecha el concepto de autoatención para procesar datos de entrada secuenciales. Esto permitió un procesamiento más eficiente de dependencias a largo plazo, que anteriormente habían sido un desafío para las arquitecturas RNN tradicionales.

Los transformadores están compuestos por dos componentes esenciales: codificadores y decodificadores. El codificador es responsable de codificar los datos de entrada, que pueden ser una secuencia de palabras, por ejemplo. Luego toma la secuencia de entrada y aplica múltiples capas de autoatención y redes neuronales de alimentación directa para capturar las relaciones y características dentro de la oración y aprender representaciones significativas.
Específicamente, la autoatención permite que el modelo comprenda las relaciones entre diferentes palabras en una oración. A diferencia de los modelos tradicionales, que procesarían las palabras en un orden fijo, los transformadores examinan todas las palabras a la vez. Le asignan algo llamado puntajes de atención a cada palabra según su relevancia para otras palabras en la oración.
El decodificador, por otro lado, toma la representación codificada del codificador y produce una secuencia de salida. En tareas como la traducción automática o la generación de texto, el decodificador genera la secuencia traducida en función de la entrada recibida del codificador. Similar al codificador, el decodificador también consta de múltiples capas de autoatención y redes neuronales de retroalimentación directa. Sin embargo, incluye un mecanismo de atención adicional que le permite centrarse en la salida del codificador. Esto permite que el decodificador tenga en cuenta información relevante de la secuencia de entrada mientras genera la salida.
La arquitectura de transformador se ha convertido desde entonces en un componente clave en el desarrollo de LLM y ha llevado a mejoras significativas en todo el dominio de NLP, como la traducción automática, el modelado del lenguaje y la respuesta a preguntas.
2018: GPT-1, BERT y Redes Neuronales de Grafos
Unos meses después de que Vaswani et al. publicaran su artículo fundacional, se presentó en junio de 2018 el G enerative P retrained T ransformer, o GPT-1, por OpenAI, que utilizó la arquitectura transformer para capturar eficazmente las dependencias a largo plazo en el texto. GPT-1 fue uno de los primeros modelos en demostrar la eficacia del preentrenamiento no supervisado seguido del ajuste fino en tareas específicas de procesamiento del lenguaje natural (NLP).
También aprovechando la arquitectura transformer aún bastante novedosa, Google lanzó y abrió su propio método de preentrenamiento llamado B idirectional E ncoder R epresentations from T ransformers, o BERT, a finales de 2018. A diferencia de los modelos anteriores que procesan el texto de manera unidireccional (incluyendo GPT-1), BERT considera el contexto de cada palabra en ambas direcciones simultáneamente. Para ilustrar esto, los autores proporcionan un ejemplo muy intuitivo:
… en la oración “Accedí a la cuenta bancaria”, un modelo contextual unidireccional representaría “banco” basado en “He accedido a la” pero no en “cuenta”. Sin embargo, BERT representa “banco” utilizando tanto su contexto anterior como posterior – “He accedido a la… cuenta” – comenzando desde la base de una red neuronal profunda, lo que lo hace profundamente bidireccional.
El concepto de bidireccionalidad fue tan poderoso que llevó a BERT a superar a los sistemas de NLP de última generación en una variedad de tareas de referencia.
Además de GPT-1 y BERT, las redes neuronales de grafos (GNNs) también causaron revuelo ese año. Pertenecen a una categoría de redes neuronales diseñadas específicamente para trabajar con datos de grafos. Las GNN utilizan un algoritmo de propagación de mensajes para propagar información a través de los nodos y las aristas de un grafo. Esto permite que la red aprenda la estructura y las relaciones de los datos de una manera mucho más intuitiva.
Este trabajo permitió la extracción de conocimientos más profundos de los datos y, en consecuencia, amplió el rango de problemas a los que se podía aplicar el aprendizaje profundo. Con las GNN, se hicieron posibles avances importantes en áreas como el análisis de redes sociales, los sistemas de recomendación y el descubrimiento de fármacos.
2019: GPT-2 y Modelos Generativos Mejorados
El año 2019 marcó varios avances notables en modelos generativos, en particular la introducción de GPT-2. Este modelo realmente dejó a sus competidores atrás al lograr un rendimiento de última generación en muchas tareas de NLP y, además, fue capaz de generar texto altamente realista, lo que, en retrospectiva, nos dio un adelanto de lo que estaba por venir en esta área.
Otras mejoras en este dominio incluyeron el BigGAN de DeepMind, que generó imágenes de alta calidad que eran casi indistinguibles de las imágenes reales, y el StyleGAN de NVIDIA, que permitió un mejor control sobre la apariencia de esas imágenes generadas.
En conjunto, estos avances en lo que ahora se conoce como IA generativa empujaron aún más los límites de este dominio, y…
2020: GPT-3 y Aprendizaje Auto-supervisado
…no mucho después, nació otro modelo, que se ha convertido en un nombre familiar incluso fuera de la comunidad tecnológica: GPT-3. Este modelo representó un gran salto adelante en la escala y capacidades de los modelos de lenguaje con aprendizaje profundo. Para poner las cosas en contexto, GPT-1 tenía solo 117 millones de parámetros. Ese número subió a 1.5 mil millones para GPT-2 y 175 mil millones para GPT-3.
Esta gran cantidad de espacio de parámetros permite que GPT-3 genere un texto notablemente coherente en una amplia gama de estímulos y tareas. También demostró un rendimiento impresionante en una variedad de tareas de NLP, como la completación de texto, la respuesta a preguntas e incluso la escritura creativa.
Además, GPT-3 destacó nuevamente el potencial del uso del aprendizaje auto-supervisado, que permite que los modelos se entrenen en grandes cantidades de datos no etiquetados. Esto tiene la ventaja de que estos modelos pueden adquirir una comprensión amplia del lenguaje sin necesidad de un entrenamiento específico extenso, lo que lo hace mucho más económico.
Yann LeCun twittea sobre un artículo de NYT sobre el aprendizaje auto-supervisado.
2021: AlphaFold 2, DALL·E y GitHub Copilot
Desde el plegamiento de proteínas hasta la generación de imágenes y la asistencia automatizada en la codificación, el año 2021 fue un año lleno de eventos gracias a los lanzamientos de AlphaFold 2, DALL·E y GitHub Copilot.
AlphaFold 2 fue aclamado como una solución esperada desde hace mucho tiempo para el problema del plegamiento de proteínas que lleva décadas sin resolverse. Los investigadores de DeepMind extendieron la arquitectura del transformador para crear bloques evoformer – arquitecturas que aprovechan las estrategias evolutivas para la optimización del modelo- para construir un modelo capaz de predecir la estructura 3D de una proteína basada en su secuencia de aminoácidos 1D. Este avance tiene un enorme potencial para revolucionar áreas como el descubrimiento de medicamentos, la bioingeniería, así como nuestra comprensión de los sistemas biológicos.
OpenAI también hizo noticias este año con su lanzamiento de DALL·E. Esencialmente, este modelo combina los conceptos de los modelos de lenguaje de estilo GPT y la generación de imágenes para permitir la creación de imágenes de alta calidad a partir de descripciones textuales.
Para ilustrar lo poderoso que es este modelo, considere la imagen a continuación, que fue generada con la indicación “Pintura al óleo de un mundo futurista con coches voladores”.

Por último, GitHub lanzó lo que más tarde se convertiría en el mejor amigo de todos los desarrolladores: Copilot. Esto se logró en colaboración con OpenAI, que proporcionó el modelo de lenguaje subyacente, Codex, que fue entrenado en un gran corpus de código disponible públicamente y, a su vez, aprendió a entender y generar código en varios lenguajes de programación. Los desarrolladores pueden utilizar Copilot simplemente proporcionando un comentario de código que indique el problema que están tratando de resolver, y el modelo sugerirá código para implementar la solución. Otras características incluyen la capacidad de describir el código de entrada en lenguaje natural y traducir el código entre lenguajes de programación.
2022: ChatGPT y Difusión Estable
El rápido desarrollo de la IA en la última década ha culminado en un avance revolucionario: el ChatGPT de OpenAI, un chatbot que fue lanzado al público en noviembre de 2022. La herramienta representa un logro de vanguardia en NLP, capaz de generar respuestas coherentes y contextualmente relevantes a una amplia gama de consultas e indicaciones. Además, puede participar en conversaciones, proporcionar explicaciones, ofrecer sugerencias creativas, ayudar con la resolución de problemas, escribir y explicar código, e incluso simular diferentes personalidades o estilos de escritura.

La interfaz simple e intuitiva a través de la cual se puede interactuar con el bot también estimuló un fuerte aumento en la usabilidad. Anteriormente, eran principalmente la comunidad tecnológica la que jugaba con las últimas invenciones basadas en IA. Sin embargo, en la actualidad, las herramientas de IA han penetrado en casi todos los campos profesionales, desde ingenieros de software hasta escritores, músicos y publicistas. Muchas empresas también están utilizando el modelo para automatizar servicios como el soporte al cliente, la traducción de idiomas o la respuesta a preguntas frecuentes. De hecho, la ola de automatización que estamos viendo ha reavivado algunas preocupaciones y estimulado discusiones sobre qué trabajos podrían estar en riesgo de ser automatizados.
Aunque ChatGPT estaba acaparando gran parte del protagonismo en 2022, también se realizó un avance significativo en la generación de imágenes. La difusión estable, un modelo de difusión latente de texto a imagen capaz de generar imágenes fotorrealistas a partir de descripciones de texto, fue lanzado por Stability AI.
La difusión estable es una extensión de los modelos de difusión tradicionales, que funcionan agregando iterativamente ruido a las imágenes y luego invirtiendo el proceso para recuperar los datos. Fue diseñado para acelerar este proceso al operar no directamente sobre las imágenes de entrada, sino sobre una representación de menor dimensión o espacio latente de ellas. Además, el proceso de difusión se modifica agregando la indicación de texto incrustada en el transformador del usuario a la red, lo que le permite guiar el proceso de generación de imágenes en cada iteración.
En general, el lanzamiento tanto de ChatGPT como de Difusión Estable en 2022 destacó el potencial de la IA generativa multimodal y provocó un gran impulso de desarrollo e inversión en esta área.
2023: LLMs y Bots
El año actual ha surgido sin duda como el año de LLMs y chatbots. Cada vez se están desarrollando y lanzando más modelos a un ritmo cada vez más rápido.
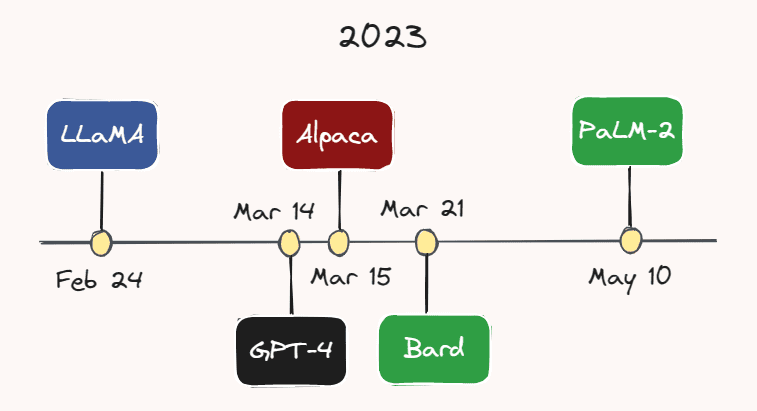 Imagen del autor.
Imagen del autor.
Por ejemplo, el 24 de febrero, Meta AI lanzó LLaMA, un LLM que supera a GPT-3 en la mayoría de los puntos de referencia, a pesar de tener un número considerablemente menor de parámetros. Menos de un mes después, el 14 de marzo, OpenAI lanzó GPT-4, una versión más grande, capaz y multimodal de GPT-3. Aunque el número exacto de parámetros de GPT-4 es desconocido, se especula que está en los billones.
El 15 de marzo, investigadores de la Universidad de Stanford lanzaron Alpaca, un modelo de lenguaje ligero que fue ajustado a partir de LLaMA en demostraciones de seguimiento de instrucciones. Un par de días después, el 21 de marzo, Google lanzó su rival ChatGPT: Bard. Google también lanzó su último LLM, PaLM-2, a principios de este mes el 10 de mayo. Con el ritmo implacable de desarrollo en esta área, es muy probable que haya surgido otro modelo para cuando esté leyendo esto.
También estamos viendo cada vez más empresas incorporando estos modelos en sus productos. Por ejemplo, Duolingo anunció su Duolingo Max con alimentación de GPT-4, un nuevo nivel de suscripción con el objetivo de proporcionar lecciones de idiomas personalizadas a cada individuo. Slack también ha lanzado un asistente impulsado por IA llamado Slack GPT, que puede hacer cosas como redactar respuestas o resumir hilos. Además, Shopify presentó un asistente impulsado por ChatGPT en la aplicación Shop de la empresa, que puede ayudar a los clientes a identificar los productos deseados utilizando una variedad de sugerencias.
Shopify anunciando su asistente impulsado por ChatGPT en Twitter.
Curiosamente, los chatbots de IA son considerados hoy en día como una alternativa a los terapeutas humanos. Por ejemplo, Replika, una aplicación de chatbot de EE. UU., ofrece a los usuarios un “compañero de IA que se preocupa, siempre aquí para escuchar y hablar, siempre de tu lado”. Su fundadora, Eugenia Kuyda, dice que la aplicación tiene una amplia variedad de clientes, desde niños autistas, que recurren a ella como una forma de “calentamiento antes de las interacciones humanas”, hasta adultos solitarios que simplemente necesitan un amigo.
Antes de concluir, me gustaría destacar lo que bien podría ser el clímax de la última década de desarrollo de IA: ¡la gente está utilizando Bing! A principios de este año, Microsoft presentó su “copiloto para la web” alimentado por GPT-4 que ha sido personalizado para la búsqueda y, por primera vez en … ¡siempre (?), ha surgido como un serio competidor para la larga dominación de Google en el negocio de la búsqueda.
Mirando hacia atrás y hacia adelante
A medida que reflexionamos sobre los últimos diez años de desarrollo de IA, se hace evidente que hemos estado presenciando una transformación que ha tenido un profundo impacto en cómo trabajamos, hacemos negocios e interactuamos entre nosotros. La mayoría del considerable progreso que se ha logrado últimamente con modelos generativos, especialmente LLM, parece adherirse a la creencia común de que “más grande es mejor”, refiriéndose al espacio de parámetros de los modelos. Esto ha sido especialmente notable con la serie GPT, que comenzó con 117 millones de parámetros (GPT-1) y, después de cada modelo sucesivo aumentando aproximadamente en un orden de magnitud, culminó en GPT-4 con potencialmente billones de parámetros.
Sin embargo, según una entrevista reciente, el CEO de OpenAI, Sam Altman, cree que hemos llegado al final de la era de “más grande es mejor”. En el futuro, aún cree que el recuento de parámetros tenderá al alza, pero el enfoque principal de las mejoras futuras del modelo será aumentar la capacidad, la utilidad y la seguridad del modelo.
Este último es de particular importancia. Teniendo en cuenta que estas potentes herramientas de IA ahora están en manos del público en general y ya no están confinadas al ambiente controlado de los laboratorios de investigación, es ahora más crítico que nunca que pisemos con cautela y aseguremos que estas herramientas sean seguras y estén alineadas con los mejores intereses de la humanidad. Esperamos ver tanto desarrollo como inversión en seguridad de IA como hemos visto en otras áreas.
PD: En caso de que haya omitido un concepto o avance central de IA que crees que debería haberse incluido en este artículo, ¡házmelo saber en los comentarios a continuación!
Thomas A Dorfer es un científico de datos y científico aplicado en Microsoft. Antes de su cargo actual, trabajó como científico de datos en la industria biotecnológica y como investigador en el dominio del neurofeedback. Tiene una maestría en Neurociencia Integrativa y, en su tiempo libre, también escribe publicaciones técnicas en Zepes sobre temas de ciencia de datos, aprendizaje automático e IA.
Original. Reposted con permiso.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Potenciando la búsqueda con inteligencia artificial generativa
- Presentando PaLM 2
- Presentamos Project Gameface un ratón de juego sin manos impulsado por inteligencia artificial.
- 100 cosas que anunciamos en I/O 2023.
- Una agenda de políticas para el progreso responsable de la inteligencia artificial Oportunidad, Responsabilidad, Seguridad.
- Casos de uso revolucionarios de IA en la industria logística
- Rastreador de Temas de GitHub | Web-Scraping con Python






