10 hiperparámetros confusos de XGBoost y cómo ajustarlos como un profesional en 2023.
10 confusing XGBoost hyperparameters and how to adjust them like a pro in 2023.
Hiperparámetros de XGBoost hechos con estilo y gráficos

Introducción
Hoy, te mostraré cómo exprimir XGBoost tanto que ambos ‘o’s salten. Lo lograremos ajustando sus hiperparámetros hasta tal punto que ya no podrá bst después de darnos todo el rendimiento que puede.
Esto no será solo una lista de verificación de hiperparámetros. Oh no. Proporcionaré una explicación detallada de cada uno de los diez hiperparámetros, funcionalidades, rangos de valores aceptados, mejores prácticas y cómo usar Optuna para la afinación de hiperparámetros.
¡Vamos a sumergirnos!
Lo que hemos buscado todo el tiempo…
Un modelo XGBoost subajustado es virtualmente desconocido. Incluso con los valores de parámetros predeterminados, funciona razonablemente bien en muchas tareas tabulares. Sin embargo, su mayor problema radica en el sobreajuste.
- Cinco fuentes de datos meteorológicos gratuitas y confiables.
- Lo que aprendí al llevar la Ingeniería de Prompt al límite
- Los modelos de lenguaje grandes tienen sesgos. ¿Puede la lógica ayudar a salvarlos?
Para abordar este problema, la mayoría de los hiperparámetros de XGBoost se colocan allí para domar a la bestia subyacente para que no solo trague el conjunto de entrenamiento y eructe los huesos durante las pruebas.
Por lo tanto, a través de la afinación de hiperparámetros, nuestro objetivo es encontrar el equilibrio óptimo entre un modelo complejo que sobreajusta y un modelo simple domado que generaliza bien a los datos invisibles.
Los siguientes parámetros son cruciales para controlar el sobreajuste:
etanum_boost_roundmax_depthsubsamplecolsample_bytreegammamin_child_weightlambdaalpha
Además de estos, exploraremos las técnicas de afinación para un par de parámetros más.
Sklearn XGBoost vs. Native XGBoost
Realmente tengo dificultades con estos dos, ya que Sklearn es mi biblioteca favorita mientras que XGBoost es mi nombre de biblioteca favorito (encaja perfectamente con bexgboost – dominio tomado).
Sin embargo, cuando consideramos hechos objetivos, la API de entrenamiento nativa de XGBoost ofrece una ligera ventaja sobre la API de Sklearn en términos de flexibilidad y acceso a funciones avanzadas y matizadas.
Acepto que la API de Scikit-learn se integra perfectamente con el ecosistema de Sklearn, incluidos los tuberías, validadores cruzados y otras funcionalidades. Pero, para el propósito de este artículo, nos centraremos en la API nativa de XGBoost.
Sin embargo, para aquellos que están decididos en la API de Sklearn, también proporcionaré los alias de hiperparámetros específicamente para esa interfaz.
El código para ajustar
En mis dos años de experiencia con XGBoost, descubrí que el código para ajustar sus hiperparámetros no es tan difícil como entender la teoría detrás de cada parámetro y elegir los rangos de ajuste apropiados para ellos.
Por lo tanto, antes de explicar cómo funciona cada hiperparámetro y su importancia, dejaré este enlace de GitHub Gist para copiar / pegar en su propio trabajo. El código ajustará cualquier modelo XGBoost con validación cruzada y devolverá los mejores parámetros. No hay necesidad de compartir el código aquí, ya que se volverá muy ilegible en dispositivos móviles.
Para aquellos que buscan comprender el código y cómo funciona Optuna en la afinación, recomiendo este artículo mío (elección altamente objetiva 🙂
¿Por qué todos en Kaggle están obsesionados con Optuna para la afinación de hiperparámetros?
Editar descripción
towardsdatascience.com
Y antes de comenzar a explicar los parámetros, también dejaré dos tablas a las que puede referirse para obtener detalles que no debe perder tiempo memorizando.
El primero contiene los alias de parámetros de Sklearn y sus rangos de ajuste recomendados:

Puede utilizar la tabla en caso de que desee utilizar un afinador distinto de Optuna.
Y esta es para la interacción entre pares individuales de parámetros:
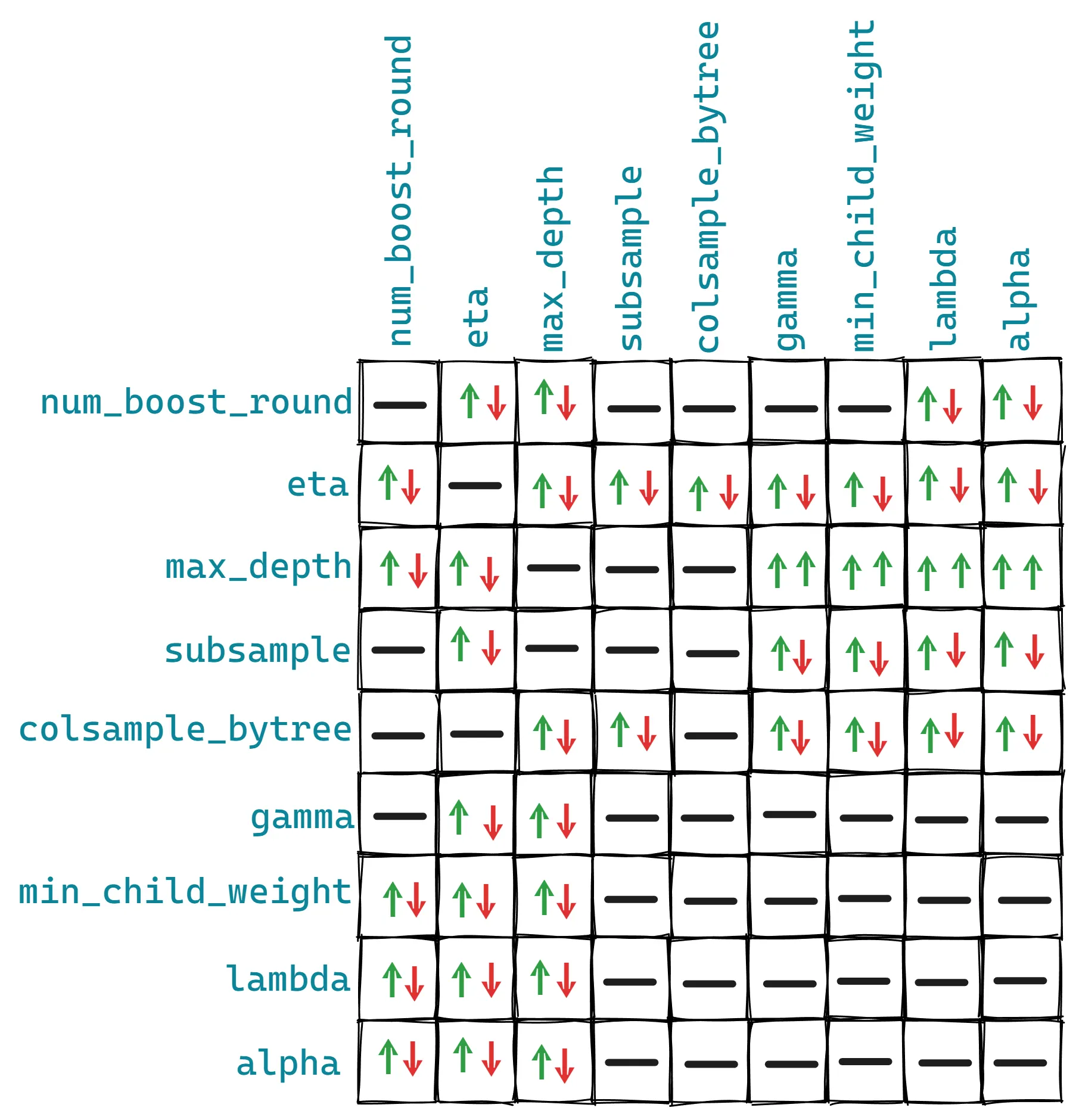
Estas relaciones no están escritas en piedra y otros parámetros podrían influir en ellas. Pero pueden dar una idea general de qué afecta a qué en XGBoost.
La historia de 10 parámetros
0. objective – Sin alias de Sklearn
Primero, tiene que determinar su camino en el bosque estableciendo un objetivo (XGBoost es un modelo de conjunto basado en árboles):
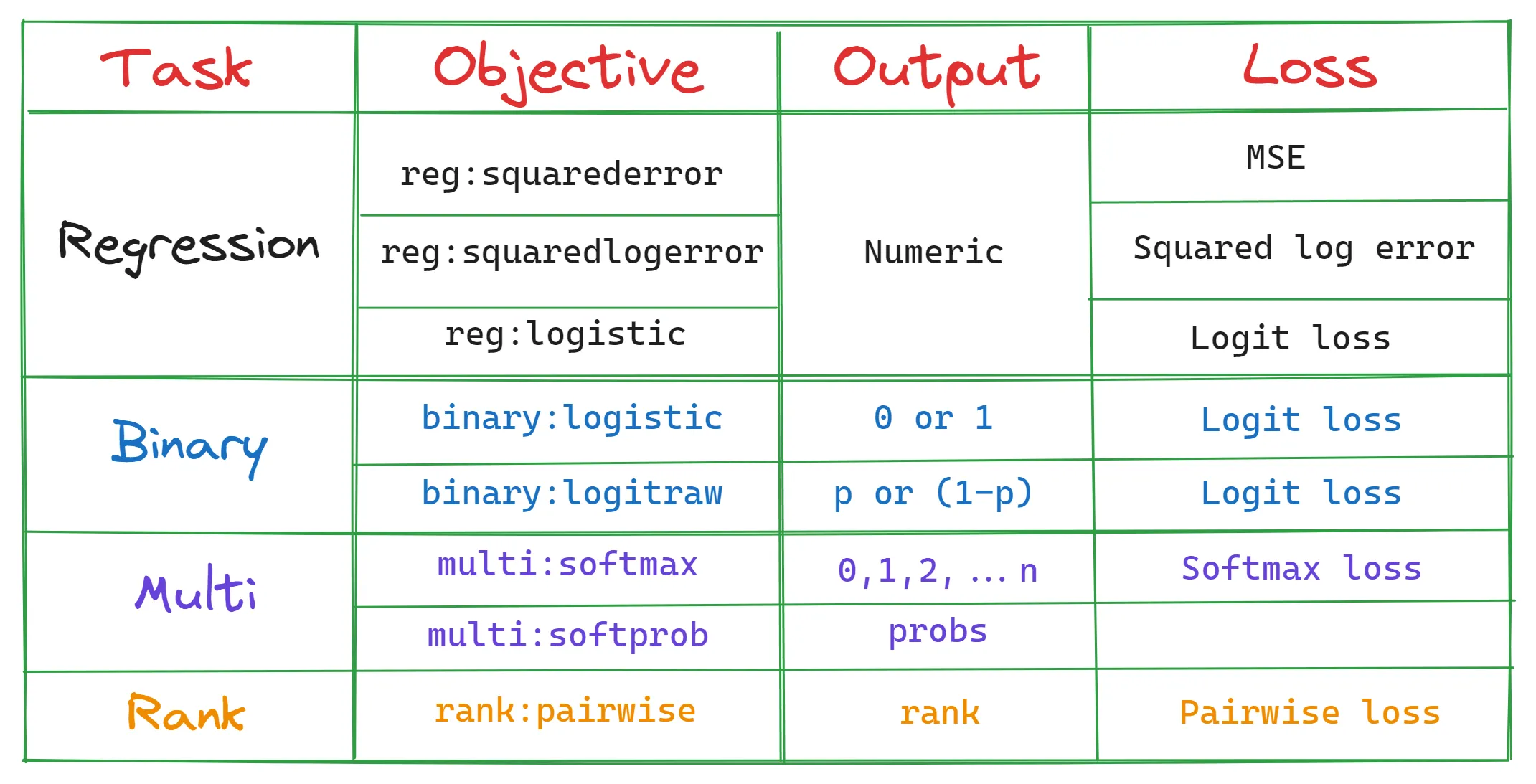
objetivo influye directamente en el tipo de árboles de decisión y la función de pérdida a usar.
1. num_boost_round – n_estimators
Luego, debe determinar el número de árboles de decisión (a menudo llamados aprendices base en XGBoost) a plantar durante el entrenamiento usando num_boost_round. El valor predeterminado es 100, pero eso es apenas suficiente para los grandes conjuntos de datos de hoy en día.
Aumentar el parámetro plantará más árboles, pero aumenta significativamente las posibilidades de sobreajuste a medida que el modelo se vuelve más complejo.
Un truco que aprendí de Kaggle es establecer un número alto como 100,000 para num_boost_round y hacer uso de paradas anticipadas.
En cada ronda de refuerzo, XGBoost planta un árbol de decisión más para mejorar la puntuación colectiva de los anteriores. Por eso se llama refuerzo. Este proceso continúa hasta num_boost_round rondas, independientemente de si cada nueva ronda es una mejora con respecto a la anterior o no.
Pero al usar la parada anticipada, podemos detener el entrenamiento y, por lo tanto, la plantación de árboles innecesarios cuando la puntuación no ha estado mejorando durante las últimas 5, 10, 50 o cualquier número arbitrario de rondas.
Con este truco, podemos encontrar el número perfecto de árboles de decisión sin siquiera ajustar num_boost_round y ahorraremos tiempo y recursos de cálculo. Así es como se vería en el código:
# Define el resto de los parámetrosparams = {...}# Construir los conjuntos de entrenamiento/validacióndtrain_final = xgb.DMatrix(X_train, label=y_train)dvalid_final = xgb.DMatrix(X_valid, label=y_valid)bst_final = xgb.train( params, dtrain_final, num_boost_round=100000 # Establecer un número alto evals=[(dvalid_final, "validación")], early_stopping_rounds=50, # Habilitar la parada anticipada verbose_eval=False,)El código anterior habría hecho que XGBoost use 100k árboles de decisión, pero debido a la parada anticipada, se detendrá cuando la puntuación de validación no haya estado mejorando durante las últimas 50 rondas. Por lo general, el número de árboles requeridos será menor a 5000-10000.
Controlar num_boost_round también es uno de los factores más importantes en cuánto tiempo se ejecuta el proceso de entrenamiento, ya que más árboles requieren más recursos.
2. eta – learning_rate
En cada ronda, todos los árboles existentes devuelven una predicción sobre la entrada dada. Por ejemplo, en la quinta ronda de refuerzo, los cinco árboles pueden devolver las siguientes predicciones para la muestra N:
- Árbol 1: 0,57
- Árbol 2: 0,9
- Árbol 3: 4,25
- Árbol 4: 6,4
- Árbol 5: 2,1
Para devolver una predicción final, estas salidas deben sumarse, pero antes de eso, XGBoost reduce o escala las mismas mediante un parámetro llamado eta o tasa de aprendizaje. Después de la escala, la salida final será:
output = eta * (0.57 + 0.9 + 4.25 + 6.4 + 2.1)Una tasa de aprendizaje alta da un peso mayor a la contribución de cada árbol del conjunto, pero esto puede llevar a un sobreajuste/inestabilidad, aunque con tiempos de entrenamiento más rápidos. En cambio, una tasa de aprendizaje baja disminuye la contribución de cada árbol, haciendo que el proceso de aprendizaje sea más lento pero más robusto.
Este efecto de regularización del parámetro de tasa de aprendizaje es especialmente útil para conjuntos de datos complejos y ruidosos.
La tasa de aprendizaje tiene una relación inversa con otros parámetros, como num_boost_round, max_depth, subsample y colsample_bytree. Una tasa de aprendizaje más baja requiere valores más altos para estos parámetros y viceversa. Pero no tienes que preocuparte por la interacción entre estos parámetros, ya que el sintonizador de hiperparámetros encontrará la mejor combinación.
3, 4. subsample y colsample_bytree
La submuestreo es una forma de bagging que introduce más aleatoriedad en el entrenamiento y, por lo tanto, ayuda a combatir el sobreajuste.
subsample=0.7 significa que cada árbol de decisión en el conjunto se entrenará con el 70% de los datos disponibles, seleccionados al azar. Un valor de 1.0 indica que se utilizarán todas las filas (sin submuestreo).
Similar a subsample, también existe colsample_bytree. Como su nombre indica, colsample_bytree controla la fracción de características que cada árbol de decisión utilizará. colsample_bytree=0.8 hace que cada árbol utilice el 80% aleatorio de las características (columnas) disponibles en cada árbol.
Ajustar estos dos parámetros permite controlar el equilibrio entre sesgo y varianza. El uso de valores más pequeños reduce la correlación entre los árboles y aumenta la diversidad en el conjunto, lo que puede ayudar a mejorar la generalización y reducir el sobreajuste.
Sin embargo, también puede introducir más ruido y aumentar el sesgo del modelo. Por el contrario, el uso de valores más grandes aumenta la correlación entre los árboles, reduciendo la diversidad y potencialmente llevando al sobreajuste.
5. max_depth
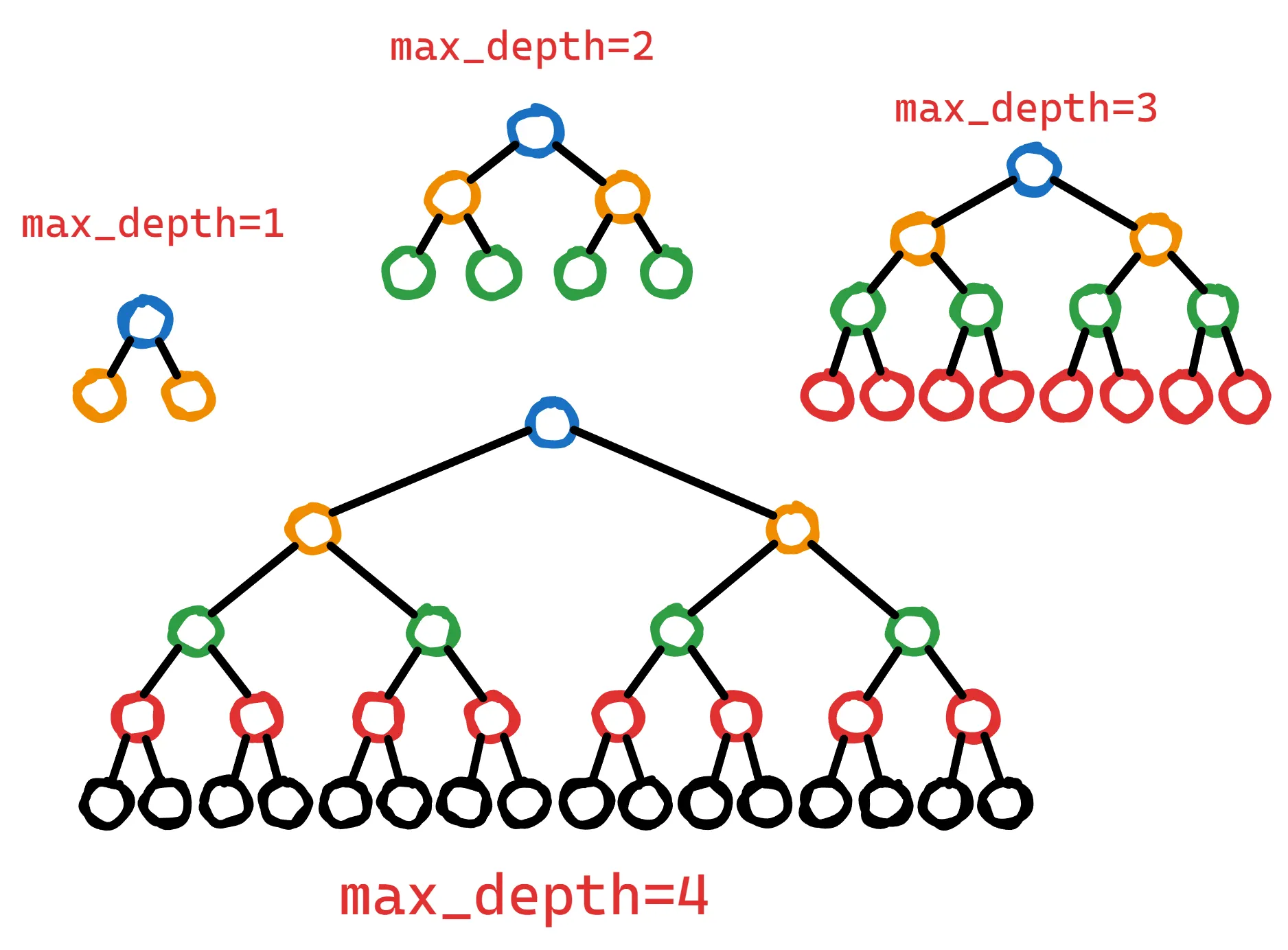
La profundidad máxima controla el número máximo de niveles que un árbol de decisión puede alcanzar durante el entrenamiento.
Los árboles más profundos pueden capturar interacciones más complejas entre características. Sin embargo, los árboles más profundos también tienen un mayor riesgo de sobreajuste, ya que pueden memorizar ruido o patrones irrelevantes en los datos de entrenamiento.
Para controlar esta complejidad, se puede limitar max_depth, lo que lleva a árboles más superficiales que son más simples y capturan patrones más generales.
max_depth es un gran equilibrador entre complejidad y generalización.
6, 7. alpha , lambda
alpha (L1) y lambda (L2) son otros dos parámetros de regularización que ayudan con el sobreajuste.
Su diferencia con otros parámetros de regularización es que pueden reducir el peso de las características no importantes o insignificantes hasta 0 (especialmente alpha), lo que lleva a un modelo con menos características y, por lo tanto, menos complejidad.
El efecto de alpha y lambda puede ser influenciado por otros parámetros como max_depth, subsample y colsample_bytree. Valores más altos de alpha o lambda pueden requerir ajustar otros parámetros para compensar el aumento de la regularización. Por ejemplo, un valor más alto de alpha puede beneficiarse de un valor más grande de subsample para mantener la diversidad del modelo y evitar el subajuste.
8. gamma
Si lees la documentación de XGBoost, dice que gamma es:
la reducción mínima de pérdida requerida para hacer una partición adicional en un nodo hoja del árbol.
Creo que la oración no tiene sentido para nadie más que para la persona que la escribió. Vamos a analizarla.
Lo siguiente es un árbol de decisión de dos niveles:
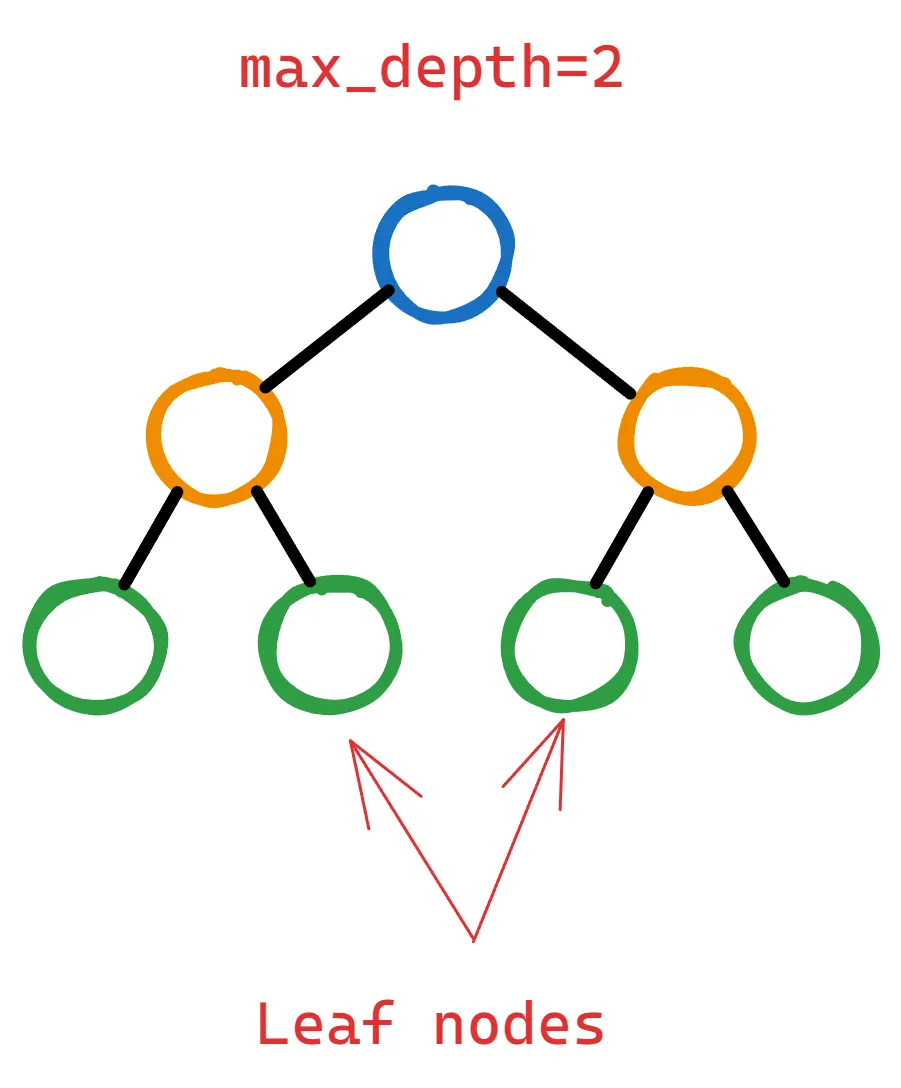
Para justificar la adición de más capas al árbol dividiendo los nodos hoja, XGBoost debe calcular que esta operación reducirá significativamente la función de pérdida.
Pero, ¿cuánto significativamente? Eso es donde establecemos gamma – actúa como un umbral para decidir si un nodo hoja debe dividirse aún más.
Si la reducción en la función de pérdida (a menudo llamada ganancia) es menor que el gamma elegido después de una posible división, entonces la división no se realiza. Esto significa que el nodo hoja permanecerá igual y el árbol no crecerá a partir de ese punto.
Por lo tanto, el objetivo de ajustar gamma es encontrar las mejores divisiones que conduzcan a la mayor reducción en la función de pérdida, lo que significa una mejora en el rendimiento del modelo.
9. min_child_weight
XGBoost comienza el proceso de entrenamiento inicial con un solo árbol de decisión con un solo nodo raíz. Ese nodo contiene todas las instancias de entrenamiento (filas) al principio.
Luego, a medida que XGBoost elige características potenciales y criterios de división que dan como resultado la mayor reducción de pérdida, los nodos más profundos contendrán cada vez menos instancias.
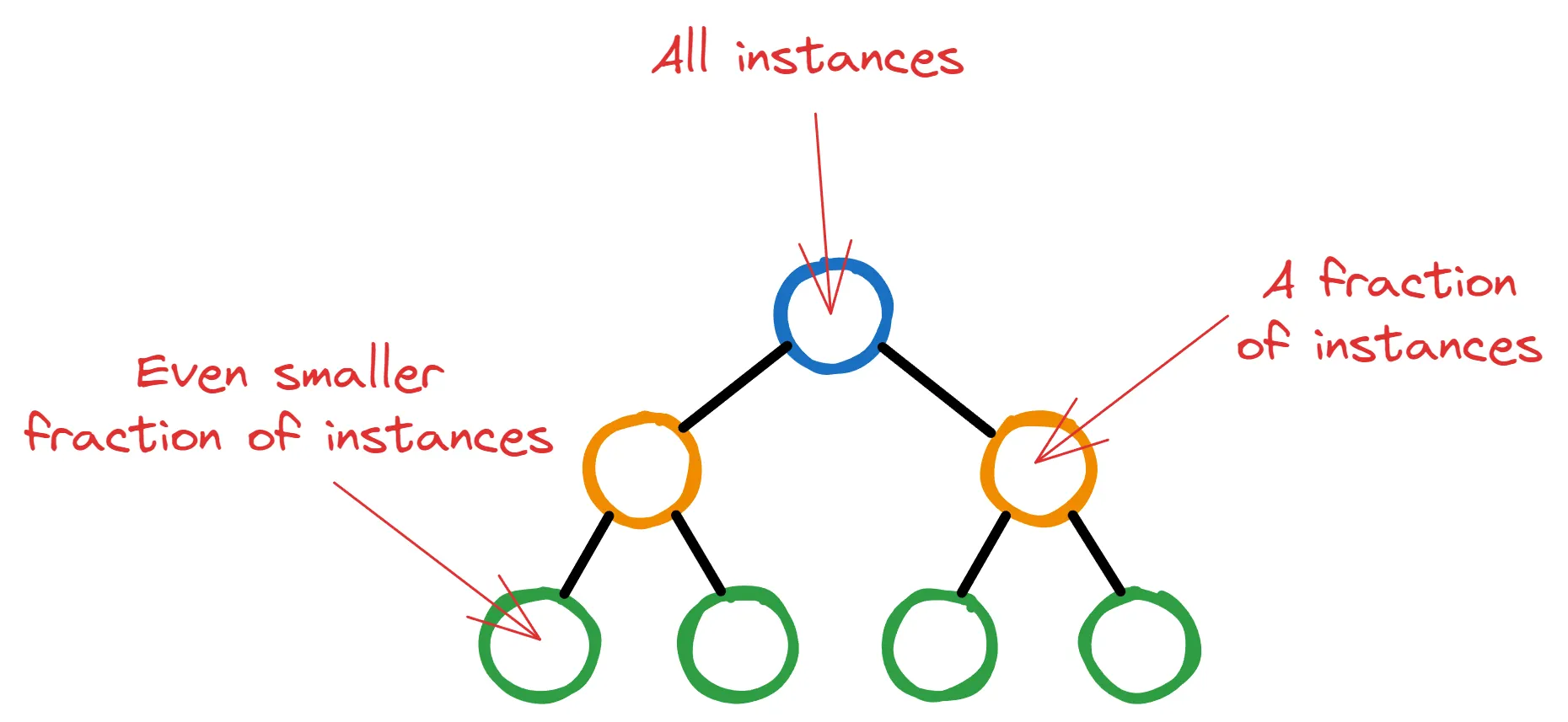
Si permites que XGBoost se descontrole, los árboles podrían crecer hasta el punto en que solo hay unas pocas instancias insignificantes en los nodos finales. Esa situación es altamente indeseable ya que es la definición misma de sobreajuste.
Es por eso que XGBoost permite a los usuarios tener un umbral para el número mínimo de instancias en cada nodo para continuar dividiendo. Para determinar esto, se ponderan todas las instancias en un nodo y se encuentran las sumas de los pesos. Luego, si este peso final es menor que min_child_weight, la división se detiene y el nodo se convierte en un nodo hoja.
Aunque esta explicación es una gran simplificación de todo el proceso, debería darle una idea general.
Conclusión
Aunque hemos cubierto mucha teoría, todavía hay mucho por aprender. Sugiero dar las siguientes dos solicitudes a ChatGPT:
1) Explicar el parámetro de XGBoost {parameter_name} en detalle y cómo elegir valores sabiamente para él.2) Describir cómo se ajusta {parameter_name} en el proceso de construcción de árboles paso a paso de XGBoost.Quiero dejar una nota final diciendo que debes emplear tanto la validación cruzada como un conjunto de pruebas finales sin procesar para probar el rendimiento del modelo después del ajuste.
Puede dividir sus datos 80/20 y ajustar XGBoost en el 80% con 5-7 fold CV y una vez que se encuentran los mejores parámetros, medir el rendimiento una última vez en el 20% sin procesar. Esto asegura que los resultados que obtenga sean lo más robustos posible.
No olvide el código GitHub gist para usar en el ajuste. ¡Gracias por leer!
¿Te encantó este artículo y, enfrentémoslo, su estilo de escritura extraño? Imagina tener acceso a docenas más como este, todos escritos por un autor brillante, encantador e ingenioso (ese soy yo, por cierto :).
Por solo 4.99$ de membresía, tendrás acceso no solo a mis historias, sino a un tesoro de conocimientos de las mentes más brillantes y mejores en Zepes. Y si usas mi enlace de referencia, ganarás mi supernova de gratitud y un ¡chócala virtual! por apoyar mi trabajo.
Únete a Zepes con mi enlace de referencia – Bex T.
Obtén acceso exclusivo a todo mi contenido ⚡premium⚡ y todo en Zepes sin límites. Apoya mi trabajo comprándome un…
ibexorigin.medium.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aprendiendo a hacer crecer modelos de aprendizaje automático
- Uniéndose a la lucha contra el sesgo en la atención médica
- Los investigadores del MIT hacen que los modelos de lenguaje sean autoaprendices escalables.
- La IA se está comiendo la Ciencia de Datos.
- Hoja de ayuda de Bard para Ciencia de Datos
- El papel de las herramientas de código abierto en la aceleración del progreso de la ciencia de datos
- Integrando ChatGPT en los flujos de trabajo de Ciencia de Datos Consejos y Mejores Prácticas






